1 – What is F1 score?
F1 score is a measure of the accuracy of a model. It is defined as the harmonic mean of precision and recall.
F1 score is one of the most popular metrics for assessing how well a machine learning algorithm performs on predicting a target variable. F1 score ranges from 0 to 1, with higher values indicating better performance.
The F1 score is used to evaluate the performance of a machine learning algorithm by considering how many times it has classified correctly and how many times it has misclassified.
The higher the F1 score, the better the performance of an algorithm.
2 – What is pickling and unpickling?
Pickling is the process of converting an object into a string representation. It can be used to store the object in a file, send it over a network, or save it to disk.
Unpickling is the inverse process of pickling. It converts an object from its string representation back into an object.
Pickling and unpickling can be done with machine learning by using an algorithm that converts the input to the output.
3 – Difference between likelihood and probability?
Probability is a measure of the likelihood of an event happening under certain conditions. The event can be a machine learning algorithm predicting the probability that a person will buy a product or not.
Likelihood is the probability that an event will happen, based on evidence and knowledge about the world. For example, if you see someone who looks like they are going to rob you and you know that they have robbed other people in the past, your likelihood of being robbed is high.
4 – Which machine learning algorithm known as a lazy learner?
KNN is a machine learning algorithm known as a lazy learner. K-NN is a lazy learner because it doesn’t learn any machine learnt values or variables from the training data but dynamically calculates distance every time it wants to classify, hence memorizes the training dataset instead.
5 – How to fix multicollinearity?
Multicollinearity is a statistical problem that arises when two or more independent variables are highly correlated.
One way to fix multicollinearity is to use a different variable that has less correlation with the other variables. If there are not any other variables available, one can use a transformation on the original variable and then re-run the regression.
6 – Significance of gamma and Regularization in SVM?
The significance of gamma and regularization in SVM is that they are used to control the trade-off between the training error and the generalization error. In other words, these two parameters are used to balance the bias-variance trade-off.
Regularization is a technique to reduce overfitting by penalizing models with more complexity than necessary. The goal of regularization is to find a model that has good generalization performance, which means it can correctly predict new data points with high accuracy. On the other hand, gamma is a parameter that controls how much weight should be given to each training example.
The gamma parameter is used for tuning the level of regularization in support vector machines. A larger value of gamma will lead to more regularized models, while a smaller value will lead to less regularized models.
SVM’s can be trained with different levels of regularization using the gamma parameter by adding an additional term to the cost function.
7 – Is ARIMA model a good fit for every time series problem?
ARIMA is a powerful tool for time series forecasting, but it is not the only one. In fact, there are many models that can be used to solve time series problems.
ARIMA is a popular choice for many companies and organizations because it has been shown to work well in most cases. However, the problem with ARIMA is that it cannot be applied to all types of data and problems.
ARIMA can be useful in the following cases:
- When there are trends in the data and you want to take them into account
- When there are seasonal patterns in your data and you want to account for them
- When there are outliers in your data and you want to get rid of them
- When there are changes in the level of seasonality over time (e.g. when summer has become more popular than winter)
8 – What is an OOB error and how is it useful?
An OOB error is an out of bag error. It can be useful in machine learning because it can provide a more accurate modelling of the distribution.
An OOB error is a subset of an error. It occurs when the algorithm encounters a new data point (example: new word) that it has not seen before and it predicts something incorrect. This type of error can be useful because it helps to identify the areas where the algorithm needs to be improved.
9 – How do you measure the accuracy of a Clustering Algorithm?
Clustering algorithms are a type of unsupervised machine learning algorithm. They group data points together into clusters based on their similarity.
The accuracy of a clustering algorithm can be measured in two ways:
- The percentage of records that are correctly assigned to the correct cluster.
- The percentage of records that are assigned to the correct cluster and the percentage that are not assigned to any cluster at all.
The first way is better because it shows how accurate the clustering algorithm is in finding similar records, while the second way does not show how accurate it is in assigning records to clusters.
10 – What is Matrix Factorization and where is it used in Machine Learning?
