1 – Define precision and recall?
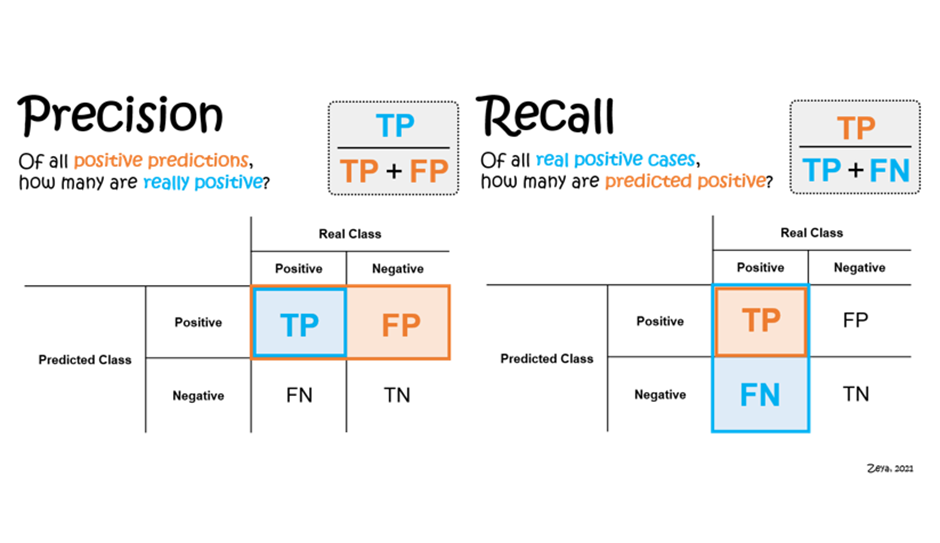
The precision and recall are two measures of data quality. They are used to determine the proportion of relevant data that is found by a search algorithm. Precision is a measure of how many of the retrieved records are correct. Recall is a measure of how many of the records that need to be retrieved were actually found.
Precision is the ratio of relevant items found to all items retrieved by a query. The term precision is used in information retrieval and statistics. In information retrieval, it gives the probability that when a user queries for “apple”, they will also retrieve a document about “apples”.
Recall is the ratio of relevant items found to all possible items in the source data set. A recall of 0% means that none of the relevant items were found, and a recall of 100% means that all relevant items were found.
2 – How to Tackle Overfitting and Underfitting?
Overfitting is a common problem in machine learning. It occurs when the model fits the training data too well, but does not generalize well to the test data or future data. The model has overlearned and cannot make predictions accurately.
Underfitting is a common problem in machine learning. It occurs when a model cannot make accurate predictions because it doesn’t have enough parameters or complexity to capture all of the nuances of the training data.
The best way to avoid overfitting and underfitting is by using cross-validation and regularization techniques such as L1 and L2 penalties.
1) Regularization: This technique reduces overfitting by adding noise to weights during training time so that they do not become too extreme for any one input variable.
2) Cross-validation: This technique helps overcome underfitting by splitting the training data set into a number of different subsets. Then, one subset is used to generate a predictive model, and the remaining subsets are used to test the model’s effectiveness.
3 – What are Loss Function and Cost Functions?
Loss function and cost function are the two main parameters that define the performance of a machine learning model. They are used to measure how accurate a model is.
Loss functions quantify how well a model is predicting the right answer, while cost functions quantify how much time it takes for the algorithm to train on data.
4 – What is Collaborative Filtering? And Content-Based Filtering?
Collaborative filtering is a type of machine learning that takes into account the preferences of other people to predict what a user might like. It is used by companies like Netflix and Amazon to provide personalized recommendations.
Content-based filtering is a type of machine learning that uses keywords in the content to predict what a user might like and when it can be applied for example Spotify’s Discover Weekly playlist of personalized music recommendations.

5 – What is P-value?
P-value is a statistical measure that can be used to assess the probability of an event occurring by chance.
The p-value is a measure of how likely it is that the null hypothesis (the hypothesis that there is no effect) will be rejected by an experiment. If the p-value of an experiment is less than 0.05, then we reject the null hypothesis and conclude that there really was a difference between our two groups.
When it comes to testing hypotheses, P-values are one way of determining whether or not the null hypothesis should be rejected in favor of the alternative hypothesis. The null hypothesis assumes that there is no relationship between variables and the alternative hypothesis assumes that there is a relationship between variables.
