PReLU(Parametric ReLU) –
PReLU is vital to the success of deep learning. It solves the problem with activation functions like sigmoid, where gradients would often vanish. This approach is finding more and more success in deep learning environments. But, we can still improve upon ReLU. Leaky ReLU was introduced, which does not zero out the negative inputs as ReLU does. Instead, it multiplies the negative input by a small value (like 0.02) and keeps the positive input as is. This has shown a negligible increase in the accuracy of our models.
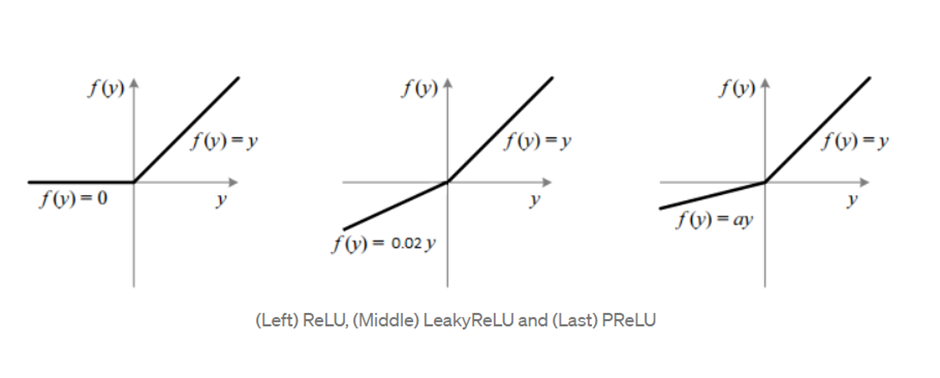
One of the disadvantages of ReLU is the fact that it might not be able to adapt well to sudden changes, because of its slope. This is where PReLU comes in – it can learn the slope parameter using backpropagation and prevents this problem.
Feed-forward networks only need to learn one slope parameter for each layer. In Convolutional Neural Networks, either the slope parameters can be learned for each layer or Compared to the number of weights & biases that need to be learned, this is relatively insignificant.
ELU(Exponential LU) –
ELU activation functions are more computationally expensive than PReLU activation functions. They have a shallower slope, which can be advantageous for certain types of networks.
Exponential Linear Units are used to increase (make closer to zero) the mean activation of each layer. An alpha constant value is an important parameter which needs to be a positive number.
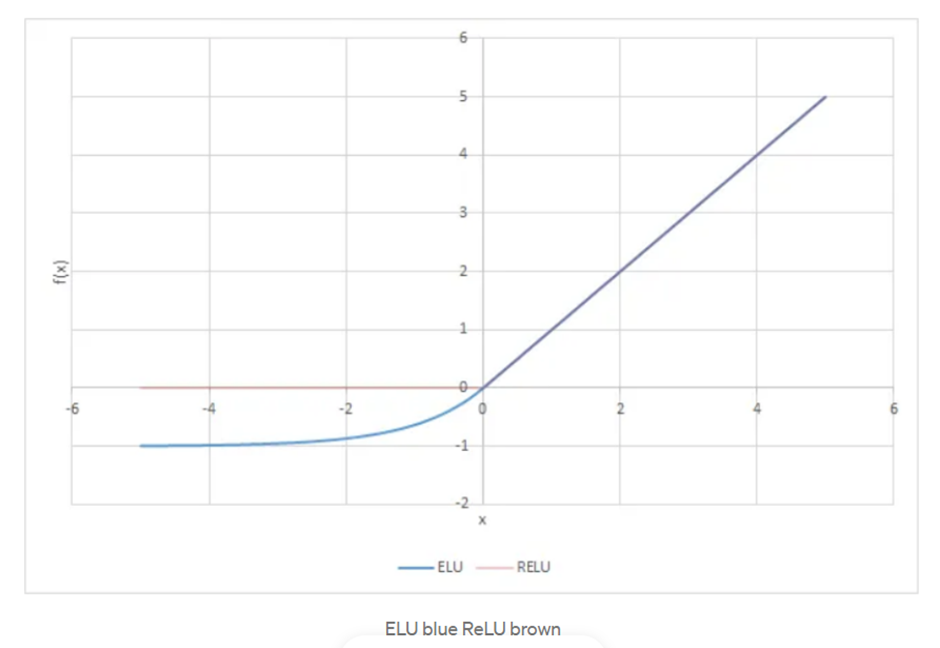
The ELU algorithm has been shown to provide more accurate results than ReLU and also converges faster. ELU and ReLU are both the same for positive input values, but for negative input values ELU smoothly “eases” down to 0.0 (i.e., -alpha) whereas ReLU sharply drops to 0.5 (-half of alpha).