Matrix factorization is a technique in machine learning which decomposes a matrix into two or more matrices. The purpose of this technique is to extract the latent factors of the original matrix. Matrix factorization can be used in various fields such as image processing, natural language processing and social network analysis.
In image processing, it is used to reconstruct an image from its parts. This can be done by decomposing the original image into three matrices: one containing only rows with even pixel values, one containing only rows with odd pixel values and one containing only columns with even pixel values. The reconstruction of the original image from these matrices can then be done by multiplying them together.
In natural language processing, it is used for text understanding and sentiment analysis. It can extract topics and sentiments from sentences, which is done by decomposing the input sentence into words and sentences. In social network analysis, it can extract sociometric features from social networks. It does this by decomposing a node in the network into three matrices: a matrix with only its direct connections, one with only its indirect connections and a matrix containing all of the nodes.
11 -What is Named Entity Recognition (NER)?
Named entity recognition is a process that extracts the names of people, organizations, locations, and other entities from unstructured text.
Named entity recognition is a process that extracts the names of people, organizations, locations, and other entities from unstructured text. It is also known as named entity extraction or identification. The goal of this process is to identify all entities in a document and their properties.
12 – How is feature extraction done in NLP?
Feature extraction is a process of extracting features from raw text data. It can be done by the use of machine learning algorithms.
The process of feature extraction is achieved by performing a series of steps that involve tokenization, normalization, and tagging.
Tagging includes assigning categories to words or phrases in the text data like person, place, time and other linguistic information.
This information helps in understanding the context of the text data and its relationship with other words or phrases that are used in it.
13 – Name some popular models other than Bag of words?
There are many models other than Bag of words. Some of the most popular ones are:
- Latent Semantic Analysis (LSA)
- Word2vec
- Deep Learning with Convolutional Neural Network (CNN)
- Recurrent Neural Network (RNN)
14 – Explain briefly about Word2Vec?
Word2vec is a machine learning algorithm that is used for natural language processing. It allows computers to learn how words are related to each other by looking at examples of text. This algorithm is used for many different tasks like sentiment analysis, information retrieval, and machine translation. Its applications range from basic personal information to scientific studies. The algorithm takes in a sentence as input, then produces a length-based vector representation of the sentence. The elements in this representation are numbers that represent the length of sequences of characters that match the sentence. The algorithm then returns a vector containing all the word lengths, where each entry is a set of length-based representations of the words that match the sentence. The algorithm takes in a sentence as input, then produces a vector representation of the sequence at each position. The elements in this representation are numbers that represent the number of consecutive, identical characters at each position within the string.
15 – What is Latent Semantic Indexing?
Latent Semantic Indexing (LSI) is a technique used by search engines to understand the meaning of words and phrases in a large body of text. LSI is an advanced form of indexing that uses statistical techniques to find relationships between words and phrases in a document that are not explicitly stated.
This software breaks texts down into coherent components by identifying which terms are most closely related to a certain concept. This method applies linear algebra to the term-document matrix. As the name suggests, in this matrix the words are on rows and the document is on columns.
LSI is computation heavy when compared to other models but it equips an NLP model with better contextual awareness which makes it relatively closer to NLU.
16 – What are the metrics used to test an NLP model?
The metrics used to test an NLP model are the precision, recall and F-score. Precision measures how many relevant results are retrieved from the dataset. Recall measures how many of those relevant results were retrieved by the algorithm. F-score is a combination of both precision and recall which takes into account both the number of relevant items found as well as their relevancy to the query.
17 – What are some popular Python libraries used for NLP?
Natural language processing is a field of artificial intelligence that seeks to understand and generate natural language. There are many Python libraries used for NLP, some of which are listed below:
NLTK – It is a leading platform for building Python programs to process human language data. It provides easy-to-use interfaces, combined with powerful tools and high-quality documentation. NLTK is written in pure Python and runs on all major platforms.
Gensim – Gensim is an open-source library for topic modelling, document indexing, similarity retrieval, machine learning on large text corpora, topic modelling and semantic hashing. Gensim has been designed for ease of use with a simple interface while still being fast and memory efficient.
