Breast cancer (BC) is one among the foremost common cancers among ladies worldwide, representing the bulk of recent cancer cases and cancer-related deaths in line with world statistics, creating it a major public ill health in today’s society.
The early diagnosing of BC will improve the prognosis and probability of survival considerably, because it will promote timely clinical treatment to patients. any correct classification of benign tumors will stop patients undergoing supernumerary treatments. Thus, the right diagnosing of BC and classification of patients into malignant or benign teams is that the subject of a lot of analysis. Attributable to its distinctive blessings in crucial options detection from advanced BC datasets, machine learning (ML) is widely known because the methodology of alternative in BC pattern classification and forecast modelling. The dataset can be found here.
Step 1: firstly, we will be importing necessary libraries such as numpy, pandas, seaborn, matplotlib.
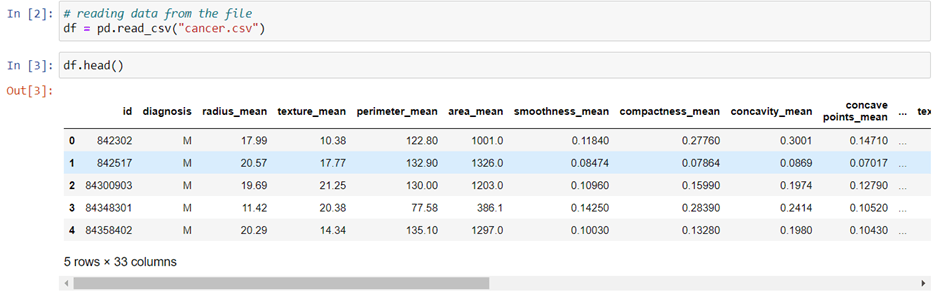
Step 2: We will load our dataset using read_csv function and print top 5 rows of our data.
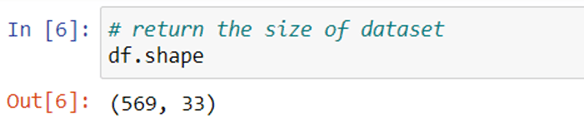
Step 3: we will check the shape of our data.
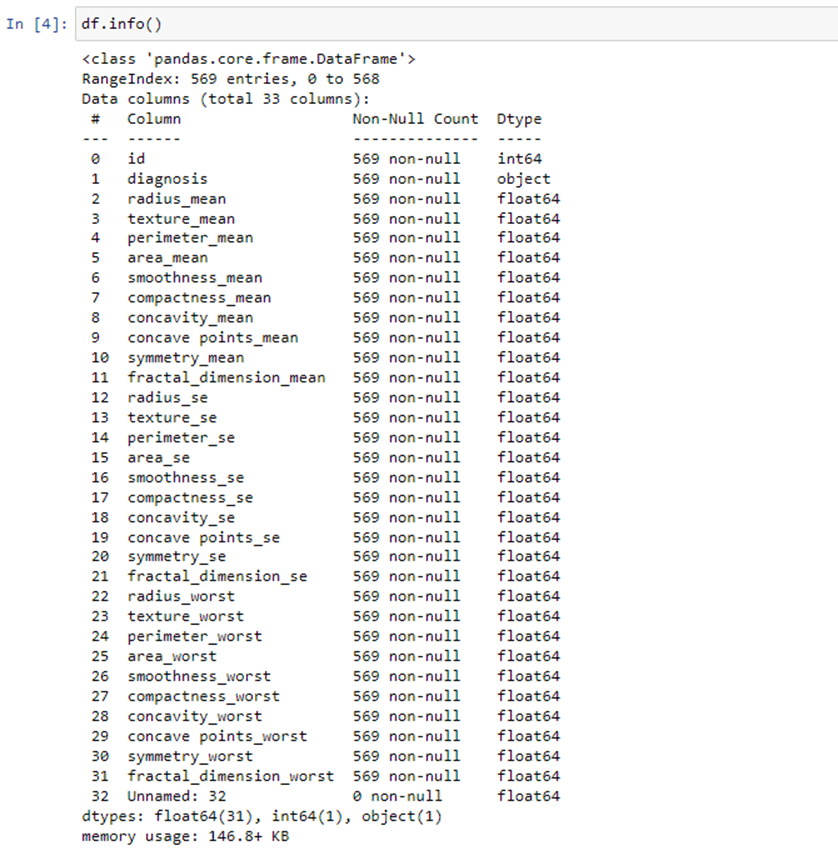
Step 4: we will print the information about our dataset using info() method. The information contains the number of columns, column labels, column data types, memory usage, range index, and the number of cells in each column (non-null values).
