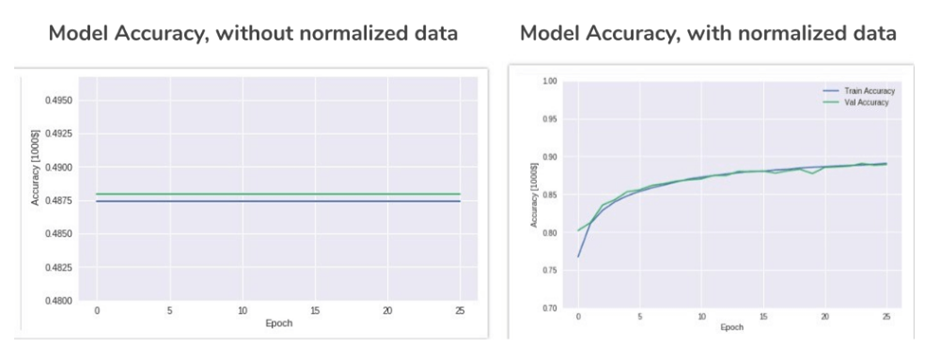
1 – What is data normalization? What’s the need for it?
Data normalization is a process of transforming data from one format to another in order to improve the quality of the data and make it more usable for analysis. In this process data is organized and formatted in such a way that it’s easier for deep learning to analyze.
Data normalization is necessary because data can be stored in different formats and structures. This makes it harder for deep learning to compare different datasets and find similarities or patterns.
Data Normalisation occurs when data are transformed in such a way that they have either a same distribution or dimensionless variables. It is also called Standardization and Feature Scaling. It’s a pre-processing procedure for the input data processed by Data Scientists.
Normalization makes it so variables are all equal, which prevents one variable from having more weight than the others and putting your model at a disadvantage because of its size. Converting values to an equal scale can cause errors that do not exist for one column. This is where the new model comes in by converting columns to a similar scale without modifying the range of numbers.
2 – What is the difference between multi-class and multi-label classification problems.

A multi-label classification problem is a classification problem where the input can belong to more than one class. For example, a photo can be both an animal and a dog. A multi-class classification problem is when the input can only belong to one class at a time. For example, a photo can either be an animal or it can just be a dog.
The difference between these two types of problems is that in the case of multi-label classification, there are more classes than there are labels whereas in the case of multi-class problems, there are more labels than there are classes.
It is important to understand the difference between multi-class and multi-label classification problems in order to choose the right algorithm for your task.
When we are dealing with a multi-class classification problem, the classes are mutually exclusive. This means that any given input belongs to one and only one class. In contrast, when we deal with a multi-label classification problem, the classes are not mutually exclusive. This means that any given input can belong to more than one class at the same time.
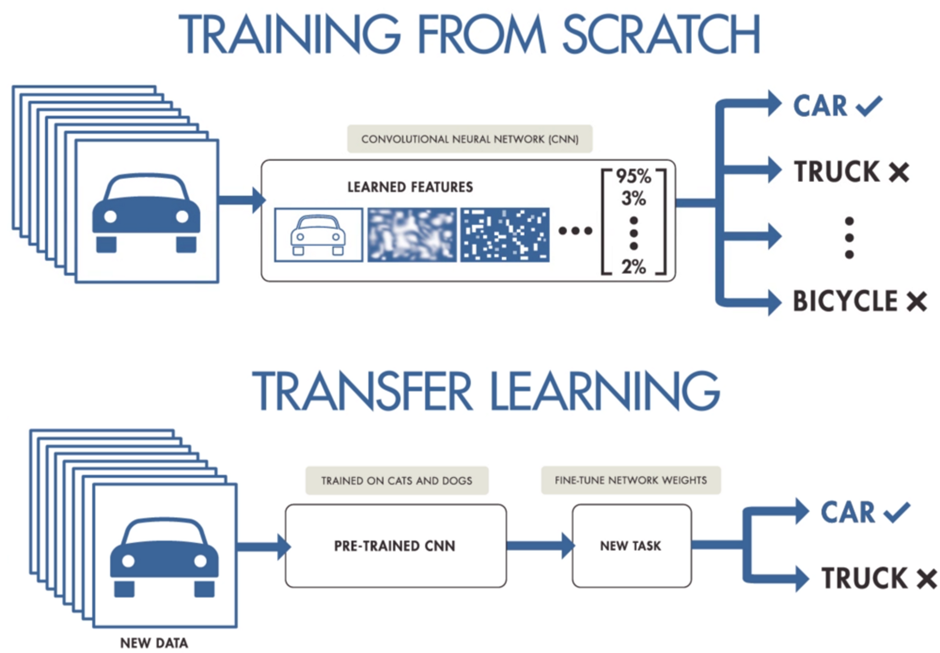
3 – What is transfer learning?