Spacy – Spacy offers the most natural and intuitive interface for data scientists to interact with their data. It provides state of the art NLP tools in an easy-to-use Python library. We focus on creating a clean, beautiful, and consistent interface for your raw data – making it easier to explore its features and extract meaningful insights.
18 – What do you know about Dependency Parsing?
Dependency parsing is a task of natural language processing. It is a technique for identifying the syntactic structure of sentences in a natural language from the words that are used.
Dependency parsing can be used to find syntactic dependencies between words, phrases and clauses in a sentence. This can be useful for analysing texts and finding out information about the sentence such as who did what to whom, when, where and why.
The dependency parser will analyze these dependencies for you and it will also provide you with the best way to express them in your sentence.
19 – What is perplexity in NLP?
Perplexity is a measure of how well a model predicts the next word in sequence. It is used to assess the performance of natural language processing (NLP) models.
The perplexity score for an NLP model can be calculated by dividing the number of correct predictions by the total number of predictions made.


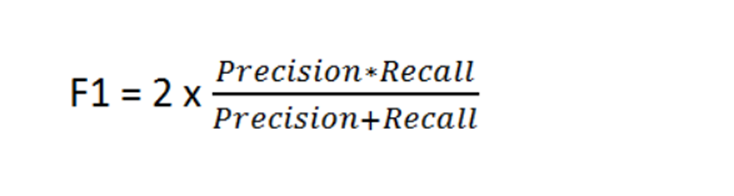
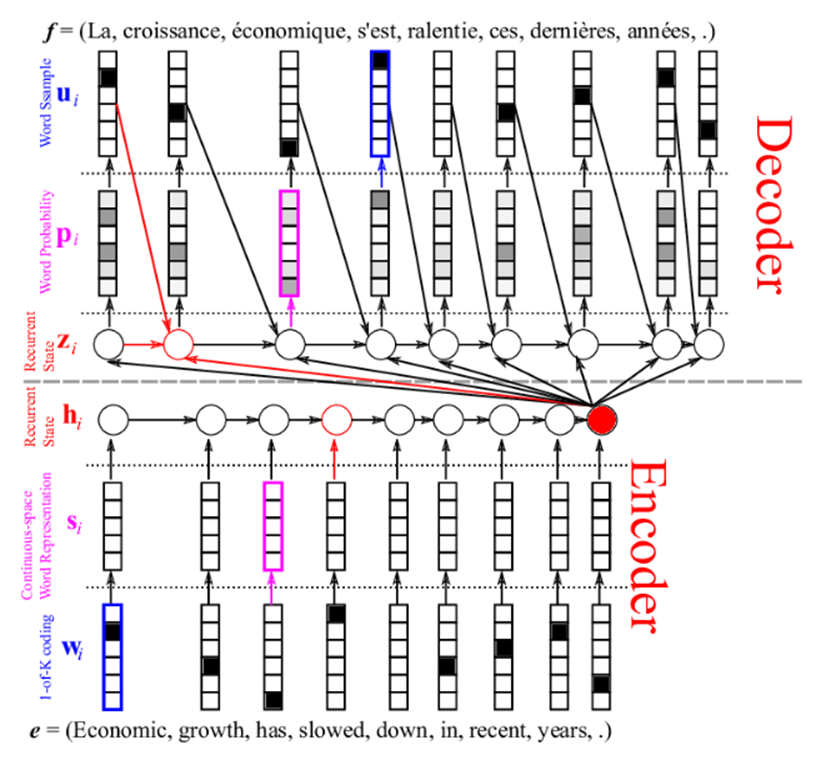
20 – How has Translation of words improved from the Traditional methods?
In the probabilistic models, we had to convert our words into different text using multiple statistical models like the Bayesian rule. It sounds like there are a lot of challenges with designing the system to handle such complex problems.
