
Machine learning is an exciting field that involves developing algorithms and statistical models that enable computers to learn from data and make predictions or decisions without being explicitly programmed. Machine learning is becoming increasingly popular in a wide range of industries, including finance, healthcare, and e-commerce. According to PayScale, the average salary of a machine learning engineer in the United States is around $112,742 per year, while in India, it is around 9 LPA per year. In this blog post, we will discuss some common machine learning interview questions.
Q1: Explain Machine Learning, Artificial Intelligence, and Deep Learning
It is common to get confused between machine learning, artificial intelligence (AI), and deep learning. While these three technologies are different from each other, they are interrelated. Deep learning is a subset of machine learning, and machine learning is a subset of AI. Let’s learn about these technologies:

- Machine Learning: Machine learning involves various statistical and deep learning techniques that allow machines to use their past experiences and get better at performing specific tasks without being explicitly programmed.
- Artificial Intelligence: Artificial intelligence uses numerous machine learning and deep learning techniques that enable computer systems to perform tasks using human-like intelligence with logic and rules.
- Deep Learning: Deep learning comprises several algorithms that enable software to learn from itself and perform various business tasks, including image and speech recognition. Deep learning is possible when systems expose their multi-layered neural networks to a large volume of data.
Q2: What is Supervised Learning?
Supervised learning is the machine learning task of inferring a function from labeled training data. The training data consist of a set of training examples.
Algorithms: Support Vector Machines, Regression, Naive Bayes, Decision Trees, K-nearest
Neighbor Algorithm and Neural Networks
E.g. If you built a fruit classifier, the labels will be “this is an orange, this is an apple and this is a banana”, based on showing the classifier examples of apples, oranges and bananas.
Q3: What is Unsupervised learning?
Unsupervised learning is a type of machine learning algorithm used to draw inferences from datasets consisting of input data without labelled responses.
Algorithms: Clustering, Anomaly Detection, Neural Networks and Latent Variable Models
E.g. In the same example, a fruit clustering will categorize as “fruits with soft skin and lots of dimples”, “fruits with shiny hard skin” and “elongated yellow fruits”.
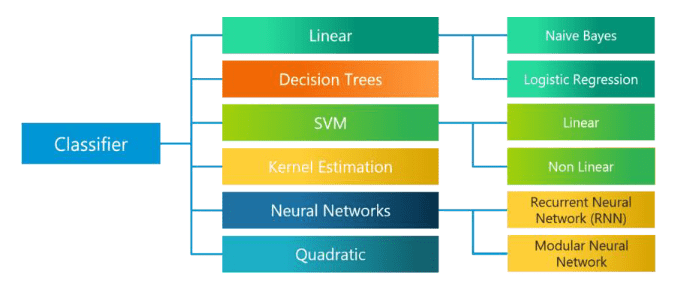
Q4: What are the various classification algorithms?
The diagram lists the most important classification algorithms.
Q5: What is ‘Naive’ in a Naive Bayes?
The Naive Bayes Algorithm is based on the Bayes Theorem. Bayes’ theorem describes the probability of an event, based on prior knowledge of conditions that might be related to the event.
The Algorithm is ‘naive’ because it makes assumptions that may or may not turn out to be correct.
Q6: What is SVM in Machine Learning?
SVM, or Support Vector Machines, is a machine learning algorithm used for classification. It is based on the high dimensionality of the characteristic vector, which defines what SVM is in machine learning.
SVM is used to find the best hyperplane that separates data points of different classes. It is a powerful algorithm for both linear and non-linear classification tasks.
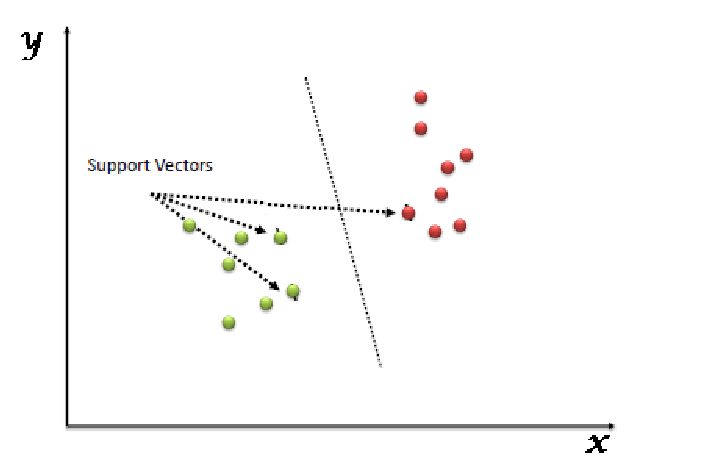
Q7. What are the support vectors in SVM?
