Gradient Descent is defined as one of the most commonly used iterative optimization algorithm of machine learning to train the machine learning and deep learning models. It helps in finding the local minima of a function.
The best way to define the local minima or local maxima of a function using gradient descent is as follow:
- If we move towards a negative gradient or away from the gradient of the function at the current point, it will give the local minima of that function.
- Whenever we move towards a positive gradient or towards the gradient of the function at the current point, we will get the local maxima of tat function.
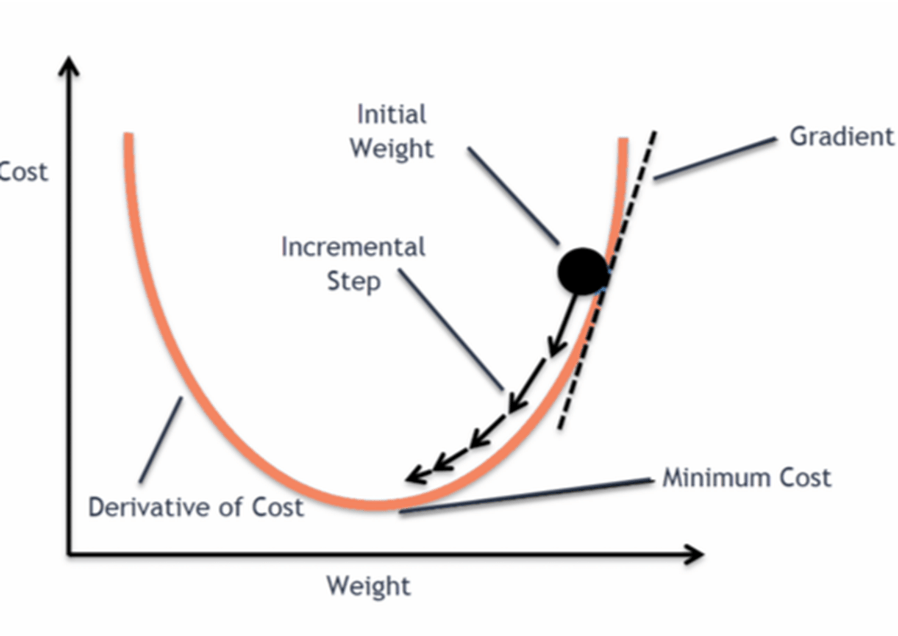
This entire process is known as gradient descent, which is also known as steepest descent. The main objective of using a gradient descent algorithm is to minimize the cost function using iteration.
Gradient descent Working
Before starting the working of gradient descent, we should know some basic concepts to find out the slope of a line from linear regression. The equation for the simple linear regression is given as:
Y = mx + c
Where ‘m’ represents the slope of the line, and ‘c’ represent the intercept on the y-axis.
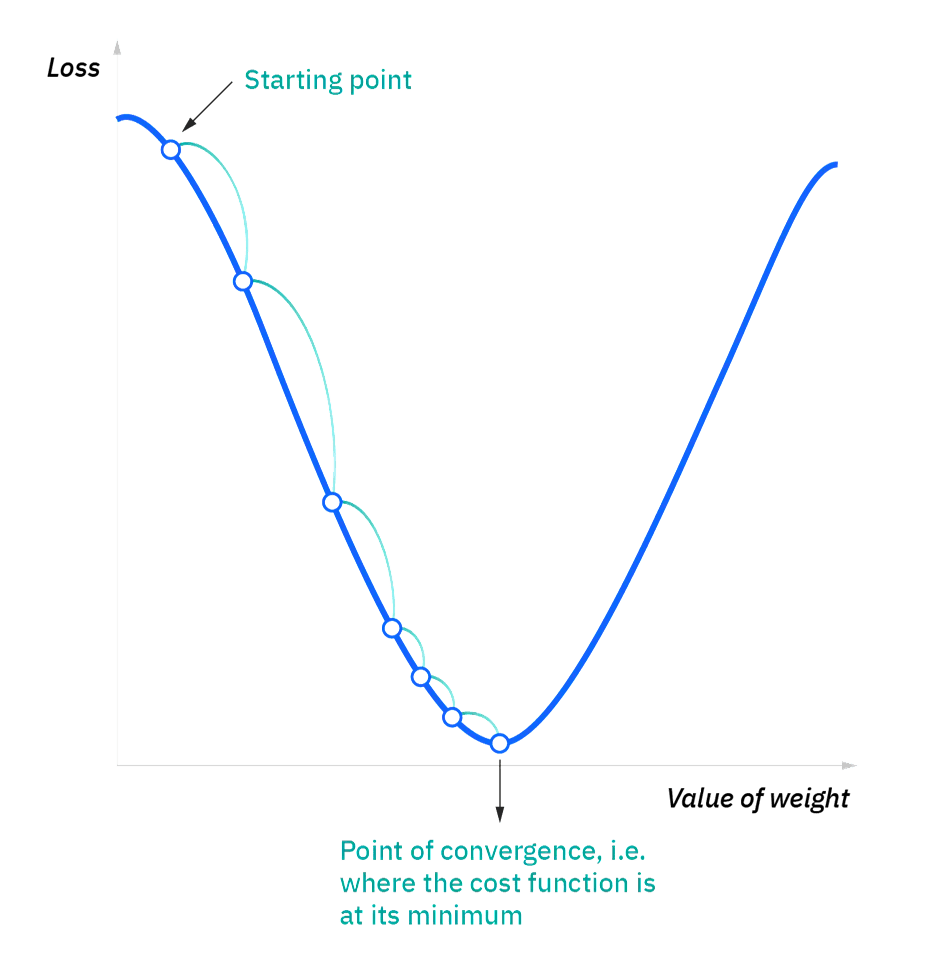
