K-Means Clustering is an Unsupervised Learning algorithm, which groups the unlabeled dataset into different clusters.
It allows us to cluster the info into different groups and a convenient way to discover the categories of groups in the unlabeled dataset on its own without the need for any training.
The k-means clustering algorithm mainly performs two tasks:
- Determines the simplest value for k center points or centroids by an iterative process.
- Assigns each data points to its closest k-center. Those data points which are near to the particular k-center, create a cluster.
Algorithm working
Step 1: Select K to decided the numbers of clusters. Let’s imagine k=2.

Step 2: Select random K points or centroids.
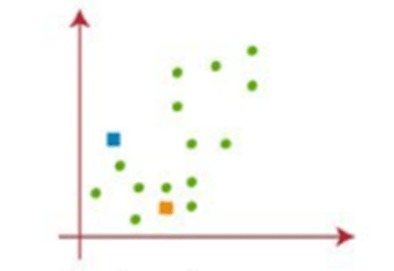
Step 3: Assign each data points to their closest centroid, which can form the predefined K clusters and compute the distance using distance metrics such as sum of square and place a new centroid.
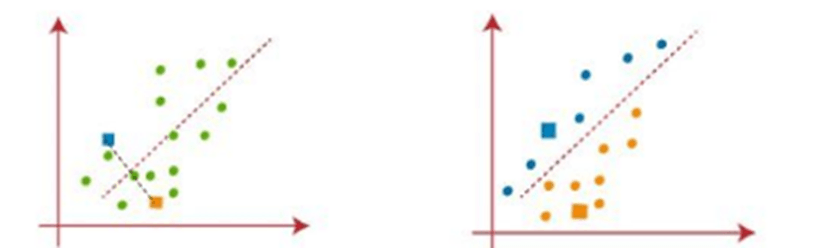
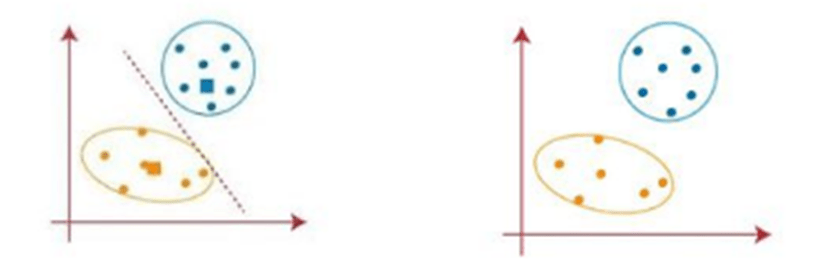
Step 4: Repeat the third steps, which suggests reassign each datapoint to the new closest centroid of each cluster. If any reassignment occurs, then compute the space(distance) again else go to FINISH.
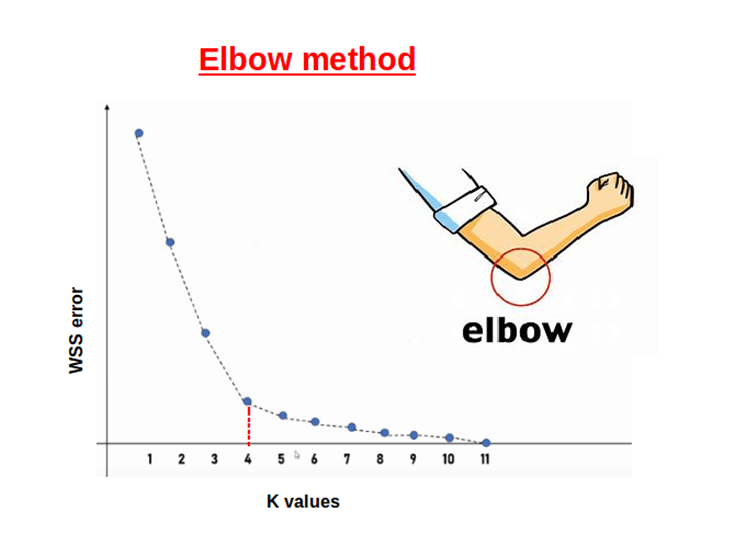
The most popular method to determine the optimal value of K is Elbow method.
Elbow method: the elbow method runs k-means clustering on the dataset for a range of values of k (say 1 to 10)
- Performs k-means clustering with all these different values of K. and calculate average distances to the centroid for each K.
- Plot these points and find the point where the average distance from the centroid falls suddenly (‘Elbow’).
There is another method such as silhouette score, Gap statistic method that can also be used for determining the value of k. However, Elbow method is easy and most widely used method.
Advantages & Disadvantages
Advantages
- It is extremely easy to understand and implement
- If we’ve large number of variables then, K-means would be faster.
- On re-computation of centroids, an instance can change the cluster.
- Tighter and elliptical clusters and formed with k-means.
Disadvantages
- It may be a bit difficult to guess the number of clusters i.e. the value of k.
- Output is strongly impacted by initial inputs like numbers of clusters (value of k).
- It is extremely sensitive to rescaling. If we’ll rescale our data by means of normalization or standardization, then the output will completely change the ultimate output.
- It is sensitive to outliers.
