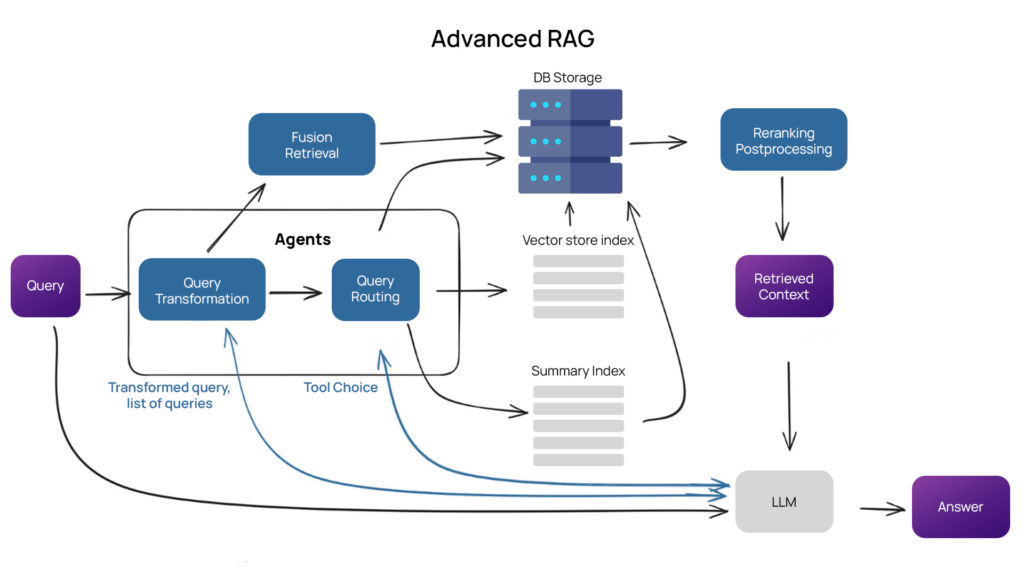
Introduction
Recent advances in AI & ML have significantly transformed information retrieval and data processing. Another important feature is the RAG model, which combines standardized retrieval techniques with powerful generative models to produce more accurate and contextually relevant responses. When paired with a robust vector database like Qdrant, RAG can be further optimized to handle complex queries with advanced ranking techniques. This article will explore the integration of RAG with Qdrant, demonstrate its practical implementation, and delve into advanced methods to enhance response quality.
Understanding RAG and Qdrant
RAG models leverage a two-step process: retrieval and generation. First, a set of relevant documents is retrieved from a large corpus using embeddings. Then, a generative model, like GPT, synthesizes an answer based on the retrieved documents. Qdrant, an efficient and scalable vector database, excels in managing high-dimensional data and performing fast, accurate similarity searches, making it an ideal choice for implementing RAG.

Advantages of Using RAG with Qdrant
Enhanced Accuracy: By leveraging both retrieval and generation, RAG provides more accurate and contextually relevant responses compared to traditional retrieval or generation methods alone.
Efficient Scalability: Qdrant’s efficient handling of high-dimensional data allows the system to scale effectively, making it suitable for large datasets.
Speed: The combination of Qdrant’s fast similarity search and optimized retrieval methods ensures quick response times, essential for real-time applications.
Flexibility: Advanced techniques such as dynamic query expansion and semantic re-ranking allow for tailored responses based on specific needs and contexts.
Enhanced Contextual Understanding: Incorporating external knowledge bases and using context-aware embedding enhancement leads to deeper understanding and more precise answers.
Disadvantages of Using RAG with Qdrant
While RAG models combined with Qdrant offer many advantages, there are also several disadvantages to consider:
Complexity in Implementation: Building and maintaining a RAG system with advanced features requires significant expertise in both machine learning and database management. This complexity can be a barrier for smaller organizations or teams with limited technical resources.
Computational Costs: Operating advanced models and handling extensive vector databases require significant computational power, leading to high operational expenses.
Data Privacy: Managing large volumes of sensitive data necessitates strong security protocols. Ensuring data privacy while incorporating external knowledge bases and integrating multiple data sources can be particularly challenging.
Latency Issues: Although Qdrant is optimized for fast similarity searches, integrating it with complex generative models can introduce latency, especially when dealing with high query volumes or large datasets.
Model Maintenance: Regular updates and fine-tuning are essential to maintain the accuracy and relevance of the RAG system.
