Latest Articles

Loop Engineering Explained: From Prompt Engineering to Self-Prompting AI Agents
Every few months, the AI world gives us a new word. First it was prompt engineering. Then context engineering. Then...
Read More →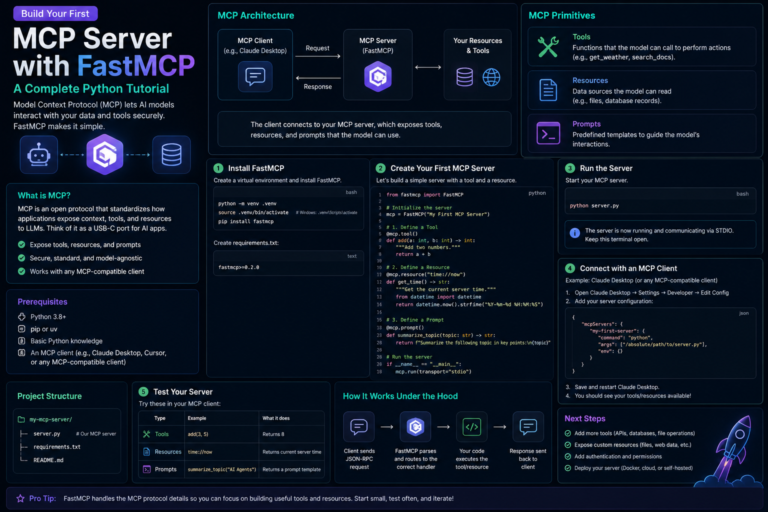
Build Your First MCP Server with FastMCP: A Complete Python Tutorial
AI has come a long way from providing straightforward answers. Modern applications of AI can scan documents, search databases, interact...
Read More →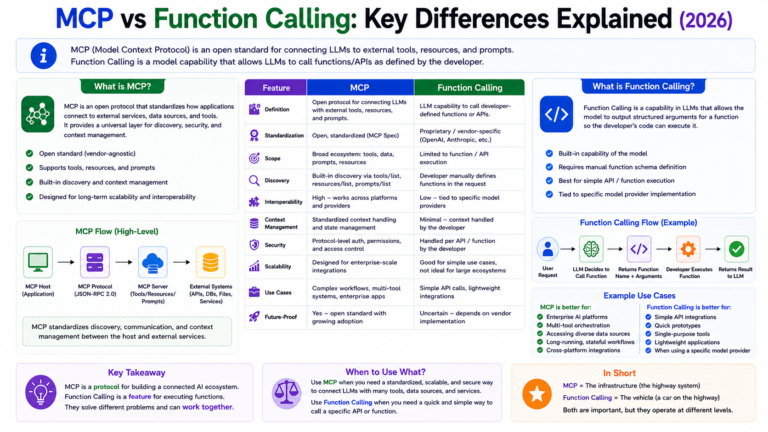
MCP vs Function Calling: Key Differences Explained (2026)
If you have built something with a Large Language Model API in the two years you have probably used function...
Read More →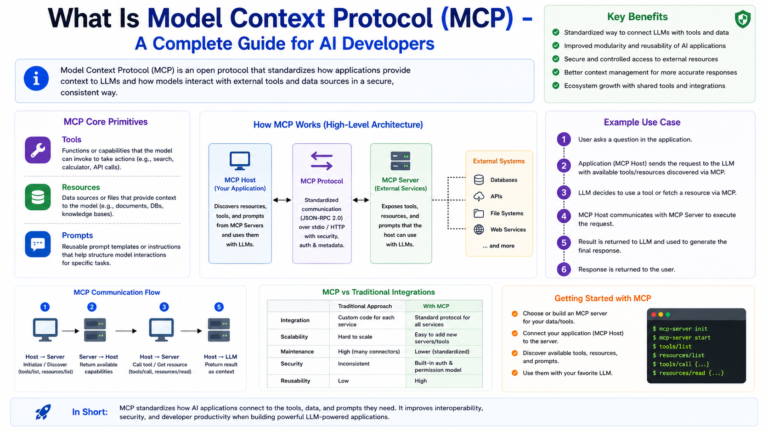
What Is Model Context Protocol (MCP) – A Complete Guide for AI Developers
AI has progressed from chatbots to AI agents over the past year, moving beyond the limited scope of basic responses.In...
Read More →
MCP Primitives Explained: Tools, Resources, and Prompts With Real Examples
If you have worked with the Model Context Protocol you might have seen a pattern. Most tutorials start by saying...