Way cool! Some extremely valid points! I appreciate you penning this post
and also the rest of the website is also very good.
Thank you for your kind word
I’ve learn some excellent stuff here. Certainly worth bookmarking for revisiting.
I surprise how so much attempt you set to create such a wonderful informative website.
Thank you
As I website possessor I believe the content matter here is rattling magnificent , appreciate it for your hard work. You should keep it up forever! Best of luck.
Thanks a lot
Thank you for writing such a great article. It helped me a lot and I love the subject.
Thank you
The articles you write help me a lot and I like the topic
Thank you.
It was really helpful to read an article like this one, because it helped me learn about the topic.
Thank you Mellisa
I really enjoyed reading this article
Thank you Dania
I always find your articles very helpful. Thank you!
Thank you so much Lissa
How can I find out more about it?
on a same topic?
Thank you for writing so many excellent articles. May I request more information on the subject?
Thank you Michael. sure
Thanks for the help
Welcome Kelley
You should write more articles like this, you really helped me and I love the subject.
Thank you Herminia. will write more..
You’ve been great to me. Thank you!
You’re very welcome Gale.
Thank you for your help. I must say you’ve been really helpful to me.
You’re very welcome Frederic
Thank you for posting such a wonderful article. It helped me a lot and I adore the topic.
It’s my pleasure Allan.
Having read this I thought it was very informative. I appreciate you taking the time and effort to put this article together. I once again find myself spending way to much time both reading and commenting. But so what, it was still worth it!
Thank you so much graliotrorile
You should write more articles like this, you really helped me and I love the subject.
Thank you Danuta. will write more..
Thanks for your help and for posting this. It’s been great.
You’re very welcome Tyrell
Thanks for posting such an excellent article. It helped me a lot and I love the subject matter.
You’re very welcome Burl
I really enjoyed reading your post and it helped me a lot
Thank you Elton
Thanks for writing the article
You’re very welcome Tesha
I like the valuable info you provide for your articles. I?ll bookmark your weblog and check once more here regularly. I am somewhat sure I?ll be informed many new stuff right right here! Good luck for the following!
Simply desire to say your article is as surprising. The clarity on your publish is simply nice and that i could suppose you’re knowledgeable on this subject. Fine together with your permission let me to clutch your feed to keep up to date with approaching post. Thanks 1,000,000 and please carry on the gratifying work.
Thank you for your kind words
Definitely believe that which you stated. Your favorite justification appeared to be on the net the simplest thing to understand of. I say to you, I definitely get irked while folks think about concerns that they just do not realize about. You controlled to hit the nail upon the top and outlined out the entire thing without having side effect , folks could take a signal. Will likely be again to get more. Thanks
It is best to take part in a contest for among the finest blogs on the web. I’ll recommend this website!
Great goods from you, man. I’ve be mindful your stuff previous to and you’re simply extremely fantastic. I really like what you have acquired right here, really like what you’re saying and the way wherein you are saying it. You’re making it enjoyable and you still take care of to keep it smart. I can not wait to read much more from you. That is really a great site.
Simply want to say your article is as surprising. The clarity on your post is just spectacular and i can assume you’re an expert on this subject. Fine along with your permission allow me to grasp your RSS feed to keep updated with forthcoming post. Thank you 1,000,000 and please carry on the rewarding work.
Your articles are extremely helpful to me. Please provide more information!
Thank you Alva uploading more on this soon.
May I have further information on the topic?