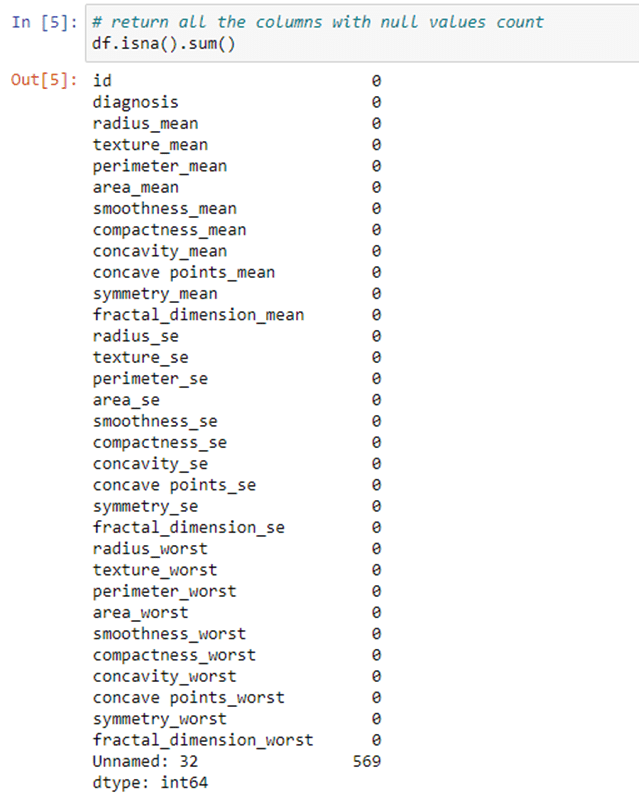
Step 5: we will check the Null value in Dataset using isna() function.
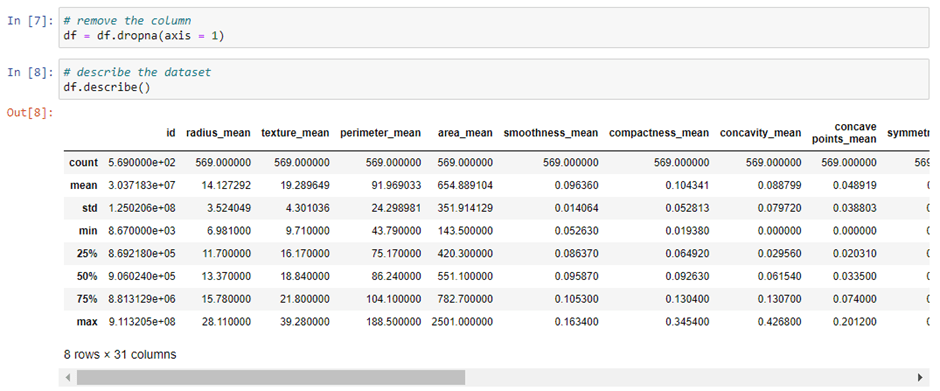
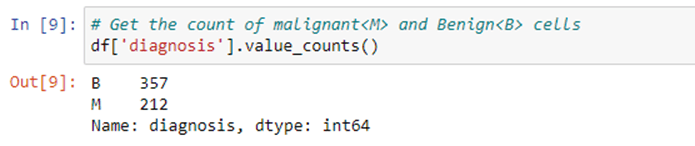
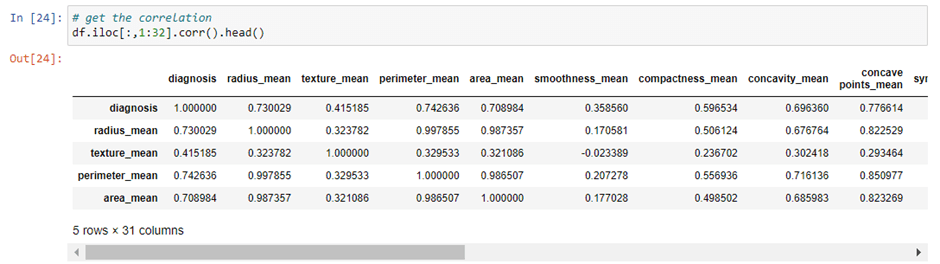
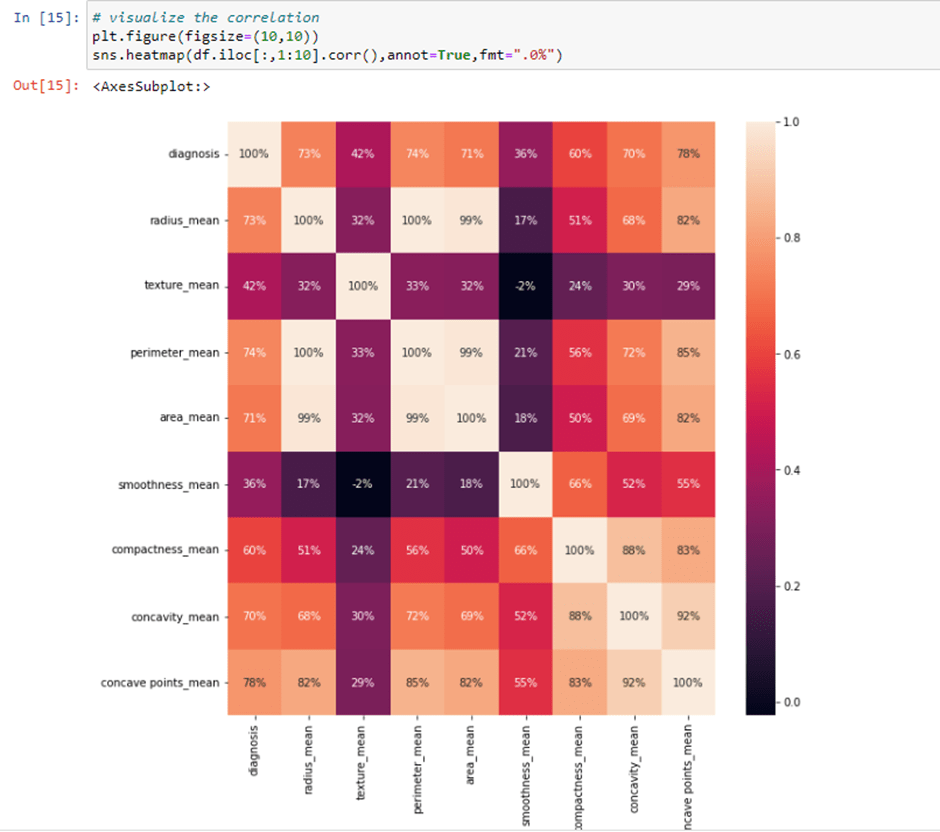
Step 6: now, we will drop the Null values and also we’ll check the description of our data and check the count of malignant and benign cells.