Neural Machine Translation is a process of modeling this all through a big artificial neural network. The network used is the Recurrent Neural Network which is a stateful neural network One of the most popular types of NMT is the “standard” Neural Machine Translation. Here, encoder RNNs encode the source sentence and decoders decode these to predict words in the target language.
21 – How to know whether your model is suffering from the problem of Exploding Gradients?
Certain signs such as those mentioned may point towards exploding gradients. These can include:
- The model is unable to get traction on your training data (e.g. poor loss)
- The model is unstable and suffers from sizable changes in loss in consecutive updates.
- Our model losses are not greater than NaN during training.
If you have these types of problems, you can dig deeper to see if you have a problem with exploding gradients. There are some less subtle signs that you can use to confirm that you have exploding gradients:
- The model weights quickly become very large during training.
- The model weights go to NaN values during training.
- The error gradient values are consistently above 1.0 for each node and layer during training.
22 – How to know whether your model is suffering from the problem of Vanishing Gradients?
The model will improve very slowly during the training phase and it is also possible that training stops very early, meaning that any further training does not improve the model.
The weights closer to the output layer of the model would witness more of a change whereas the layers that occur closer to the input layer would not change much (if at all).
Model weights shrink exponentially and become very small when training the model.
The model weights become 0 in the training phase.
23 – Explain the following variant of Gradient Descent: Stochastic, Batch, and Mini-batch?
Batch Gradient Descent is the most commonly used algorithm for training deep neural networks. It trains the network by updating the weights and biases in each layer of the network after every mini-batch of data.
Stochastic Gradient Descent (SGD) is a variant of Batch Gradient Descent that updates the weights and biases after every training example.
Mini-batch Gradient Descent is a variant that updates the weights and biases after every nth example in a mini-batch, rather than after every single example.
24 – What are the main benefits of Mini-batch Gradient Descent?4 – What are the main benefits of Mini-batch Gradient Descent?
- Deep learning is powerful, but it’s not perfect. It’s computationally efficient, though, which makes it viable when trying to characterize large datasets or handle large models.
- If you control the number of ticks at each node, then you can expect this optimization to produce an optimized result.
- Optimizers have become a popular topic in many ML communities. They are key in improving convergence and help you avoid getting stuck at local minima.
25 – What do you understand by a convolutional neural network?
A convolutional neural network is a type of deep learning architecture. It is a feed-forward artificial neural network that has the ability to learn by analyzing and recognizing patterns in data.
The architecture of a convolutional neural network is based on the structure of the visual cortex in mammals, where different parts have specialized functions. The first layer of a convolutional neural network analyzes an image at a low level, such as distinguishing edges and colors. The second layer may combine information from both the first layer and other layers to form more complex features, such as shapes or objects.
26 – Explain the different layers of CNN.
It’s important to understand the four layers that make up a CNN:
- Convolution This layer comprises of a set of independent filters. All these filters are initialized randomly. These filters then become our parameters which will be learned by the network subsequently.
- ReLU The ReLU layer is used with the convolutional layer.
- Pooling This layer reduces the spatial size of representation so that it will require less parameters and computation. It only operates on information from one feature map at a time.
- Full Collectedness Neural networks with a full connection between layers are able to compute and propagate any activation from one layer to the next due to the complete connection. They can be calculated by a matrix multiplication and bias offset.
27 – What is an RNN?
A recurrent neural network is a type of artificial neural network that is composed of many layers. This type of neural network has the ability to learn sequential patterns in data. It can be used for various tasks, such as machine translation, speech recognition, and image captioning.
28 – What do you understand by Deep Autoencoders?
Deep Autoencoders are neural networks that are trained to produce a specific output. They can be used for natural language processing, image processing, and other machine learning tasks.
The deep autoencoder is trained in an unsupervised manner by feeding it with input data and then comparing the input data to its own output. The autoencoder uses backpropagation to adjust its weights so that the difference between input and output is minimized. This process of adjusting weights is called “training” which may take a number of iterations depending on the complexity of the problem being solved.
Deep autoencoders are used in many tasks such as:
1 – Natural Language Processing
2 – Image Processing
3 – Speech Recognition
4 – Machine Translation
29 – What do you understand by Perceptron? Also, explain its type?