Sure. uploading more on this topic soon.
Dude these articles have been great. Thank you for helping me.
Thanks Dorothea
Thank you for posting such a wonderful article. It really helped me and I love the topic.
I really enjoyed reading your post, especially because it addressed my issue. It helped me a lot and I hope it can help others too.
I really enjoyed reading your post, especially because it addressed my issue. It helped me a lot and I hope it can help others too.
Heya i am for the first time here. I came across this board and I find It really useful & it helped me out a lot. I hope to give something back and aid others like you aided me.
This is very interesting, You’re a very skilled blogger. I’ve joined your rss feed and look forward to seeking more of your fantastic post. Also, I’ve shared your site in my social networks!
I was just searching for this information for a while. After six hours of continuous Googleing, finally I got it in your web site. I wonder what is the lack of Google strategy that don’t rank this type of informative websites in top of the list. Usually the top sites are full of garbage.
I am usually to running a blog and i really recognize your content. The article has really peaks my interest. I am going to bookmark your web site and preserve checking for brand new information.
I could not refrain from commenting. Exceptionally well written!
Genuinely when someone doesn’t understand then its up to other visitors that they will
help, so here it occurs.
I used to be able to find good info from your blog articles.
I could not refrain from commenting. Exceptionally well written!
Hello my loved one! I wish to say that this article is amazing,
nice written and come with almost all vital infos. I would like to look more posts like
this .
Thanks for finally writing about > What is PReLU and ELU activation function? – Nomidl
< Loved it!
Hello, I check your new stuff regularly. Your humoristic style is awesome, keep it up!
I need to to thank you for this wonderful read!! I definitely loved every bit of it. I have got you bookmarked to look at new stuff you postÖ
I love what you guys are usually up too. This sort of clever work and coverage!
Keep up the good works guys I’ve included you guys to our blogroll.
Awesome article.
I’ve read a few just right stuff here. Definitely worth bookmarking for revisiting.
I wonder how so much attempt you place to create this
kind of wonderful informative site.
Hello there, You’ve done an excellent job.
I’ll certainly digg it and personally suggest to my friends.
I am sure they’ll be benefited from this website.
Magnificent goods from you, man. I’ve understand your stuff previous to and you’re
just too wonderful. I really like what you’ve acquired here, really like what you’re saying and the way in which you say it.
You make it enjoyable and you still take care of to keep it smart.
I cant wait to read much more from you. This is actually a great web site.
This is really interesting, You’re a very skilled blogger.
I have joined your feed and look forward to seeking more of your fantastic
post. Also, I’ve shared your web site in my social networks!
I’m amazed, I have to admit. Rarely do I come across a blog that’s both equally educative and amusing,
and let me tell you, you have hit the nail on the head.
The problem is something that not enough men and women are speaking
intelligently about. Now i’m very happy that I came across this
during my search for something regarding this.
What’s up, after reading this remarkable article
i am as well cheerful to share my know-how here with friends.
Heya i’m for the first time here. I came across this board and I find It really useful & it helped me out a lot.
I hope to give something back and aid others like you helped me.
Hi there! Would you mind if I share your blog with my facebook group?
There’s a lot of folks that I think would really appreciate your
content. Please let me know. Cheers
Please share with everyone
This is my first time go to see at here and i am truly impressed to
read everthing at alone place.
I am truly grateful to the holder of this web
page who has shared this enormous post at at this time.
Thank you
It’s difficult to find experienced people about this subject, but you sound like you know what you’re talking about!
Thanks
Everyone loves what you guys are usually up too.
This kind of clever work and coverage! Keep up
the superb works guys I’ve added you guys to my personal blogroll.
Hey! I know this is kinda off topic however I’d figured I’d ask.
Would you be interested in exchanging links or maybe guest writing a blog
article or vice-versa? My website goes over a lot of the same topics
as yours and I feel we could greatly benefit from each
other. If you happen to be interested feel free to shoot me an email.
I look forward to hearing from you! Terrific blog by the way!
what’s your email?
Pretty! This has been a really wonderful article.
Thank you for providing these details.