Read More →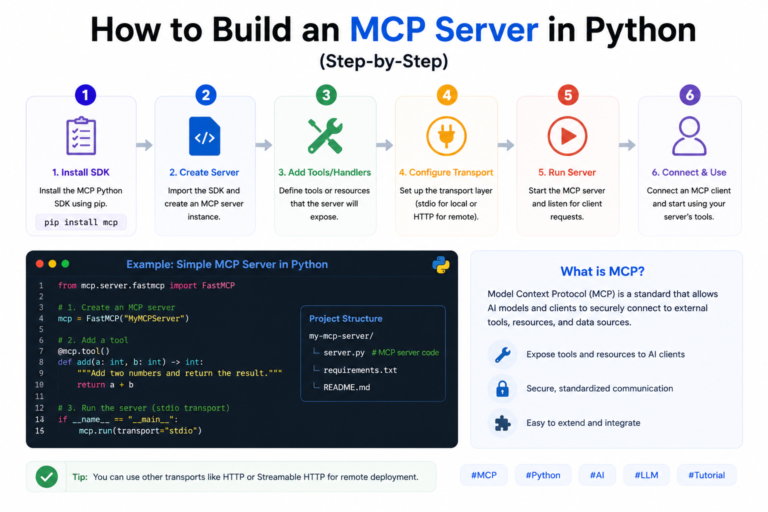
How to Build an MCP Server in Python (Step-by-Step)
By the end of this tutorial, you’ll have a working MCP server written in Python — one that exposes a...
Read More →
How to Evaluate Your AI Agent: Metrics, Tools, and Frameworks That Actually Work
Building an AI agent is only half the challenge. The real challenge is proving that it actually works. Many developers...
Read More →
The 6 Security Dangers of Autonomous AI Agents: Why Every Developer Needs to Understand Them Now
Sometime in late 2025, a developer named Peter Steinberger built an AI agent as a weekend project. He called it...
Read More →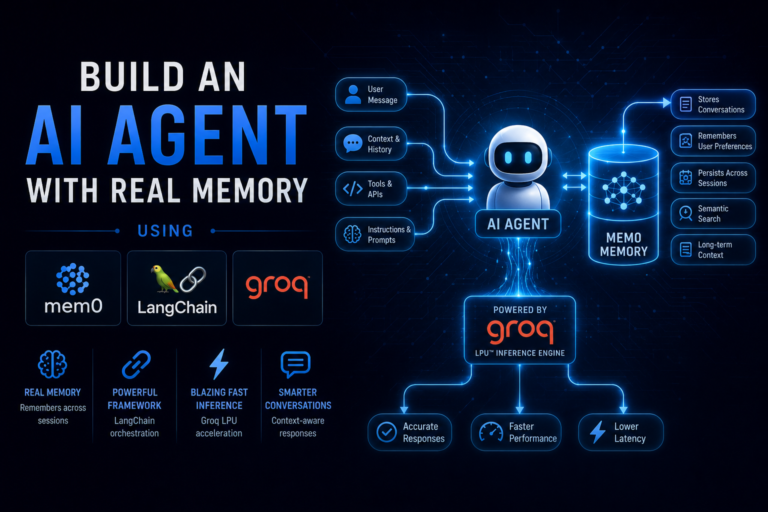
Build an AI Agent with Real Memory Using Mem0, LangChain, and Groq
Most AI agents are very forgetful. You can introduce yourself, tell them about your project, your preferences, and your goals...
Read More →
Build a Multimodal RAG System That Understands PDFs (Text + Images) Using Groq
The majority of RAG systems nowadays are not complete, they read the text but not the images, which actually describe...
Read More →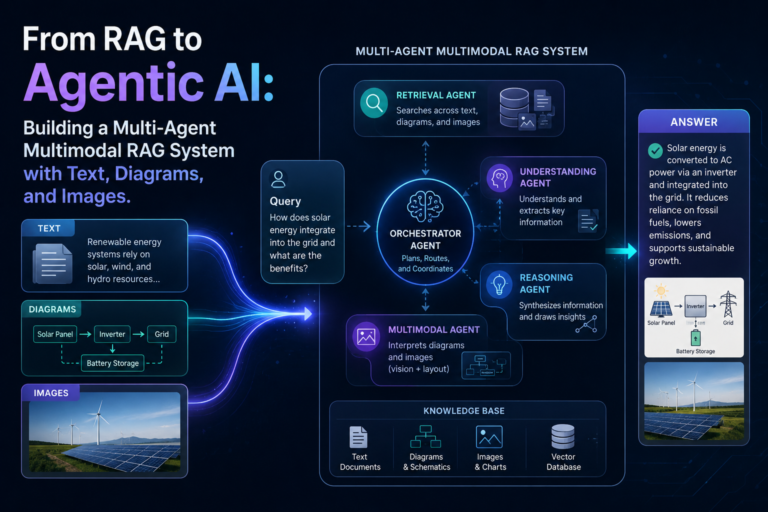
From RAG to Agentic AI: Building a Multi-Agent Multimodal RAG System with Text, Diagrams, and Images
Traditional RAG systems retrieve information. Modern AI systems decide how to respond. That shift—from retrieval to reasoning—is what defines the...
Read More →
Generative AI vs Agentic AI: What’s the Real Difference?
Generative AI is used to create, whereas Agentic AI is used to finish. Generative AI is sufficient, in case you...
Read More →