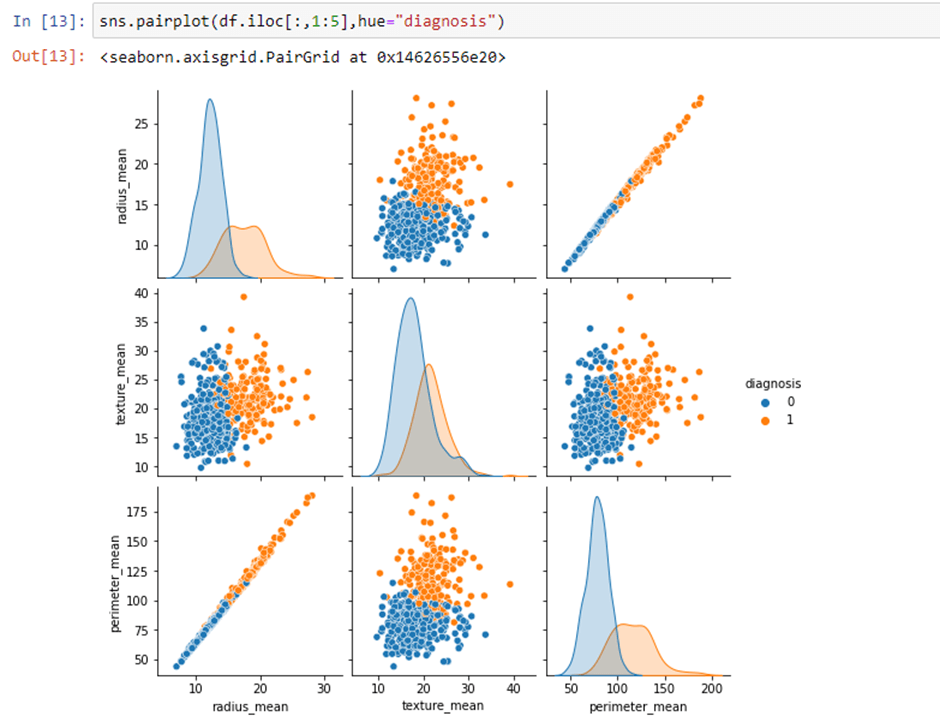
Step 7: Now, we will perform the Labelencoding.
Label coding refers to changing the labels into a numeric type thus on convert them into the machine-readable type. Machine learning algorithms will then decide during a higher manner however those labels should be operated. it’s a vital pre-processing step for the structured dataset in supervised learning.