A perceptron is an artificial neuron that does computations to detect features. Unsupervised learning is a type of machine intelligence that helps algorithms learn and process information without any human interference.
There are two types of perceptrons:
- Single-Layer Perceptron Single-layer neural networks learn only linearly separable patterns.
In the early days of deep learning, single layer perceptrons were a popular choice. They are not able to learn non-linear patterns and are limited to linearly separable patterns. - Multilayer Perceptrons Multilayer neural networks with 2 or more layers usually have a higher processing power than those with 1 layer.
Multilayer perceptrons or feedforward neural networks with two or more layers have the higher processing power. They are most commonly used in applications such as image recognition and image processing, speech recognition, natural language processing and machine translation.
30 – Explain the importance of LSTM.
LSTM is a type of recurrent neural network that is used to process sequential data. It is used in natural language processing and machine translation.
LSTM has been around for a while, but it has not been until recently that it has become more widely known about. This is because of its ability to process sequential data and the fact that it can be used with deep learning. It is a type of recurrent neural network that was originally designed for sequence-to-sequence prediction tasks. it can be used to predict the next word in a sequence given previous words in the sequence.
One way to use LSTM is to generate text. It can be used to generate text based on input parameters like sentence length, vocabulary size, and other factors.
31 – Explain why mirroring, random cropping, and shearing are some.
Mirroring, random cropping, and shearing are some techniques that can help in a computer learning problem. Mirroring is a technique where the image is mirrored before it is fed to the algorithm. Random cropping is when the image is cropped randomly before feeding it to the algorithm. Shearing, on the other hand, involves rotating and scaling the image before feeding it to the algorithm. We can use these techniques to increase our training data .
These techniques are ways for a machine to learn how to identify objects that have been distorted or altered from their original form. This can be done with a machine learning algorithm that is trained on labelled data, or with a neural network. Colorization This technique of converting pixel color values to RGB values from an image often used by artists and designers.
32 – Mention a method that can be used to evaluate an object localization model. What is it?
The intersection over union (also known as IoU) is a method commonly used to assess the performance of object localization models. The proportions of the overlapping area and the predicted area are calculated. If this ratio called the IoU (indicator of understanding) is found greater than some threshold, the prediction of the model is considered correct.
33 -What is the basis of the state-of-the-art object detection algorithm YOLO?
YOLO stands for You Only Look Once and is a state-of-the-art object detection algorithm. It uses two deep neural networks to detect objects in an image and is also capable of generating predictions for the location of those objects in subsequent frames.
YOLO has been used in various applications like autonomous driving, robotics, surveillance, and video games.
34 – What are the main steps in a typical Computer Vision pipeline?
They work in a cyclical fashion, meaning they will acquire images, process these images and extract information from them. All this data is processed before making a prediction.
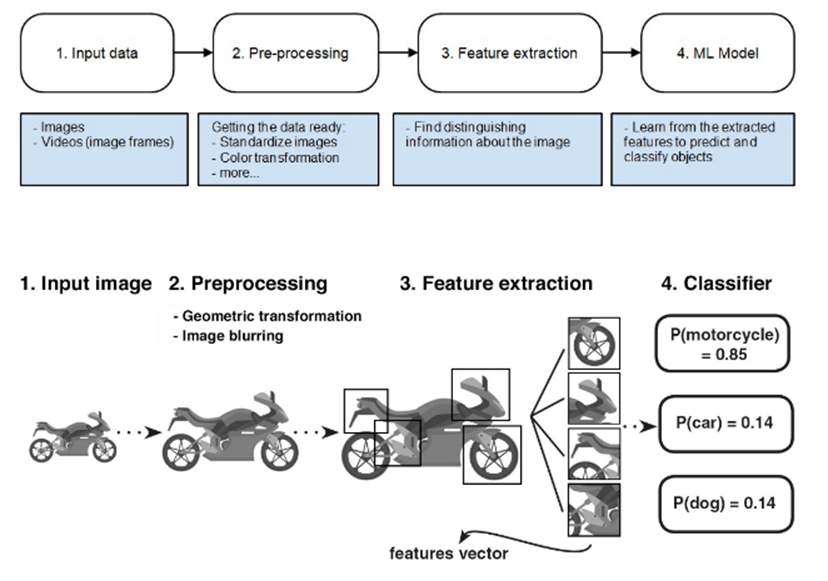
- Input image: a computer receives a visual input from an imaging device like a camera. This is typically captured as an image or a sequence of images forming a video.
