nlp

Top 5 Natural Language Processing Libraries for Data Scientist
In this blog post we are going to talk about Natural Language Processing (NLP) which is one of the branches...
Read More →
Day 8: Text Classification with Naïve Bayes
Text Classification is a popular technique used in Natural Language Processing to categorize text documents into predefined categories. Naïve Bayes...
Read More →
Day 7: Building a Sentiment Analysis Model
In today’s world, where social media is the new norm, analyzing the sentiment behind the text has become important for...
Read More →
Day 6: Word Embeddings: an overview
Word embeddings are a powerful technique in natural language processing which can help us represent words in a more meaningful...
Read More →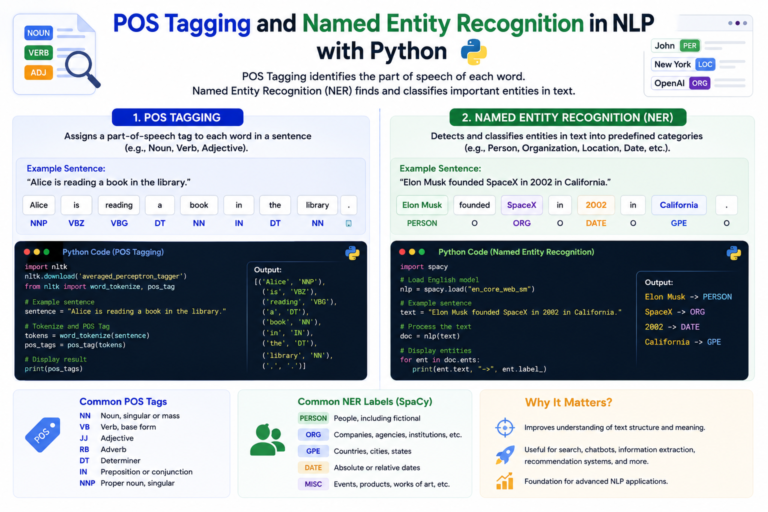
POS Tagging and Named Entity Recognition in NLP with Python
If you’ve ever wondered how Google knows that “Paris” in one sentence means a city in France, and in another...
Read More →
Day 4: Stemming and Lemmatization
IntroductionNatural Language Processing (NLP) plays a critical role in understanding and processing human language. This blog discusses stemming and lemmatization,...
Read More →
Text Preprocessing in NLP: Cleaning and Normalization Guide
I will tell you something which most of the NLP tutorials don’t tell you upfront: text preprocessing in NLP accounts...
Read More →
Day 1: 30 days of Natural Language Processing (NLP)
Natural Language Processing (NLP) is a subfield of Artificial Intelligence (AI) that focuses on the interaction between computers and humans...
Read More →
Unleashing Emotions: Vader for Sentiment Analysis
VADER (Valence Aware Dictionary and Sentiment Reasoner) is a lexicon and rule-based sentiment analysis library that is specifically attuned to...
Read More →
Sentiment Analysis using TextBlob: A Complete Python Guide
Ever wondered how companies know if customers are happy or angry — just from text? That’s sentiment analysis at work....
Read More →
Step-by-Step Process of Implementing Stemming and Lemmatization in Python?
Install the Natural Language Toolkit (NLTK) library. This library provides a range of tools for natural language processing, including stemming...
Read More →
What is the Normal Distribution?
Probability distribution is the function that shows the probabilities of the outcome of an event or experiment. Consider a feature...
Read More →