Speech recognition is a natural language processing task that requires identifying the language of a text or document. Using machine learning for speech recognition was a difficult task a few years ago due to the lack of much data on language, but now that data is readily available, several powerful machine learning models are already available. So, if you want to learn how to train machine learning models for speech recognition, this article is for you. This article describes a machine learning speech recognition task using Python.
As humans, we can easily recognize the languages we know. For example, I can easily recognize Hindi and English, but as an Indian I cannot recognize all Indian languages. Here you can use speech recognition tasks. Google Translate is he one of the most popular language translators in the world, used by so many people around the world. It also includes a machine learning model for language recognition, which you can use if you don’t know the language you want to translate.
The most important part of training a speech recognition model is the data. The more data for each language, the better the real-time accuracy of the model. The dataset I’m using was collected by Kaggle and contains data on 22 common languages, 1000 sentences in each language, and a machine learning speech recognition model. It’s a good dataset to train on. Therefore, in the next section, we’ll discuss how to use Python to train a machine learning speech recognition model.
Dataset for this project can be download from here
Let’s start the task of language detection with machine learning by importing the necessary Python libraries and the dataset:


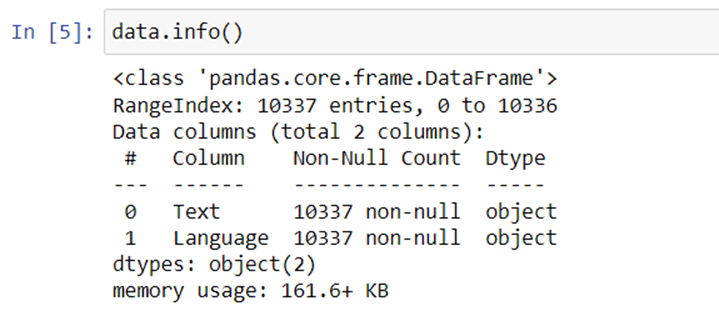
Let’s get some information about our dataset
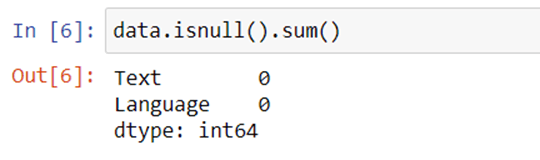
Let’s check whether this dataset have any null values or not:
Now let’s have a look at all the languages present in this dataset:
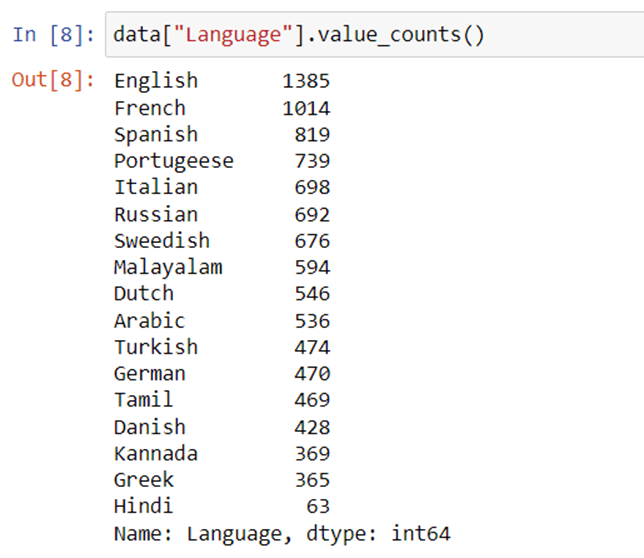
This dataset contains 22 languages with 1000 sentences from each language. Since this is a highly balanced dataset with no missing values, we can say that this dataset is perfectly ready to be used for training machine learning models.
Now we will split the data into training and test sets:

Since this is a multiclass classification problem, we train a speech recognition model using the Multinomial Naive Bayes algorithm.
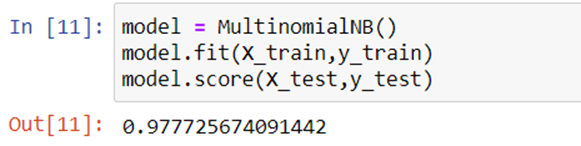
Now let’s use this model to detect the language of a text by taking a user input:

As you can see the model works well. Note that this model can only recognize languages listed in the dataset.
Summary
Using machine learning for speech recognition was a difficult task a few years ago because there was not much data on languages, but now that data are readily available, several techniques for speech recognition are emerging. of powerful machine learning models are already available. I hope you enjoyed this article on Machine Learning Language Recognition with Python.
