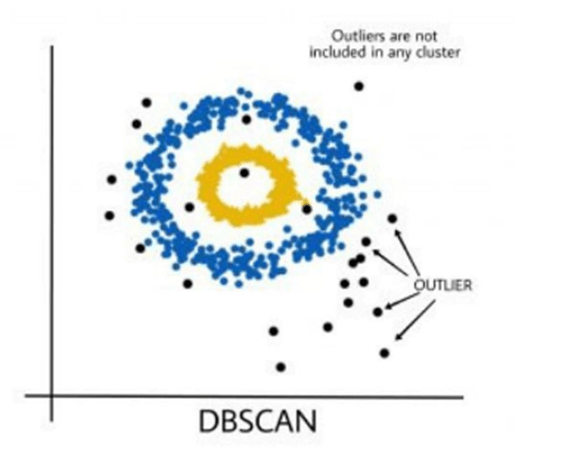
- Density-based special clustering of applications with noise or DBSCAN is a density-based clustering method that calculates how dense the neighborhood of a data point is.
- the main idea behind DBSCAN is that a point belongs to a cluster if it is close to many from that cluster. It will measure the similarity between data points, and group similar data points into one cluster.
Terminologies
There are two different parameters to calculate the density-based clustering:
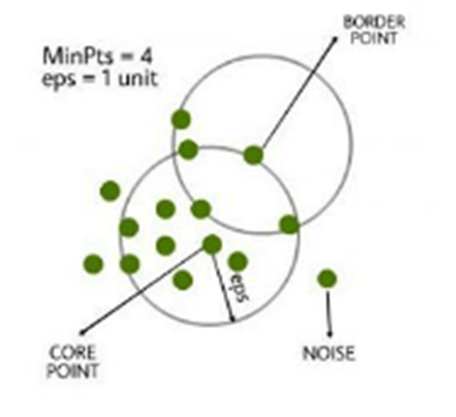
- Eps/Epsilon: it’s considered as the maximum radius of the neighborhood.
- MinPts: MinPts refers to the minimum number of points in an Eps neighborhood of that point.
The other key terms in DBSCAN involve:
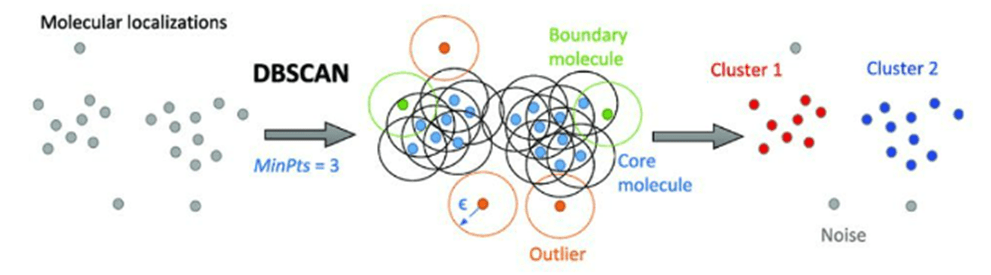
- Core Point: Any point x within the dataset, with a neighbor count greater than or equal to MinPts, is marked as a core point.
- Border Point: Any point x in border point, if the amount of its neighbors is less than MinPts, but it belongs to the eps neighborhood of some core point z.
- Noise Point: Finally, if some extent is neither a core nor a border point, then it’s called a noise point or an outlier.
Algorithm Working
Step 1: First, we’d like to define a couple of parameters in advance: epsilon, and MinPoints.
Step 2: Now, for every data point, the algorithm will count the neighboring data points that are located within epsilon.
Step 3: if the count of neighbors of a data point is higher than MinPoints, then this particular data point will be called a core point.
Step 4: all of the neighboring points of a core point will be grouped into one cluster. Meanwhile, if there is any data point that is not considered as a core point nor being a neighbor of any core point, then the DBSCAN clustering algorithm will consider this data point as a noise or outlier.
Advantages & Disadvantages
Advantages
- Does not require to specify number of clusters beforehand.
- DBSCAN algorithm is able to find arbitrarily size and arbitrarily shaped clusters.
- DBSCAN is robust to outliers and able to detect the outliers.
Disadvantages
- In some cases, determining an appropriate distance of neighborhood (eps) is not easy and it requires domain knowledge.
- DBSCAN algorithm fails just in case of varying density clustering and spare dataset.
- Does not work well just in case of high dimensional data as it can be slow to execute.
Popular Posts
Author

Spread the knowledge