1 – What are Different Types of Machine Learning algorithms?
There are various types of machine learning algorithms. The most popular ones include supervised learning, unsupervised learning and reinforcement learning.
Supervised Learning: Supervised machine learning is when a human has to provide the correct answer for the algorithm to learn from. This is done by feeding it with a set of training data and labels so that it can predict future outcomes with accuracy.
Unsupervised Learning: Unsupervised machine learning is when there isn’t any human input needed and the algorithm learns by itself through trial and error. It does this by taking in huge amounts of unlabeled data and finds patterns in it on its own.
Reinforcement Learning: Reinforcement learning is when a machine takes an action and is either rewarded or penalized based on the result.

2 – What is PCA? When do you use it?
PCA (Principal Component Analysis) is a technique used to reduce the dimensionality of data. It can be used when the data has a lot of features and there are too many possible combinations to explore.
The PCA technique is used in machine learning when there are so many features that it becomes difficult for the model to differentiate between them. The goal is to reduce the number of features, without sacrificing accuracy, so that the model can make better predictions. This technique is mainly used in exploratory data analysis and visualization, where it helps to identify outliers and other interesting features of the data set.
The use cases for PCA are:
– Dimensionality Reduction
– Visualization
– Feature Extraction
– Model Selection
3 – What is Cross-Validation?
Cross-validation is a process that can be used to determine the accuracy of a model. A model’s accuracy is determined by how well it could predict future values, given past values. This process involves training the model on some data and then using it to predict future values in the same dataset, but with some of the data withheld. The withheld data are called ‘test’ data and they are only used for validation purposes.
In order to calculate how accurate a model is, we need to compare its prediction with what actually happened in the test set – both in terms of predicting whether something will happen or not happen and in terms of predicting what value something will have. If we do this and plot the model’s accuracy on the y-axis and the true outcome on the x-axis, we get a scatter plot where each point represents a single data point.

4 – Difference Between Classification and Regression?
Classification is a process in which the machine assigns a category to an individual based on the data that it has seen. It is a supervised learning technique in which the machine follows specific instructions to detect patterns and classify them. It is a type of supervised machine learning in which the model learns to predict a category or label given an observation. Classification models are used to predict discrete values, such as whether an email is spam or not.
Regression, on the other hand, is a supervised machine-learning task that predicts continuous values, such as the price of a house. Regression models are used to predict real-valued quantities, such as how many people will attend an event based on ticket prices and advertising budget.

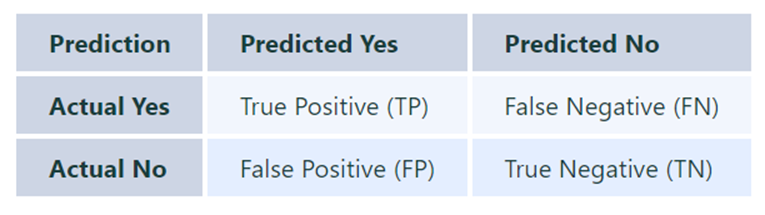
5 – What is F1 score? How would you use it?
F1 score is a measure of the accuracy of a machine learning algorithm. It is calculated by dividing precision and recall, where precision is the number of correctly classified instances divided by the total number of instances, and recall is the number of correctly classified instances divided by the total number of relevant instances (in other words, correct predictions).
The F1 score ranges from 0 to 1. The higher scores represent algorithms with high accuracy.