Setting Up the Environment
Before diving into advanced techniques, let’s set up a basic RAG model using Qdrant. This section covers the installation and initial setup.
Installation
First, install the necessary libraries:
pip install qdrant-client sentence-transformers transformers
Initial Setup Next, set up the Qdrant client and create a collection for storing document embeddings.
from qdrant_client import QdrantClient
from sentence_transformers import SentenceTransformer
# Initialize Qdrant client
qdrant_client = QdrantClient()
# Create a collection in Qdrant
qdrant_client.create_collection(
collection_name='documents',
dimension=768 # Assuming the embeddings are 768-dimensional
)
# Initialize SentenceTransformer model for embeddings
embedder = SentenceTransformer('all-MiniLM-L6-v2')
Ingesting Data
To effectively use RAG, we need to preprocess and ingest data into Qdrant.
documents = [
"Document 1 text",
"Document 2 text",
# Add more documents as needed
]
# Convert documents to embeddings
embeddings = embedder.encode(documents)
# Ingest embeddings into Qdrant
qdrant_client.upsert(
collection_name='documents',
points=[
{"id": i, "vector": embeddings[i]} for i in range(len(documents))
]
)
Building the RAG Model
With the data ingested, we can build a basic RAG model.
Retrieval Phase First, implement the retrieval phase to fetch relevant documents.
query = "Sample query text"
query_embedding = embedder.encode([query])[0]
# Retrieve top 5 most similar documents
results = qdrant_client.search(
collection_name='documents',
query_vector=query_embedding,
limit=5
)
retrieved_texts = [documents[res['id']] for res in results]
Advanced Techniques for Improved Response Quality
Now, let’s explore advanced techniques to enhance the quality of the RAG system’s responses.
Technique 1: Contextual Embedding Enhancement Enhance embeddings by incorporating context, making retrieval more precise.
def enhance_embedding(text, context):
combined_text = text + " " + context
return embedder.encode([combined_text])[0]
# Example usage
context = "Specific domain or additional information"
enhanced_query_embedding = enhance_embedding(query, context)
Technique 2: Dynamic Query Expansion
Enhance the query by using synonyms or associated terms
from nltk.corpus import word net
def expand_query(query):
synonyms = set()
for word in query.split():
for syn in wordnet.synsets(word):
for lemma in syn.lemmas():
synonyms.add(lemma.name())
expanded_query = " ".join(synonyms)
return expanded_query
expanded_query = expand_query(query)
expanded_query_embedding = embedder.encode([expanded_query])[0]
# Retrieve documents with expanded query embedding
results = qdrant_client.search(
collection_name='documents',
query_vector=expanded_query_embedding,
limit=5
)
Technique 3: Re-ranking with Semantic Similarity
Re-rank retrieved documents based on semantic similarity to the query.
from sklearn. metrics.pairwise import cosine_similarity
def re_rank_documents(query_embedding, retrieved_embeddings):
similarities = cosine_similarity([query_embedding], retrieved_embeddings)
ranked_indices = similarities.argsort()[0][::-1]
return ranked_indices
# Retrieve and re-rank documents
retrieved_embeddings = [embeddings[res['id ']] for res in results]
ranked_indices = re_rank_documents(query _embedding, retrieved _embeddings)
ranked_texts = [retrieved_texts[i ] for i in ranked_indices]
Technique 4: Using External Knowledge Bases
Incorporate external knowledge bases to enrich the context.
import requests
def fetch_external_knowledge(query):
# Example API call to fetch related information
response = requests.get(f"https://api.example.com/search?q={query}")
return response.json()['results']
external_knowledge = fetch_external_knowledge(query)
combined_context = " ".join([doc['summary'] for doc in external_knowledge])
enhanced_query_embedding = enhance_embedding(query, combined_context)
Model Evaluation
Evaluate the RAG system’s performance using metrics like precision, recall, and F1-score. Fine-tune the embeddings, retrieval parameters, and generative model based on feedback and performance analysis.
Conclusion Building a robust RAG system using Qdrant involves more than just integrating a generative model with a vector database. Advanced techniques such as contextual embedding enhancement, dynamic query expansion, semantic re-ranking, leveraging external knowledge bases, and context-aware response generation significantly improve the quality and relevance of responses. By continuously refining and evaluating the system, you can create a powerful tool for handling complex queries across various domains.
