1 – What are autoencoders? Explain the different layers of autoencoders.
Autoencoders are neural networks that are trained to reconstruct an input data into a desired output data. They can be thought of as the opposite of a traditional classifier, which is trained to classify inputs into pre-defined classes.
Autoencoders can be seen as a type of unsupervised learning algorithm that is used for dimensionality reduction. They take in a large amount of data and compress it into an encoded vector with fewer dimensions than the original data. This vector can then be decoded back into its original form to produce the same output as the input data.
When input is sent to the network, autoencoders rebuild all dimensions of that input, reducing its size. The process may seem simple but in fact it results in a loss of information: after replication, the size and content of the input are reduced. Compared to the input and output layers, the middle layers of the network have fewer units. So, only a reduced version of the input is stored in these middle layers. This reduced representation is used to recreate the original text when necessary.
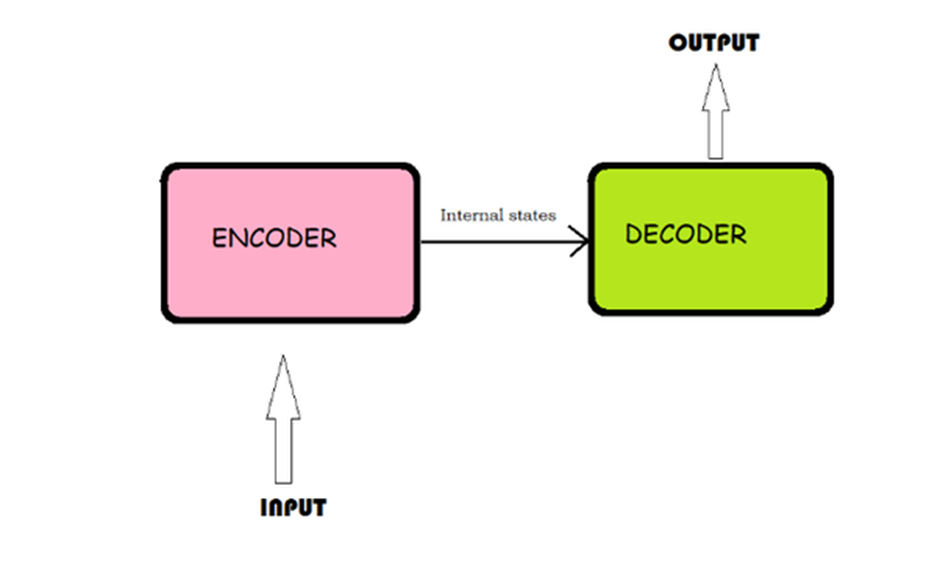
- Encoder: An encoder is an artificial neural network that converts the input image into a latent space representation and encodes it as a compressed representation in a lower dimension. Distortion on the original image is unavoidable as part of this process.
- Code: Reduced input data is stored in the memory of this module.
- Decoder: The decoder is the part of this network that makes the decoded language readable by putting the code back together to its original order.
2 – what are the applications of autoencoders?
Autoencoders are neural networks that have a single hidden layer. They can be used for dimensionality reduction and feature extraction, which is useful for machine learning models that have limited capacity or need to process large datasets quickly.
Autoencoders are applied in different fields. They can be used for image recognition and noise removal, as well as for security purposes like fingerprint verification or face recognition.
Autoencoders are used in a wide range of applications, such as image compression, computer vision, natural language processing, and machine translation.
- Image Denoising: Image denoising refers to removing noise in images. Autoencoders (machine learning models) can be trained to learn how to find and undo noise, which is useful for when an image has some amount of variation/noise in it.
- Dimensionality Reduction: The input is converted into a reduced representation by the autoencoders, which is stored in the middle layer called “code”. The information from the input has been compressed and each node is treated as a variable. As a result, we can deduce that by removing the decoder, an autoencoder can be used for dimensionality reduction. The coding layer would then have to act as an output.
- Feature Extraction: The encoding section of Autoencoders aids in the learning of crucial hidden features present in the input data, lowering the reconstruction error. During encoding, a new collection of original feature combinations is created.Image Colorization: Autoencoders encode the important hidden features present in input data, which can greatly reduced reconstruction error. During encoding, a new collection of original feature combinations are created that convert a black-and-white image to colored one. We can also convert a colourful image to grayscale.
3 – What is cost function?
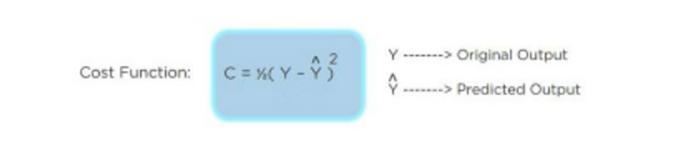
The Cost Function is an important component in Deep Learning, which is why it’s crucial to understand what it does and how it functions. The Cost Function determines the value of an action and updates the weights accordingly. It’s essentially the driving force behind Deep Learning because it tells us whether or not we’re on the right track.
4 – What Is the Difference Between Epoch, Batch, and Iteration in Deep Learning?
Epoch: Epochs are the steps in which the system learns to identify patterns. After each epoch, the model is evaluated and then improved before moving on to the next epoch.
Batch: A batch refers to all of the data that goes into one step of training during an epoch.
Iteration: Iterations refer to how many times an epoch has been completed.
5 – What is Data Augmentation in Deep Learning?
Data augmentation is an important part of the training process for deep learning models. It involves adding synthetic data to the original set, which will help to improve the performance of these models. This technique is used when we want to improve our model’s accuracy in a specific domain.
Data augmentation is also used as a way to make sure that our model generalizes well and can be applied on unseen data sets.
This technique improves the performance of neural networks by making it more robust and accurate. It also helps in reducing overfitting, which occurs when our model learns too much from its training dataset and fails to generalize well on unseen data sets.