- At the starting point, we will derive the first derivative or slope and then use a tangent line to calculate the steepness of this slope. Further, this slope will inform the updates to the parameters (weights and bias).
- The slope becomes steeper at the starting point or arbitrary point, but whenever new parameters are generated, then steepness gradually reduces, and at the lowest point, which is called a point of convergence.
Role of Learning Rate
The main objective of gradient descent is to minimize the cost function or the error between expected and actual. To minimize the cost function, learning rate plays a crucial role.
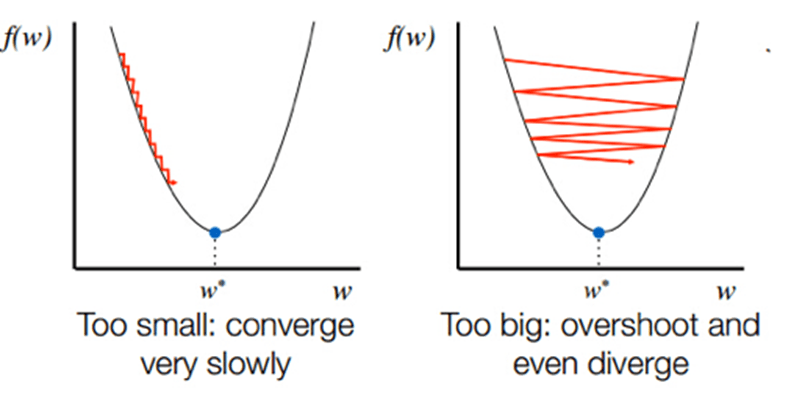
Learning Rate is defined as the step size taken to reach the minima or lowest point. This is typically a small value that is evaluated and updated based on the behavior of the cost function.
If the learning rate is high, it results is large steps but also leads to risks of overshooting the minima. At the same time, a low learning rate shows the small step sizes, which compromises overall efficiency but gives the advantage of more precision.

Excellent article. I definitely appreciate this site. Keep writing!
Thank you Harry
very good post, i certainly love this web site, keep on it
Thank you
Thank you for writing such an excellent article. It helped me a lot and I love the topic.
Your welcome Ty
Please provide me with additional details on that. I need to learn more about it.