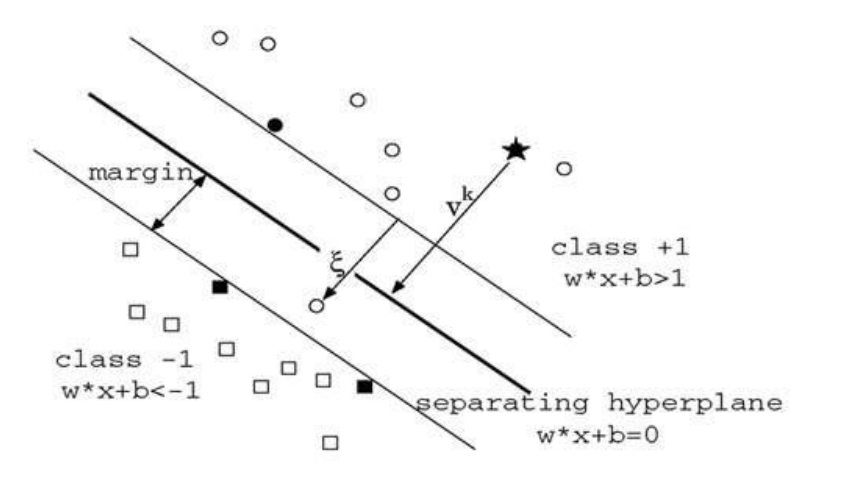
In the diagram, we see that the thinner lines mark the distance from the classifier to the closest data points called the support vectors (darkened data points). The distance between the two thin lines is called the margin.
Q8: What are the different kernels in SVM?
There are four types of kernels in SVM.
- Linear Kernel
- Polynomial kernel
- Radial basis kernel
- Sigmoid kernel
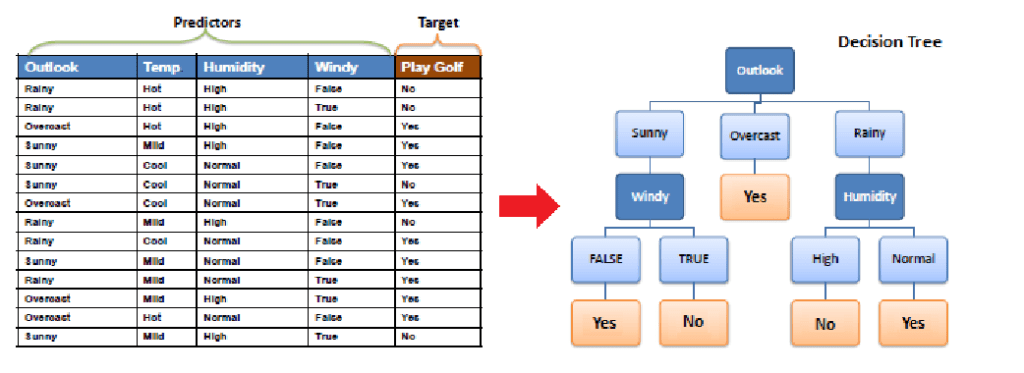
Q9: What is Decision Tree in Machine Learning?
A decision tree is a hierarchical diagram that shows a sequence of actions that must be performed to get the desired output. It is used to explain a set of hierarchy of actions.
For example, a decision tree can be created to explain the sequence of actions for driving a vehicle with or without a license. Each node in the decision tree represents an action, and the branches represent the possible outcomes of that action.
Decision trees are commonly used in machine learning to make decisions based on a set of conditions. They can be used for tasks like classification and regression.
Q10: What are Entropy and Information gain in Decision tree algorithm?
The core algorithm for building a decision tree is called ID3. ID3 uses Entropy and Information Gain.
