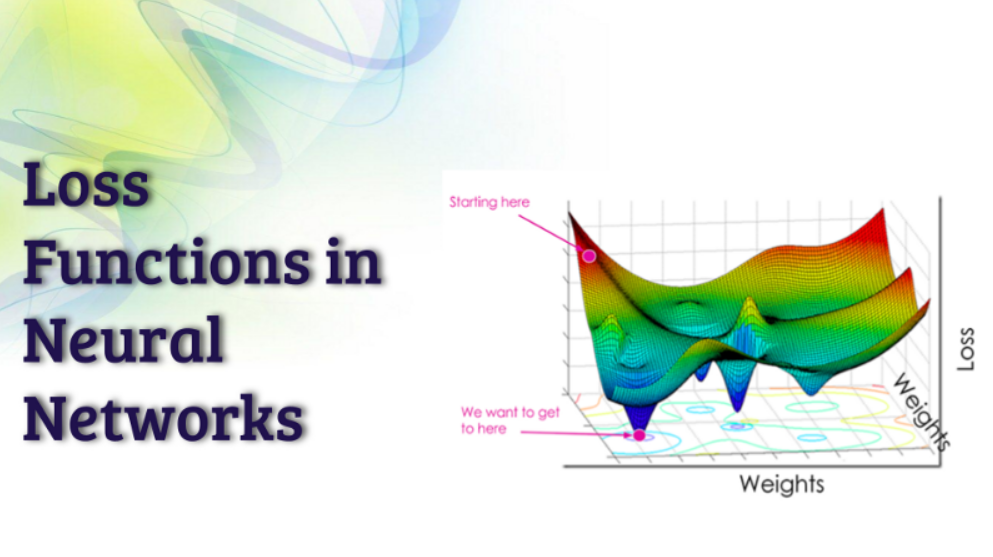
With modelling, there’s a particular goal that the model needs to achieve. It’s just as important to achieve the best possible values of the model parameters as it is to find out what each parameter means in terms of that goal. The loss function (cost function) is minimized, therefore getting unknown values for weight and bias ensures you’re maximizing your target (y). The goal of minimizing the cost function/loss function/sum of squares is to find a model that satisfies the objective in this learning problem. For any model, there are numerous parameters and the structure of the model in prediction or classification is expressed in terms of parameters.
In order to evaluate your model, you first need to find the loss function. This can be done by minimizing it, which can act as a driving force for finding an optimal value for each parameter. The loss function most commonly used in regression is L1, while it is L2 which loses less. Loss functions which are most commonly used in classification are softmax cross entropy or sigmoid cross entropy.
Common loss functions
The following is a list of common loss functions:
tf.contrib.losses.absolute_difference
tf.contrib.losses.add_loss
tf.contrib.losses.hinge_loss
tf.contrib.losses.cosine_distance
tf.contrib.losses.get_losses
tf.contrib.losses.get_regularization_losses
tf.contrib.losses.get_total_loss
tf.contrib.losses.log_loss
tf.contrib.losses.mean_pairwise_squared_error
tf.contrib.losses.mean_squared_error
tf.contrib.losses.sigmoid_cross_entropy
tf.contrib.losses.softmax_cross_entropy
tf.contrib.losses.sparse_softmax_cross_entropy
tf.contrib.losses.log(predictions, labels, weight = 2.0)
Optimizers
Now you should be convinced that you need to use a loss function to get the best value of each parameter of the model. How can you get the best value?
Your initial idea will be most effective for finding the best values of the parameters by using linear regression. From there you need to figure out your path forward. The optimizer is a way to get the best bang for your buck by taking into account every available factor and finding the direction that offers the most value. It runs through different iterations each time and changes the value until it finds what’s best for you. Suppose you have 16 weight values (w1, w2, w3, …, w16) and 4 biases (b1, b2, b3, b4). Initially you can assume every weight and bias to be zero (or one or any number). The optimizer suggests whether w1 (and other parameters) should increase or decrease in the next iteration while keeping the goal of minimization in mind. After many iterations, w1 (and other parameters) would stabilize to the best value (or values).
TensorFlow and all related deep-learning frameworks have optimizers that slowly change the parameters to minimize the loss function. This enables them to give direction on how to set the weight and bias. Let’s assume you’re using deep learning to help train your networks. In each iteration, a certain number of weight values and bias values are changed in order to get the correct ones and minimize loss.
Selecting the best optimizer for the model to converge fast and to learn weights and biases properly is a tricky task.
So adaptive techniques (adadelta, adagrad, etc.) are good for optimizing complex neural networks. On average, Adam is usually the best option. It’s also the most outperforming adaptive technique in most cases and offers better optimization results. Methods such as SGD, NAG, & momentum aren’t always good for sparse data sets, but ADAPTIVE Learning RATE methods are. This makes it easier for you to implement, so you can spend the time focusing on something else. Additionally, it is probable that A-Learn will achieve the best results with no need for defining a learning rate.
Common optimizers
tf.train.optimizer
tf.train.GradientDescentOptimizer
tf.train.AdadeltaOptimizer
tf.train.AdagradOptimizer
tf.train.AdagradDAOptimizer
tf.train.MomentumOptimizer
tf.train.AdamOptimizer
tf.train.FtrlOptimizer
tf.train.ProximalGradientDescentOptimizer
tf.train.ProximalAdagradOptimizer
tf.train.RMSPropOptimizer
