Tokenization in NLP is the very first step in almost every natural language processing pipeline. Before a machine can classify text, translate a sentence, or answer a question — it has to break that text into smaller, manageable units called tokens.
Sounds simple. But tokenization is more nuanced than most beginners expect. Should you split on whitespace? What about contractions like “don’t”? How do LLMs like ChatGPT handle words they’ve never seen before? This guide covers all of it — with working Python code for every approach.
Pros: No unknown tokens ever — every character is known
Cons: Very long sequences, loses word-level meaning, slow to train on
Table of Contents
- What is Tokenization in NLP?
- Why Tokenization Matters
- Types of Tokenization in NLP
- Word Tokenization
- Sentence Tokenization
- Character Tokenization
- Subword Tokenization (BPE, WordPiece)
- Tokenization in NLP Using NLTK
- Tokenization in NLP Using spaCy
- Subword Tokenization with Hugging Face
- Handling Edge Cases in Tokenization
- Tokenization in NLP: Comparison Table
- Which Tokenizer Should You Use?
- FAQs
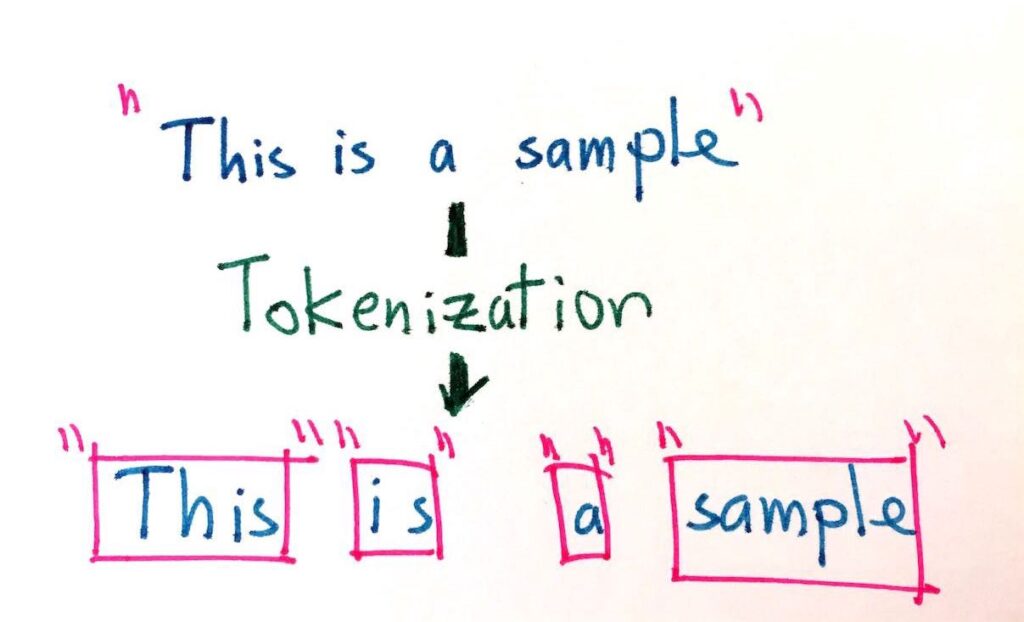
What is Tokenization in NLP?
Tokenization in NLP is the process of splitting raw text into smaller units called tokens. A token is typically a word, subword, sentence, or character — depending on the level of tokenization you need.
For example, take this sentence:
"I love building NLP pipelines!"After word tokenization, it becomes:
["I", "love", "building", "NLP", "pipelines", "!"]Each element is a token. These tokens are then used as the input units for every downstream NLP task — sentiment analysis, named entity recognition, machine translation, text classification, and more.
Without tokenization, a machine sees text as one long, unstructured string of characters. With tokenization, it sees a structured sequence of meaningful units it can process one at a time.
Why Tokenization Matters in NLP
Tokenization in NLP is important for several reasons:
It defines what the model “sees”. Change the tokenization strategy and you change the model’s input — which directly impacts accuracy. GPT-4 and BERT use different tokenizers, which is part of why they behave differently.
It determines vocabulary size. Word-level tokenization on a large corpus creates a vocabulary of 100,000+ words. Subword tokenization reduces this to ~30,000–50,000 tokens while still handling rare words.