Transfer learning is the process of using a neural network that has been trained on a large set of data to solve a different but similar problem.
It is an important aspect of machine learning. It helps improve the performance and accuracy of machine learning models by leveraging knowledge from previous tasks.
It is a technique for training deep neural networks with large amounts of data. This technique can be used to train networks for different tasks in order to achieve better results than if it were only trained on one task.
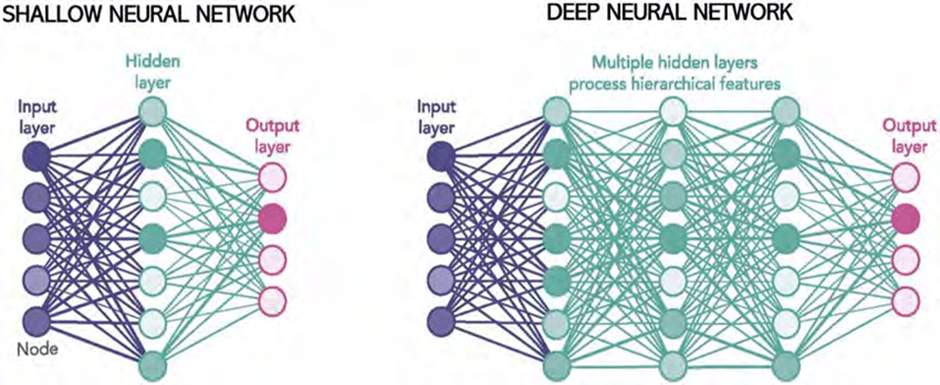
4 – Explain the difference between a shallow network and a deep network.
A deep network is a neural network that has more than one hidden layer of nodes.
A shallow network is a neural network that only has one hidden layer of nodes.
Different types of networks are suited for different tasks. For example, a deep network is usually used for classification tasks because it can learn complex features from the data. On the other hand, shallow networks are better suited for regression tasks because they can take into account all the features in the data and find correlations between them.
Deep networks are also called hierarchical networks because they can have many layers of information.
In contrast, a shallow network is one that has few layers in its architecture. It is more limited in how it can represent information, but it can be faster to train.
The number of layers determines the complexity of the network’s function and how much information it can process at once.
5 – What is Batch gradient descent?
Batch Gradient Descent is a training algorithm for deep neural networks. It is an iterative optimization technique that computes the gradient of the loss function with respect to all weights and biases in the network.
The Batch Gradient Descent algorithm is called batch because it requires a batch of examples to compute the gradient of the loss function with respect to all weights and biases in the network.
Batch gradient descent is a common technique for training neural networks. It takes a large number of examples and finds the best weights for the network by applying the gradient descent algorithm.
This technique is often used in deep learning because it is one of the few algorithms that can be applied to very large datasets. However, it has its own limitations. One of them is that it needs to find an initial set of weights before it can start training. This means that if you are new to deep learning, you have to spend time on designing a good neural network architecture before you can train it with batch gradient descent algorithm.

