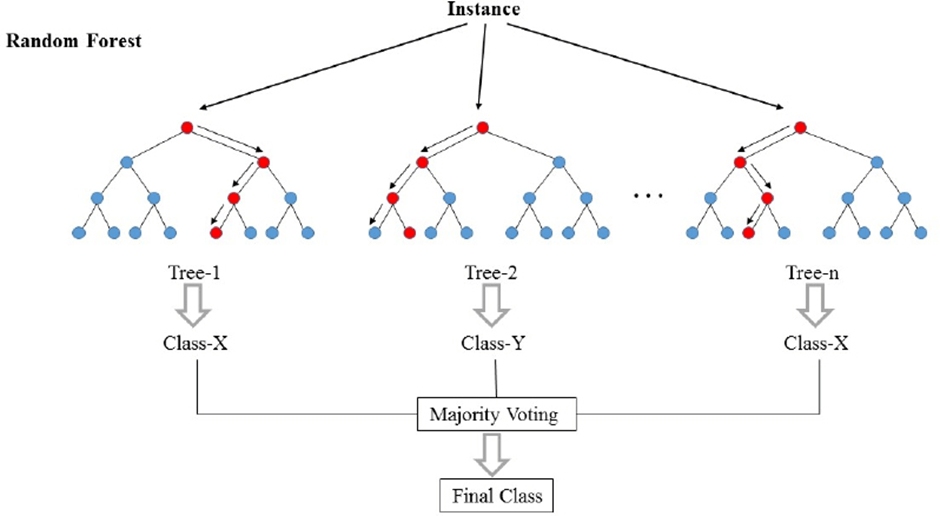
- Random Forest is a popular Machine Learning algorithm that belongs to the supervised learning technique. It can be used for both Classification and Regression problem in ML.
- It is based on the concept of ensemble learning, where a classifier that contains a number of decision trees on various subsets of the accuracy of that dataset.
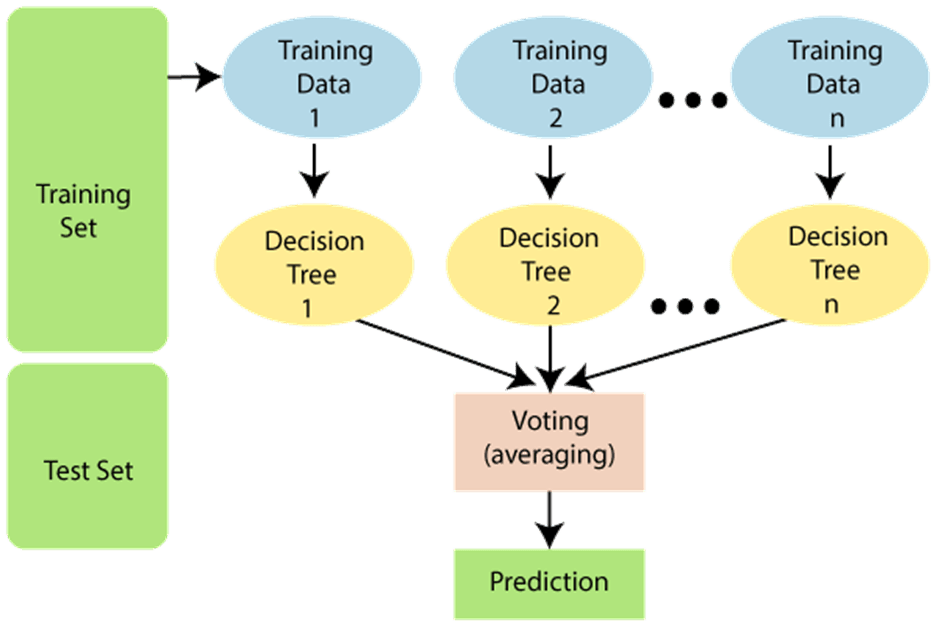
Random Forest is better than Decision Tree as the greater number of trees in the forest leads to higher accuracy and prevents the problem of overfitting.
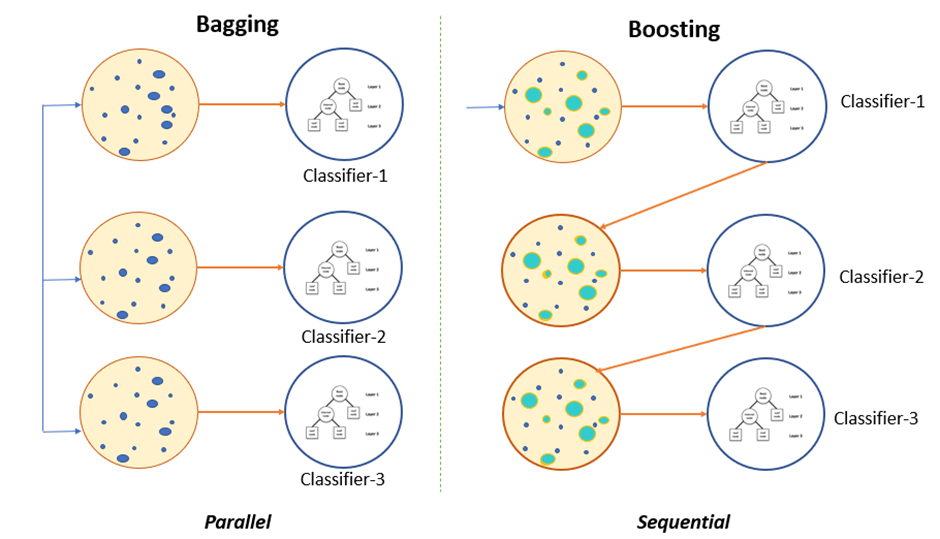
- Bagging also called Bootstrap Aggregating, is Machine Learning ensemble technique designed to improve the stability and accuracy of machine learning algorithms. It helps in eliminating the overfitting by reducing the variance of the output.
- Bootstrapping is a statistical technique used for data resampling. It involves iteratively resampling a dataset with replacement. The objective is to create multiple datasets by collecting random samples from original training set.
Algorithm working
Random Forest uses a Bagging technique with one modification, where subset of features are used for finding best split.
- Step 1: Select random K data points from the training set i.e to create training dataset using bootstrap approach.
- Step 2: Build the decision tree associated with the selected data points (Subsets).
- Step 3: Choose the number N for decision trees that you want to build.
- Step 4: Repeat step 1 & 2
- Step 5: For new data points, finds the prediction of each decision tree, and assign the new data points to the category that wins the majority votes.
Advantages & Disadvantages
- Random Forest is capable of performing both classification and Regression tasks.
- It is capable of handling large datasets with high dimensionality.
- It enhances the accuracy of the model and prevents the overfitting issue.
Disadvantages
- The main limitation of random forest is that a large number of trees can make the algorithm too slow and ineffective for real-time predictions.
- It has low interpretability than a single decision tree and it is hard to visualize and bunch of decision trees.
- A trained forest may require significant memory for storage.
Popular Posts
Author

Spread the knowledge