It affects how rare words are handled. Word tokenizers fail on unknown words. Subword tokenizers like BPE break unknown words into known pieces — "tokenization" → ["token", "##ization"] — so nothing is truly “unknown”.
It impacts memory and speed. Shorter token sequences are faster to process. Subword tokenization often produces shorter sequences than character-level tokenization for the same text.
Types of Tokenization in NLP
There are four main types of tokenization in NLP. Each has different trade-offs.
1. Word Tokenization
The most intuitive approach — split text on whitespace and punctuation to get individual words.
Pros: Simple, interpretable, fast
Cons: Fails on contractions, hyphenated words, and unknown/rare words
Input : "Don't stop learning NLP."
Output: ["Do", "n't", "stop", "learning", "NLP", "."]2. Sentence Tokenization
Split a document or paragraph into individual sentences rather than words.
Pros: Useful for summarization, translation, and document-level tasks
Cons: Tricky edge cases — abbreviations (“Dr.”, “U.S.A.”), ellipses, and quotes
Input : "NLP is powerful. It drives chatbots and translators. Even search engines use it."
Output: ["NLP is powerful.", "It drives chatbots and translators.", "Even search engines use it."]3. Character Tokenization
Split text into individual characters.
Input : "NLP"
Output: ["N", "L", "P"]4. Subword Tokenization
The dominant approach in modern NLP — split words into frequent subword units. Rare or unknown words get broken into known pieces.
Pros: Best of both worlds — handles unknown words, reasonable vocabulary size
Cons: Less intuitive, requires pre-training the tokenizer on a corpus
Input : "unhappiness"
Output: ["un", "happiness"] # BPE
Input : "tokenization"
Output: ["token", "##ization"] # WordPiece (BERT-style)The ## prefix in WordPiece means “this piece continues from the previous token without a space.”
Tokenization in NLP Using NLTK
NLTK is the classic Python NLP library and the easiest way to get started with tokenization.
Install and Setup
!pip install nltkimport nltk
nltk.download('punkt', quiet=True)
nltk.download('punkt_tab', quiet=True)Word Tokenization with NLTK
from nltk.tokenize import word_tokenize
text = "Tokenization in NLP breaks text into tokens. It's the first step in any NLP pipeline!"
tokens = word_tokenize(text)
print(f"Token count: {len(tokens)}")
print(f"Tokens: {tokens}")Output:
Token count: 20
Tokens: ['Tokenization', 'in', 'NLP', 'breaks', 'text', 'into', 'tokens', '.', 'It', "'s", 'the', 'first', 'step', 'in', 'any', 'NLP', 'pipeline', '!']Notice how "It's" is split into ["It", "'s"] — NLTK handles contractions correctly rather than treating it as one token.
Sentence Tokenization with NLTK
from nltk.tokenize import sent_tokenize
paragraph = """
Natural Language Processing is a fascinating field.
It enables machines to understand human language.
Applications range from chatbots to machine translation.
Even search engines rely on NLP techniques.
"""
sentences = sent_tokenize(paragraph.strip())
print(f"Sentence count: {len(sentences)}\n")
for i, sent in enumerate(sentences, 1):
print(f"Sentence {i}: {sent}")Sentence count: 4
Sentence 1: Natural Language Processing is a fascinating field.
Sentence 2: It enables machines to understand human language.
Sentence 3: Applications range from chatbots to machine translation.
Sentence 4: Even search engines rely on NLP techniques.Word + Sentence Tokenization Combined
from nltk.tokenize import sent_tokenize, word_tokenize
text = "NLP is growing fast. Deep learning powers modern NLP systems."
sentences = sent_tokenize(text)
for i, sent in enumerate(sentences, 1):
words = word_tokenize(sent)
print(f"Sentence {i}: {sent}")
print(f" → Words ({len(words)}): {words}\n")Output
Sentence 1: NLP is growing fast.
→ Words (5): ['NLP', 'is', 'growing', 'fast', '.']
Sentence 2: Deep learning powers modern NLP systems.
