What is Edge detection?
Edge detection is a computer vision technique that uses the edges of an image to find and extract objects. It is widely used in a variety of fields such as photography, video and computer vision.
it is used in many ways in computer vision, including image segmentation, which divides an image into different regions based on their color and texture. This technique can be used to detect objects, such as eyes or hair, in images.
The edge detection algorithm defines the pixels that are on the boundary of an object as black and those that are not as white. The algorithm then calculates a difference value between each pixel on the edge and its neighboring pixels to determine how different they are.
Why do we need Edge Detection?
The natural variations in depth, surface orientation, scene illumination variations, and material properties changes lead to discontinuities in the brightness of images. In computer vision, we can find curves that indicate the boundaries of objects and surface markings, and curves that correspond to discontinuities in surface orientation. Using an edge detection algorithm to reduce the amount of data needed to process can help you filter out information that may be less relevant while preserving any essential structural properties.
Different techniques for edge detection.
The two most commonly used algorithms are the gradient method and the Gaussian filter.
Gradients
Recognising a local peak in the first derivative is already difficult, so it’s not hard to imagine how difficult it would be to make further progress when the number of dimensions grows. Gradient is the measure that tells you the difference in values of a continuous function between two points over some distance. Here, we can think an image as an array of samples taken from a continuous function of picture intensity. The gradient is a vector defined as the two-dimensional equivalent of the first derivative. It has two crucial proper definitions: steepness and inclination. It can be used to see large or minute changes in grey levels in pictures.
- The vector is pointing in the direction of the highest rate of rising, which is some function that takes into account the coordinates.
2. The gradient’s magnitude is the highest rate of rising of the function of the coordinates per unit distance in a vector’s direction
The gradient magnitude is usually approximated using the absolute value. As angle ‘A’ with relation to the x-axis, the gradient’s direction is determined by vector analysis. These are known as isotropic operators, meaning that the size of the gradient is not dependent on its orientation. Three operators are used to derive the first derivative which is the Sobel operator, Prewitt operator, and Robert operator.
- Robert’s cross operator approximates the gradient magnitude in a simple way. It is made up of 2 × 2 matrices. Robert’s operators allow you to calculate the gradient at a point rather than at a spot.
- The gradient’s magnitude is represented by the Sobel operator. The 3 x 3 neighbourhood around a pixel avoided the interpolation error that often occurs in order to avoid aliasing. Pixels near the center of a randomly masked image using the Sobel operator are considered more important than other areas of the mask. This is one of the most common edge detectors.
- The Prewitt operator uses equations that are similar to the Sobel operator but uses a constant of 1. A Sobel operator places some emphasis on the centre of a mask, while this one doesn’t.
Gaussians
The system was given two edges and found the first derivative to be equal to zero so it assumed that there was no edge point. This software identifies the points of highest gradient or steepest slope in a signal, but since it is not human, it only looks for the edges and corners of a specific region. You will have to set up an algorithm that examines the gradient values throughout your image if you want to find just bars with local maxima.
At edge points, first derivative will increase and second derivative will decrease. Edge points may be identified by locating the Laplacian of Gaussian which is represented as two 2D operators: Canny edge detector and Laplacian of Gaussian.
Let’s implement using Python and OpenCV

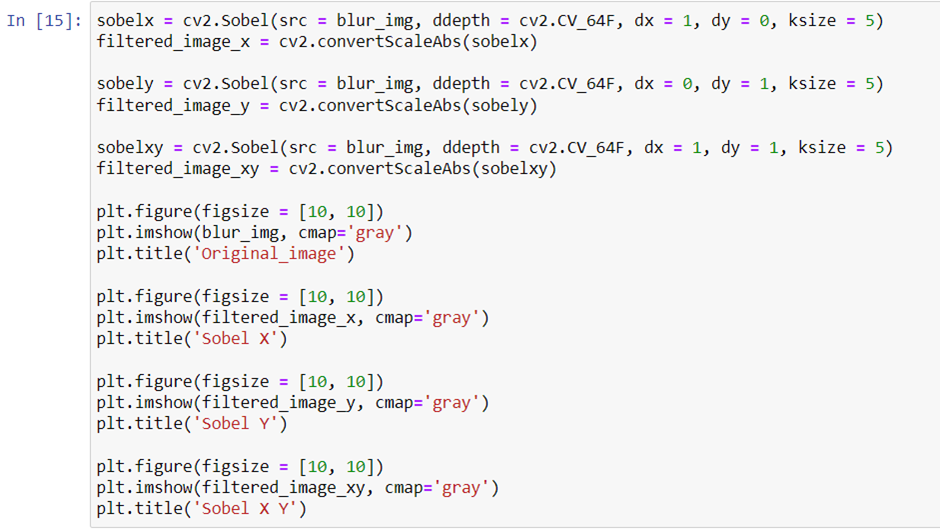
Sobel edge detector
In this, we will be taking three different scenarios to compare the X-axis, Y-axis and XY axis edge detection.