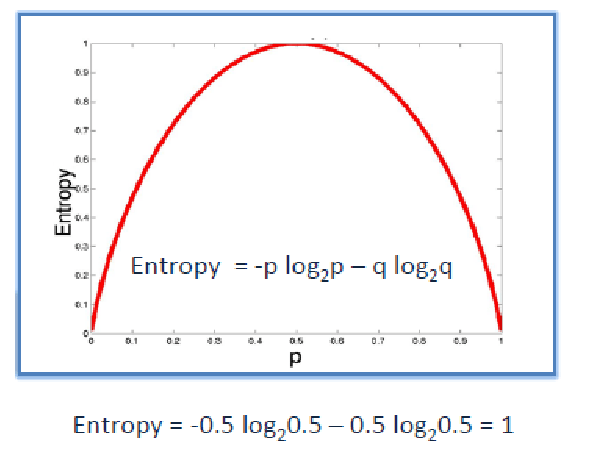
Entropy
A decision tree is built top-down from a root node and involve partitioning of data into homogenious subsets. ID3 uses entropy to check the homogeneity of a sample. If the sample is completely homogenious then entropy is zero and if the sample is an equally divided it has entropy of one.
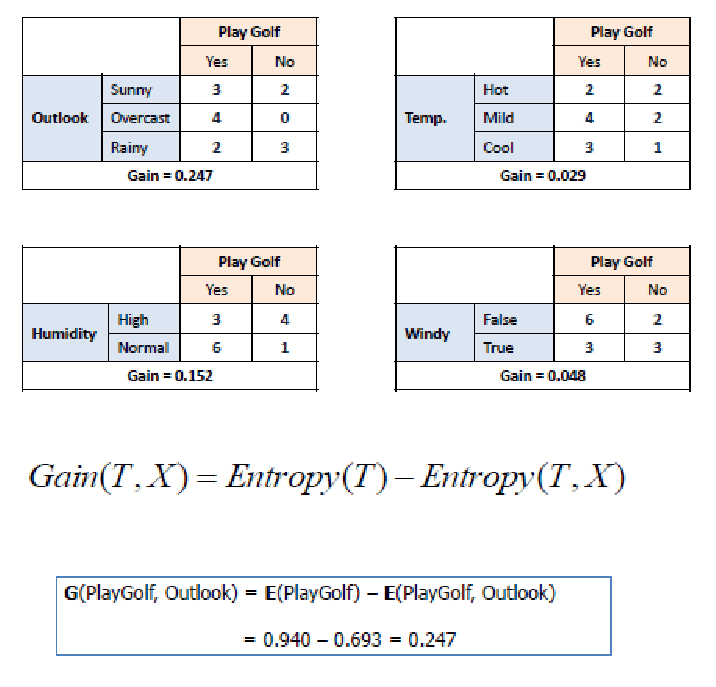
Information Gain
Q11: What is pruning in Decision Tree?
Pruning is a technique in machine learning and search algorithms that reduces the size of decision trees by removing sections of the tree that provide little power to classify instances. So, when we remove sub-nodes of a decision node, this process is called pruning or opposite process of splitting.
Q12: What is logistic regression? State an example when you have used logistic regression recently.
Logistic Regression often referred to as the logit model is a technique to predict the binary outcome from a linear combination of predictor variables.
For example, if you want to predict whether a particular political leader will win the election or not. In this case, the outcome of prediction is binary i.e. 0 or 1 (Win/Lose). The predictor variables here would be the amount of money spent for election campaigning of a particular candidate, the amount of time spent in campaigning, etc.
Q13: What is Linear Regression in Machine Learning?
Linear regression is a supervised machine learning algorithm used to find the linear relationship between dependent and independent variables for predictive analysis. It involves an equation of the form y = A + Bx, where x is the input or independent variable, y is the output or dependent variable, A is the intercept, and B is the coefficient of x.
The goal of linear regression is to find the best values of A and B that minimize the errors in the prediction of y. This is done by adjusting the values of A and B to reduce the difference between the predicted and actual values of y.
Q14. What is the difference between Regression and classification ML techniques?
Both Regression and classification machine learning techniques come under Supervised machine learning algorithms. In Supervised machine learning algorithm, we have to train the model using labelled data set, While training we have to explicitly provide the correct labels and algorithm tries to learn the pattern from input to output. If our labels are discrete values then it will a classification problem, e.g A,B etc. but if our labels are continuous values then it will be a regression problem, e.g 1.23, 1.333 etc.
Q15: What are Recommender Systems?