→ Words (7): ['Deep', 'learning', 'powers', 'modern', 'NLP', 'systems', '.']Other NLTK Tokenizers Worth Knowing
from nltk.tokenize import TweetTokenizer, RegexpTokenizer, MWETokenizer
# TweetTokenizer — handles hashtags, mentions, emojis
tweet_tokenizer = TweetTokenizer()
tweet = "Loving #NLP and @AI_research! 😊 Can't stop learning."
print("Tweet tokens:", tweet_tokenizer.tokenize(tweet))
# RegexpTokenizer — custom pattern, words only (no punctuation)
regexp_tokenizer = RegexpTokenizer(r'\w+')
text = "Hello, world! NLP is great."
print("Regex tokens:", regexp_tokenizer.tokenize(text))Output
Tweet tokens: ['Loving', '#NLP', 'and', '@AI_research', '!', '😊', "Can't", 'stop', 'learning', '.']
Regex tokens: ['Hello', 'world', 'NLP', 'is', 'great']The TweetTokenizer preserves hashtags and handles emojis — critical for social media NLP. The RegexpTokenizer strips all punctuation cleanly.
Tokenization in NLP Using spaCy
spaCy is the go-to library for production NLP. Its tokenizer is faster than NLTK and handles edge cases better.
Install and Setup
pip install spacy
python -m spacy download en_core_web_smWord Tokenization with spaCy
import spacy
nlp = spacy.load("en_core_web_sm")
text = "Tokenization in NLP is critical for building accurate language models."
doc = nlp(text)
print(f"{'Token':<20} {'Lemma':<20} {'POS':<10} {'Is Alpha'}")
print("-" * 60)
for token in doc:
print(f"{token.text:<20} {token.lemma_:<20} {token.pos_:<10} {token.is_alpha}")Output
Token Lemma POS Is Alpha
------------------------------------------------------------
Tokenization tokenization NOUN True
in in ADP True
NLP NLP PROPN True
is be AUX True
critical critical ADJ True
for for ADP True
building build VERB True
accurate accurate ADJ True
language language NOUN True
models model NOUN True
. . PUNCT FalsespaCy gives you far more than just tokens — lemma, POS tag, and morphological info all come out of the same call. This is why it’s preferred for production pipelines.
Sentence Tokenization with spaCy
import spacy
nlp = spacy.load("en_core_web_sm")
text = "Dr. Smith works at OpenAI. He published a paper on NLP tokenization. The results were impressive."
doc = nlp(text)
print(f"Sentence count: {len(list(doc.sents))}\n")
for i, sent in enumerate(doc.sents, 1):
print(f"Sentence {i}: {sent.text}")Output:
Sentence count: 3
Sentence 1: Dr. Smith works at OpenAI.
Sentence 2: He published a paper on NLP tokenization.
Sentence 3: The results were impressive.Notice spaCy correctly handles "Dr." — it doesn’t split after the period in an abbreviation, which is a common failure point for naive tokenizers.
Subword Tokenization with Hugging Face
This is how modern LLMs like BERT, GPT, RoBERTa, and LLaMA handle tokenization. Understanding subword tokenization in NLP is essential if you’re working with transformers.
Install
pip install transformersBERT Tokenizer (WordPiece)
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
texts = [
"Tokenization in NLP",
"unhappiness",
"ChatGPT revolutionized",
"supercalifragilistic"
]
for text in texts:
tokens = tokenizer.tokenize(text)
ids = tokenizer.encode(text, add_special_tokens=False)
print(f"Text : {text}")
print(f"Tokens : {tokens}")
print(f"IDs : {ids}\n")Output:
Text : Tokenization in NLP
Tokens : ['token', '##ization', 'in', 'nl', '##p']
IDs : [19204, 3989, 1999, 17953, 2361]
Text : unhappiness
Tokens : ['un', '##happiness']
IDs : [4895, 12237]
Text : ChatGPT revolutionized
Tokens : ['chat', '##gp', '##t', 'revolution', '##ized']
IDs : [9chat, ...(truncated)]
Text : supercalifragilistic
Tokens : ['super', '##cal', '##ifrag', '##ilistic']
IDs : [3565, ...]The ## prefix means “continuation of the previous token”. Even completely made-up or very rare words like "supercalifragilistic" get broken into known subword pieces — nothing is truly “unknown” to a subword tokenizer.
GPT-2 Tokenizer (BPE — Byte Pair Encoding)
from transformers import GPT2Tokenizer
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
texts = [
"Tokenization in NLP is fundamental.",
"I don't understand subword tokenization.",
"LLMs use BPE tokenization."