- Pre-processing: Images are pre-processed to ensure they all conform to the same level of quality. Before comparing different images, we must first make sure to standardize each of the images. This includes resizing, blurring, rotating them and transforming them from one color space to another.
- Next, comes Feature extraction. Features determine, or help us distinguish between different objects. They usually include information about an object’s shape and size. Features that might distinguish a wheel from other motorcycle components could be its shape or the design of its headlight, for example. The output of this process is a features vector which is a list of unique shapes that identify the object
- Finally, the vector of features from the previous step is fed into an ML model. In this example, a classification model looks at these features and attempts to predict what kind of image you’re looking at. This is a clear sign of the dog being less probable than a motorcycle.
To improve the accuracy, we may need to do more of step 1 (acquire more training images) or step 2 (more processing to remove noise) or step 3 (extract better features) or step 4 (change the classifier algorithm and tune some hyperparameters or even more training time). Many different approaches can improve the performance of the model. They all lie in one or more of the pipeline steps.
35 – What is the difference between Semantic Segmentation and Instance Segmentation in Computer Vision?
- Semantic Segmentation Object detection is a technique that, for each pixel, identifies what object it belongs to. This is done with the help of a model that receives labels of what kind of objects exist (each label corresponds to one kind of object) and matches them to their representation in the data.
- Instance Segmentation, Semantic Understanding works in a similar way to Semantic Segmentation, but dives a bit deeper. It identifies for each pixel, the object instance it belongs to. The main difference is that they can differentiate between two objects with identical labels where semantic segmentation cannot. For example:
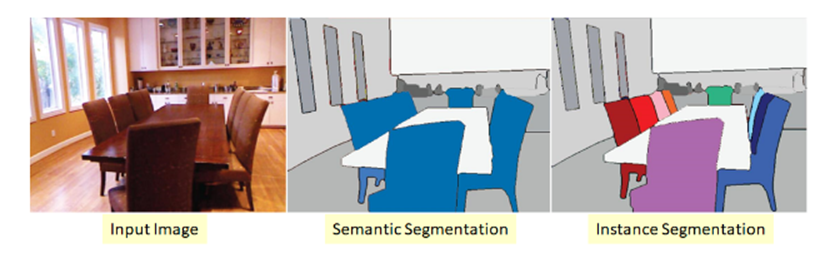
- in the second image where Semantic Segmentation is applied, the category (chair) is one of the outputs, all chairs are colored the same.
- In the third image, the Instance Segmentation, goes a step further and separates the instances (the chairs) from one another apart from identifying the category (chair) in the first step.
36 – How does Image Registration work?
Image registration is a technique that is used to align two images together. This technique can be used in many different fields such as medical imaging, remote sensing, and robotics.
Image registration is done using a variety of techniques. The most common techniques are template matching, affine transformation, and rigid body transformation.
Template matching is the simplest form of image registration. It works by searching for the best match between two images and then aligning them accordingly. Affine transformations are slightly more complex than template matching but they offer better results because they take into account how each pixel will change in both images when they are aligned together. Rigid body transformations are the most complex form of image registration but it offers the best results because it takes into account how every pixel will change when aligned together with any other pixel in the image.

37 – What Image Noise Filters techniques do you know?
Image noise filters are a set of algorithms that remove noise from images. They are used to clean up low-quality images and make them more presentable.
Median filter – Median filters work by averaging the pixels in a given area and replacing them with the average color. They are often used as an alternative to high-pass and low-pass filters, which are more computationally expensive. Median filters can be helpful in removing noise from images without significantly impacting the sharpness of edges.