Thank you for your post. I liked reading it because it addressed my issue. It helped me a lot and I hope it will help others too.
You’re welcome Lino
You really helped me by writing this article. I like the subject too.
Thank you Drema
Thanks for posting such an excellent article. It helped me a lot and I love the subject matter.
Your welcome Thanh.
I really enjoyed reading your post and it helped me a lot
Thank you Hollis.
Your articles are extremely beneficial to me. May I request more information?
Yes please
Thank you for posting this post. I found it extremely helpful because it explained what I was trying to say. I hope it can help others as well.
You’re welcome Jean
Thank you for writing such a great article. It helped me a lot and I love the subject.
Thank you for writing such an excellent article, it helped me out a lot and I love studying this topic.
Thank you for posting this. I really enjoyed reading it, especially because it addressed my question. It helped me a lot and I hope it will help others too.
You’re welcome Connie
Dear can you please write more on this? Your posts are always helpful to me. Thank you!
Thank you Bradford. yes sure will write more on this
Please tell me more about this. May I ask you a question?
Yes please ask
Please tell me more about this
Sure will write more on this
You’ve been a great help to me. Thank you!
Your welcome Jeanette.
Thank you for writing so many excellent articles. May I request more information on the subject?
You’re welcome Carmelo. yes sure let me know how can i help you?
Thank you for your help. I must say you’ve been really helpful to me.
Your welcome Loni
You’ve been great to me. Thank you!
Your welcome Teena
Thank you for posting such a wonderful article. It really helped me and I love the topic.
Your welcome Audrie
Hello my friend! I wish to say that this article is awesome, great written and come with almost all important infos. I?d like to look more posts like this .
Thank you Fabcouture
There is no doubt that your post was a big help to me. I really enjoyed reading it.
You helped me a lot. These articles are really helpful dude.
Thank you Columbus
Dude these articles have been really helpful to me. They really helped me out.
Thanks Donald
Thank you for your excellent articles. May I ask for more information?
You’re welcome Willy. yes please ask.
I’ve to say you’ve been really helpful to me. Thank you!
it’s my pleasure Brett.
How can I find out more about it?
Do you want more articles on Gradient descent?
I must say you’ve been a big help to me. Thanks!
Thank you Wen. I am glad that it helped you.
let me know what else do you want me to write.
You’ve been very helpful to me. Thank you!
You’re welcome Jene
You’ve been a great help to me. Thank you!
it’s my pleasure Zachery.
I’ve to say you’ve been really helpful to me. Thank you!
You’re welcome Tandy.
Thank you ever so for you blog. Really looking forward to read more.
You actually make it seem so easy with your presentation but I find this topic to be actually something that I think I would never understand. It seems too complicated and very broad for me. I’m looking forward for your next post, I?ll try to get the hang of it!
Excellent blog right here! Also your web site quite a bit up very fast! What host are you the usage of? Can I get your affiliate hyperlink to your host? I wish my website loaded up as fast as yours lol
Great post. I was checking constantly this blog and I’m impressed! Extremely helpful information particularly the last part 🙂 I care for such information much. I was looking for this particular info for a long time. Thank you and good luck.
As I site possessor I believe the content matter here is rattling fantastic , appreciate it for your hard work. You should keep it up forever! Best of luck.
It?s really a great and helpful piece of info. I?m glad that you shared this useful info with us. Please keep us up to date like this. Thanks for sharing.
whoah this blog is fantastic i love studying your posts. Stay up the great work! You already know, a lot of individuals are hunting around for this info, you can help them greatly.
Hello my friend! I want to say that this post is amazing, nice written and include almost all vital infos. I?d like to see more posts like this.
Very nice post. I just stumbled upon your blog and wanted to say that I’ve really enjoyed browsing your blog posts. In any case I?ll be subscribing to your feed and I hope you write again soon!
Hi there, I discovered your site by means of Google at the same time as searching for a similar topic, your web site came up, it seems to be great. I’ve bookmarked it in my google bookmarks.