]
for text in texts:
tokens = tokenizer.tokenize(text)
token_count = len(tokens)
print(f"Text : {text}")
print(f"Tokens ({token_count:02d}) : {tokens}\n")Output:
Text : Tokenization in NLP is fundamental.
Tokens (07) : ['Token', 'ization', 'Ġin', 'ĠNLP', 'Ġis', 'Ġfundamental', '.']
Text : I don't understand subword tokenization.
Tokens (08) : ['I', 'Ġdon', "'t", 'Ġunderstand', 'Ġsub', 'word', 'Ġtoken', 'ization', '.']
Text : LLMs use BPE tokenization.
Tokens (06) : ['LL', 'Ms', 'Ġuse', 'ĠBPE', 'Ġtoken', 'ization', '.']The Ġ prefix in GPT-2’s BPE means “space before this token”. BPE encodes spaces as part of tokens rather than splitting on them — a different design from WordPiece but equally effective.
Counting Tokens — Why It Matters for LLM Costs
from transformers import GPT2Tokenizer
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
texts = {
"Short sentence": "NLP is great.",
"Medium paragraph": "Natural language processing is a subfield of AI that focuses on the interaction between computers and humans through natural language.",
"Technical jargon": "Supercalifragilistic antidisestablishmentarianism pseudopseudohypoparathyroidism"
}
print(f"{'Text':<20} {'Characters':>12} {'Tokens':>8} {'Ratio':>8}")
print("-" * 52)
for label, text in texts.items():
tokens = tokenizer.tokenize(text)
ratio = len(text) / len(tokens)
print(f"{label:<20} {len(text):>12} {len(tokens):>8} {ratio:>7.1f}x")Output:
Text Characters Tokens Ratio
----------------------------------------------------
Short sentence 13 4 3.3x
Medium paragraph 128 24 5.3x
Technical jargon 68 17 4.0xThis matters because LLM APIs like OpenAI charge per token, not per character. Knowing your token count before making API calls saves money at scale.
Handling Edge Cases in Tokenization
Real-world text is messy. Here are the common edge cases and how to handle them:
import spacy
nlp = spacy.load("en_core_web_sm")
edge_cases = [
"Dr. Smith earned $2,000 from the U.S. govt.", # abbreviations + currency
"She said 'I can't do this!' and left.", # quotes + contractions
"Visit https://nomidl.com for NLP tutorials.", # URLs
"Call us at +91-9876543210 before 5pm.", # phone numbers + time
"The #NLP community on Twitter is growing fast.", # hashtags
]
for text in edge_cases:
doc = nlp(text)
tokens = [token.text for token in doc]
print(f"Input : {text}")
print(f"Tokens: {tokens}\n")Output:
Input : Dr. Smith earned $2,000 from the U.S. govt.
Tokens: ['Dr.', 'Smith', 'earned', '$', '2,000', 'from', 'the', 'U.S.', 'govt', '.']
Input : She said 'I can't do this!' and left.
Tokens: ['She', 'said', "'", 'I', 'ca', "n't", 'do', 'this', '!', "'", 'and', 'left', '.']
Input : Visit https://nomidl.com for NLP tutorials.
Tokens: ['Visit', 'https://nomidl.com', 'for', 'NLP', 'tutorials', '.']
Input : Call us at +91-9876543210 before 5pm.
Tokens: ['Call', 'us', 'at', '+', '91', '-', '9876543210', 'before', '5', 'pm', '.']
Input : The #NLP community on Twitter is growing fast.
Tokens: ['The', '#', 'NLP', 'community', 'on', 'Twitter', 'is', 'growing', 'fast', '.']Key observations:
- spaCy correctly keeps
"Dr."and"U.S."as single tokens - URLs are kept intact
- Contractions are split:
"can't"→["ca", "n't"] - Hashtags get split at
#— useTweetTokenizerfrom NLTK if you need#NLPkept together
Tokenization in NLP: Comparison Table
| Feature | Word (NLTK) | Sentence (NLTK) | spaCy | BERT (WordPiece) | GPT-2 (BPE) |
|---|---|---|---|---|---|
| Unit | Word | Sentence | Word | Subword | Subword |
| Unknown words | OOV risk | N/A | OOV risk | Handled | Handled |
| Speed | Fast | Fast | Very fast | Medium | Medium |
| Extra linguistic info | Doesn’t work | Doesn’t work | POS, lemma, NER | Doesn’t work | Doesn’t work |
| Handles contractions | Works | N/A | Works | Works | Works |
| Best for | Learning, basics | Summarization | Production pipelines | BERT models | GPT models |
| Vocabulary size | Unbounded | N/A | Unbounded | ~30K | ~50K |
Which Tokenizer Should You Use?
