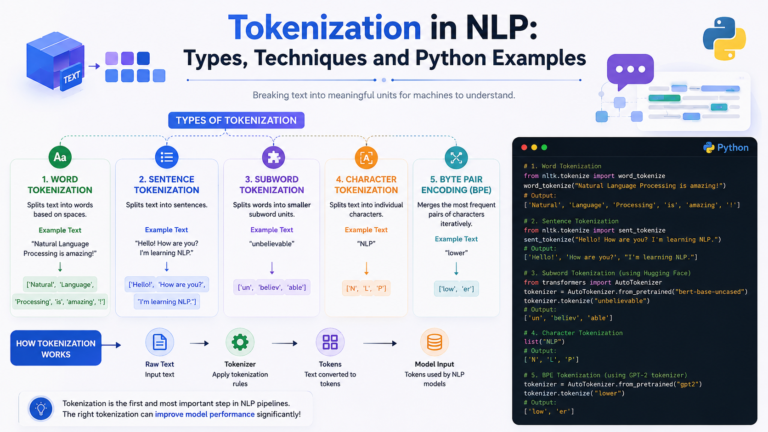
Tokenization in NLP is the very first step in almost every natural language processing pipeline. Before a machine can classify...