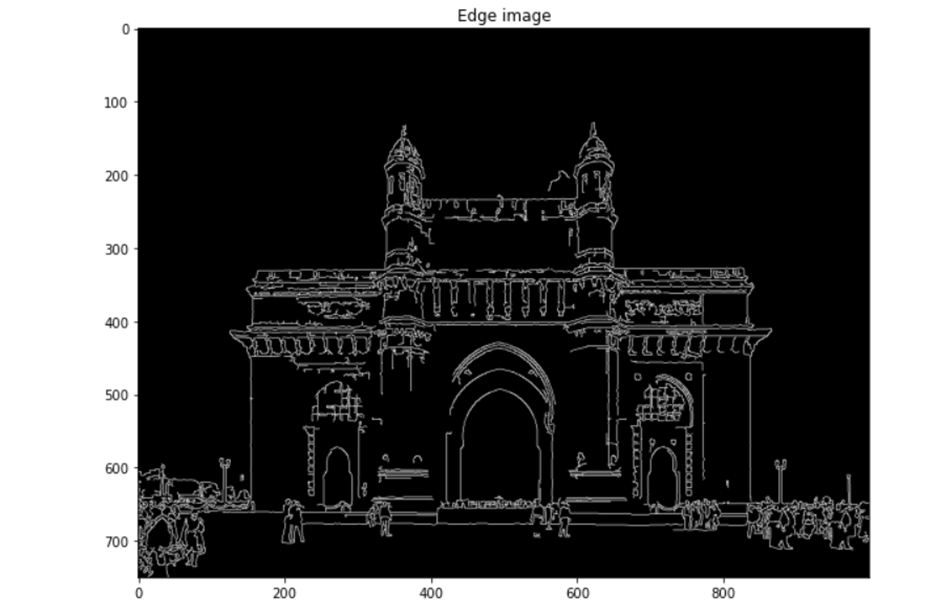
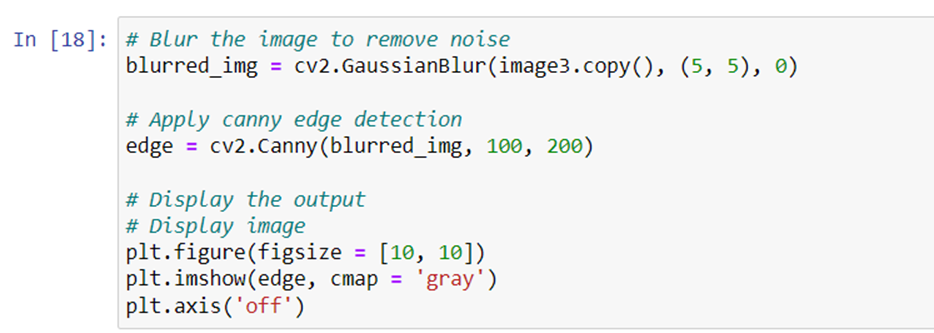
Canny edge detector
The method uses a three-stage procedure to extract edges from an image, and when blurring is applied, the process totals four stages.


Let’s take another example of Canny edge detector


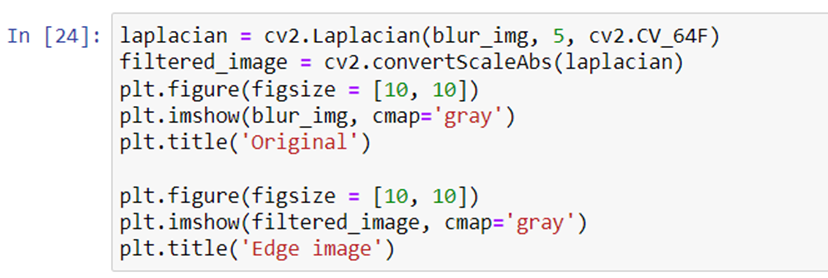
Laplacian edge detector
The Laplacian edge detector compares an image’s second derivatives. It counts the number of times the first derivative changes in a single pass.


Comparing the result of all the three methods the Canny edge was able to detect most of the edges in the objects.
In this article, we have understood the concept and operation of edge detection with an implementation using OpenCV.