Recommender Systems are a subclass of information filtering systems that are meant to predict the preferences or ratings that a user would give to a product. Recommender systems are widely used in movies, news, research articles, products, social tags, music, etc.
Examples include movie recommenders in IMDB, Netflix & BookMyShow, product recommenders in e-commerce sites like Amazon, eBay & Flipkart, YouTube video recommendations and game recommendations in Xbox.
Q16: What is Collaborative filtering?
The process of filtering used by most of the recommender systems to find patterns or information by collaborating viewpoints, various data sources and multiple agents.
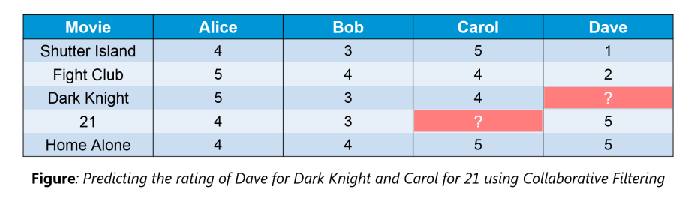
An example of collaborative filtering can be to predict the rating of a particular user based on his/her ratings for other movies and others’ ratings for all movies. This concept is widely used in recommending movies in IMDB, Netflix & BookMyShow, product recommenders in e-commerce sites like Amazon, eBay & Flipkart, YouTube video recommendations and game recommendations in Xbox.
Q17: How can outlier values be treated?
There are a number of ways to treat outlier values, depending on the specific situation and the desired outcome. Some common methods include:
- Removing the outliers: This is the simplest approach, but it should only be used if the outliers are known to be errors or if they are not representative of the data.
- Capping the outliers: This involves setting a threshold for the data, and any values that fall outside of that threshold are capped at the threshold. This is a good approach if the outliers are not errors, but they are still too extreme to be included in the analysis.
- Transforming the data: This involves using a mathematical transformation to change the distribution of the data, such as taking a log transformation or a square root transformation. This can be effective in reducing the impact of outliers, but it is important to choose a transformation that is appropriate for the data.
- Using robust statistical methods: There are a number of statistical methods that are resistant to the influence of outliers. These methods can be used to calculate summary statistics, such as the mean and median, without being skewed by the outliers.
The best way to treat outliers will depend on the specific situation and the desired outcome. It is important to carefully consider all of the options before choosing a method.
Here are some additional tips for treating outliers:
- Identify the outliers: The first step is to identify the outliers in the data. This can be done using visual inspection or statistical methods.
- Understand the cause of the outliers: Once the outliers have been identified, it is important to try to understand the cause of the outliers. This will help to determine the best course of action.
- Document the treatment: It is important to document how the outliers were treated. This will help to ensure that the data is analyzed correctly and that the results are interpreted correctly.
Q18: What is Overfitting in Machine Learning?
Overfitting occurs when a machine learning model has an inadequate dataset and tries to learn from it. It happens when a model becomes too complex and starts to fit the noise in the training data rather than the underlying pattern.
To avoid overfitting, cross-validation methods can be used. These methods involve dividing the dataset into training and testing sets and evaluating the model’s performance on the testing set. By using cross-validation, overfitting can be minimized.
Q19: What is Hypothesis Testing in Machine Learning?
Hypothesis testing in machine learning involves using a dataset to understand a specific function that maps the input to the output. The goal is to approximate the target function and perform necessary input-to-output mappings.
Hypothesis testing is done by choosing and configuring algorithms to define the space of plausible hypotheses that may be represented by the model. The lower case “h” is used for a specific hypothesis, while the uppercase “H” represents the hypothesis space being searched.
Hypothesis testing is an important part of machine learning as it helps in approximating the target function and making predictions.
Q20: What is PCA in Machine Learning?
PCA, or Principal Component Analysis, is a technique used in machine learning to reduce the dimensionality of multi-dimensional data. It helps in data visualization and computation by removing irrelevant dimensions and keeping only the most relevant ones.
The goal of PCA is to find a fresh collection of uncorrelated dimensions and rank them based on variance. This allows for easier analysis and visualization of the data.
Popular Posts
- From Zero to Hero: The Ultimate PyTorch Tutorial for Machine Learning Enthusiasts
- Day 3: Deep Learning vs. Machine Learning: Key Differences Explained
- Retrieving Dictionary Keys and Values in Python
- Day 2: 14 Types of Neural Networks and their Applications