Gaussian filter – Gaussian filters work by smoothing out gradients in an image. They do this by taking the sum of its neighboring pixels and then multiplying it by a small number. The result is that any sudden changes are smaller, so the image appears more uniform. This is useful for removing noise from images, especially in low-light environments where the camera sensor has trouble capturing details.

Laplacian filter – Laplacian filters are extremely beneficial for data sets that have a lot of noise. The filters are used to eliminate the noise in an image and make it easier to see the underlying patterns in the data.
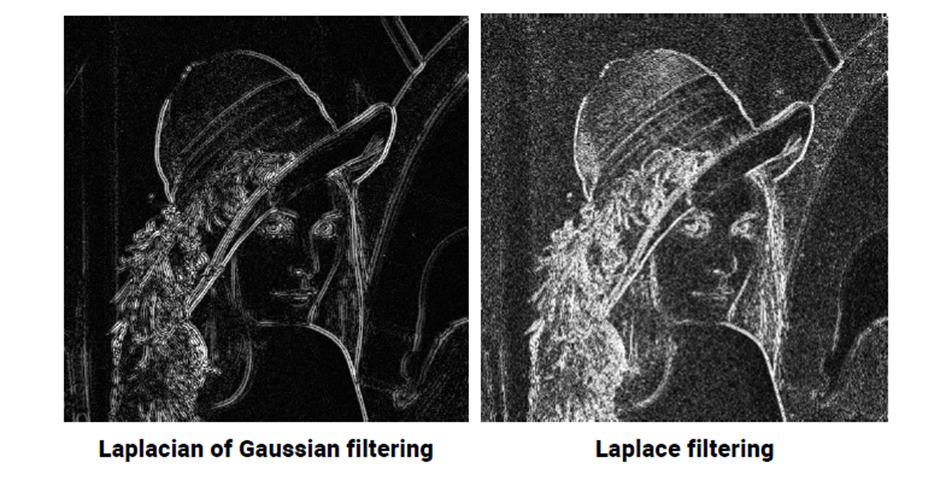
38 – What Image Thresholding methods do you know?
Image thresholding is a method of segmenting an image into different regions. There are many methods that can be used to accomplish this task and these methods are not mutually exclusive. They can be combined together to provide the best results in different scenarios.
Otsu – A common problem in image processing is to separate a given image into multiple regions sharing similar properties. One method for achieving this goal is the Otsu’s method, which finds the optimum threshold value by maximizing the variance within classes while minimizing the variance between classes.
K-means cluster – The K-means clustering is a simple, yet powerful algorithm that takes a set of pixels and assigns them to one of K clusters based on their brightness values. The idea behind the algorithm is that pixels in the same cluster are more similar to each other in some way than to pixels in other clusters.
Image thresholding – In the field of image processing, adaptive thresholding is a method for determining the threshold for separating a black or white pixel from a grey one. It works by using a variable threshold for each pixel based on its local density or its distance from another pixel.
39 – What is the difference between Feature Detection and Feature Extraction?
Feature detection and extraction are two important steps in computer vision.
Feature detection is the process of locating potential features within an image, The process of feature detection is to scan an image for the presence of certain features. This can be used in a variety of applications such as facial recognition, detecting a human in a video feed, and more.
whereas Feature extraction is the process of identifying the properties of those features. Feature extraction is important because it can help us make better decisions. For example, if a company needs to decide which product to manufacture, they could extract features from each product and compare the results. This would be much more efficient than comparing all products in one go.
40 – How to detect Edges in an image?
Edge detection is a process of finding edges in an image. Edges are points where the intensity changes rapidly.
There are many algorithms which can be used for edge detection. Some of them are:
1 – Canny edge detector
2 – Sobel operator
3 – Prewitt operator
4 – Roberts cross operator
The first step is to convert the input image into a grayscale image. The next step is to use Sobel operator on the grayscale image and then take the gradient magnitude. The final step is to find the edges by comparing gradients with a threshold value.