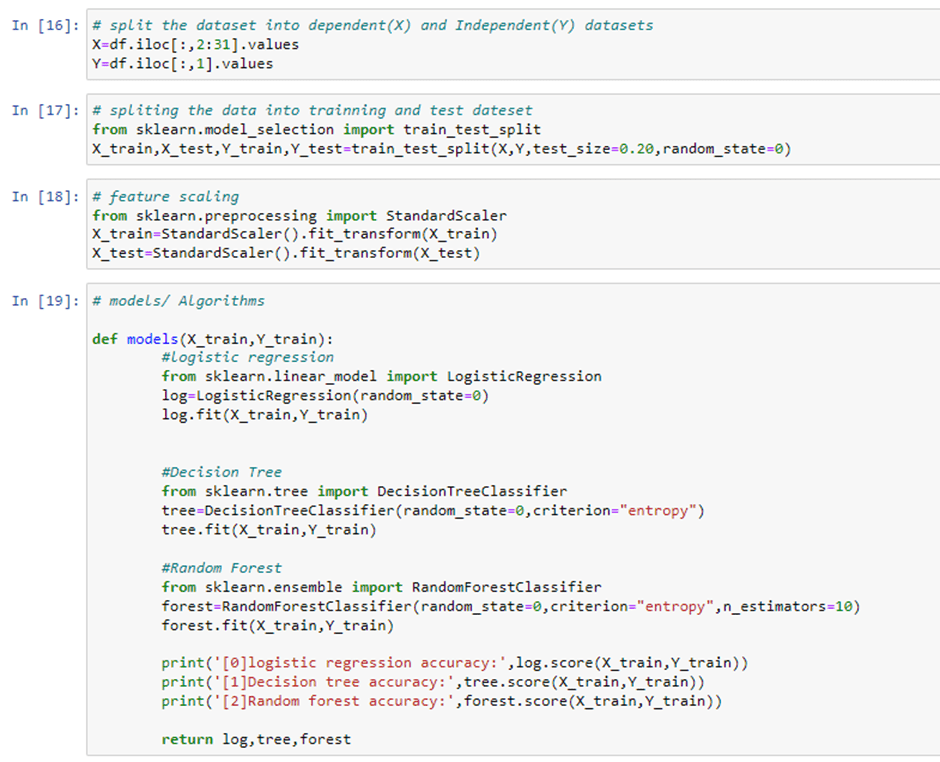
Step 8: we will split our data into train and test set and perform feature scaling on it and train the model.

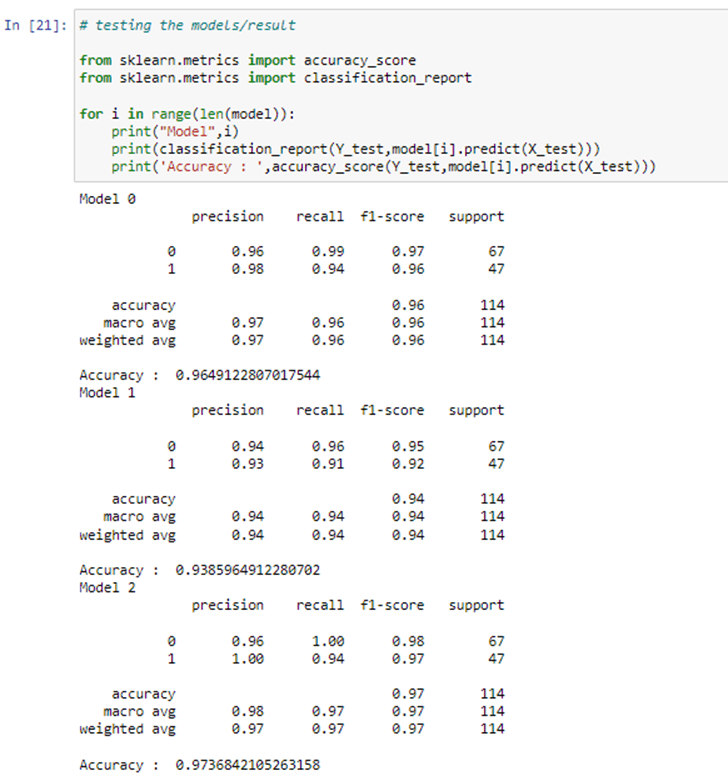
Step 9: we will now test the accuracy of outr model.
step 10: now we will compare the actual values and predicted values.
So finally, we’ve designed our classification model and that we will see that Random Forest Classification algorithmic rule gives the best results for our dataset. Well, it’s not forever applicable to each dataset. to decide on our model, we forever got to analyze our dataset and then apply our machine learning model.

Outstanding post, you have pointed out some wonderful points, I besides conceive this s a very fantastic website.
Well I really enjoyed studying it. This subject procured by you is very effective for good planning.