Analogy behind KNN: tell me about your friend (who your neighbors are) and I will tell you who you are.
- KNN is a classification algorithm used in patter recognition.
- K nearest neighbors stores all available cases and classification new cases based on a similarity measure(e.g distance function).
- One of the top data mining algorithms used today.
- A non-parametric lazy learning algorithm (an instance based learning method).
Algorithms
- An object (a new instance) is classified by a majority votes for its neighbor classes.
- The object is assigned to the most common class amongst its k nearest neighbors.(measured by a distant function)
Common distance function measure used for continuous variables.

KNN Working
The k-NN working can be explained on the basis of the below algorithm:
Step-1: select the number of K of the neighbors
Step-2: Calculate the distance measure of K number of neighbors
Step-3: Take the K nearest neighbors as per the calculated Euclidean distance.
Step-4: among these k neighbors, count the number of the data points in each category.
Step-5: assign the new data points to that category for which the number of the neighbor is maximum.
Step-6: our model is ready.
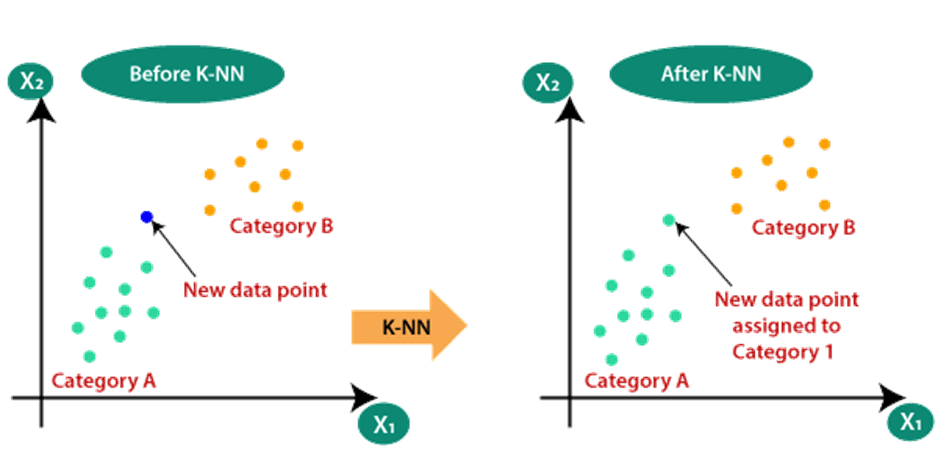
Suppose we have a new data point and we need to put it in the required category.
For K=5, we can see the 3 nearest neighbor are from category A, hence this new data point must belong to category A.
How to choose K
- It is too small it is sensitive to noise points.
- Larger k works well. But too large K may include majority points from other classes.
- Rule of thumb is k < sqrt(n), n is the number of examples.
Pros & Cons
Pros
- Very simple and intuitive
- Can be applied to the data from any distribution.
- Good classification if the number of samples is large enough.
Cons
- Computationally expensive and take more time to classify a new example.
- Choosing k may be tricky.
- Need large number of samples for accuracy.
- KNN is also more prone to overfitting.