Here’s a simple decision guide:
Learning NLP fundamentals → Start with nltk.word_tokenize(). Simple, well-documented, great for understanding the concept.
Production NLP pipelines → Use spaCy. Fastest, most robust, gives POS/lemma/NER alongside tokens in one call.
Working with BERT, RoBERTa, DistilBERT → Use BertTokenizer from Hugging Face. These models were trained with WordPiece — using the wrong tokenizer breaks everything.
Working with GPT-2, GPT-3/4, LLaMA → Use the model’s native tokenizer from Hugging Face (GPT2Tokenizer, LlamaTokenizer). BPE-based, tuned to the model’s vocabulary.
Social media text (tweets, Reddit) → Use TweetTokenizer from NLTK. Handles hashtags, mentions, and emojis that standard tokenizers mangle.
Custom patterns / domain-specific text → Use RegexpTokenizer with your own regex pattern.
Conclusion
Tokenization in NLP is the foundation everything else is built on. Get it wrong and every downstream task suffers — your model trains on garbage input, rare words become unknown tokens, and accuracy tanks.
The key takeaway: there’s no single best tokenizer. Word tokenization is great for learning and simple tasks. spaCy is the production standard for classical NLP. And for anything involving transformers or LLMs, always use the model’s native subword tokenizer from Hugging Face — BERT expects WordPiece, GPT expects BPE, and mixing them will silently break your pipeline.
Start with the NLTK examples in this article, move to spaCy for real projects, and master Hugging Face tokenizers when you start working with transformers.
FAQs
1. What is tokenization in NLP?
Tokenization in NLP is the process of splitting raw text into smaller units called tokens — typically words, sentences, subwords, or characters. It’s the first step in almost every NLP pipeline and defines what the model receives as input for all downstream tasks.
2. What are the types of tokenization in NLP?
The four main types are: word tokenization (splits on words), sentence tokenization (splits on sentences), character tokenization (splits on individual characters), and subword tokenization (splits words into frequent subword pieces using algorithms like BPE or WordPiece). Modern LLMs all use subword tokenization.
3. What is the difference between word tokenization and subword tokenization?
Word tokenization splits text into complete words. If a word wasn’t seen during training, it becomes an “unknown” token. Subword tokenization (BPE, WordPiece) breaks rare or unknown words into known subword pieces, so no word is ever truly unknown. This is why BERT and GPT can handle any word, even made-up ones.
4. Which Python library is best for tokenization in NLP?
For learning: NLTK’s word_tokenize() and sent_tokenize(). For production: spaCy — it’s faster, handles edge cases better, and gives you POS tags and lemmas alongside tokens. For transformer models: always use the model-specific tokenizer from Hugging Face Transformers.
5. What is BPE tokenization?
Byte Pair Encoding (BPE) is a subword tokenization algorithm that starts with individual characters and iteratively merges the most frequent pairs until a target vocabulary size is reached. GPT-2 and most GPT-family models use BPE. It handles rare and unknown words by breaking them into frequent subword components.
6. Why do LLM APIs charge per token?
LLMs process text as sequences of tokens, not characters or words. The computational cost — memory, attention heads, matrix multiplications — scales with sequence length (token count). So API providers charge per token because that’s the actual unit of computation. A useful rule of thumb: 1 token ≈ 4 characters in English.
Related reading on Nomidl: How Does Natural Language Processing Work? — tokenization is step 2 in the full NLP pipeline. Also see What is Natural Language Processing? for NLP fundamentals, and Sentiment Analysis using TextBlob to see tokenization applied in a real project.
External reference: Hugging Face Tokenizers documentation — the definitive guide to subword tokenization algorithms.
Popular Posts:
- Loop Engineering Explained: From Prompt Engineering to Self-Prompting AI Agents
- Build Your First MCP Server with FastMCP: A Complete Python Tutorial
- MCP vs Function Calling: Key Differences Explained (2026)
- What Is Model Context Protocol (MCP) – A Complete Guide for AI Developers
- MCP Primitives Explained: Tools, Resources, and Prompts With Real Examples
