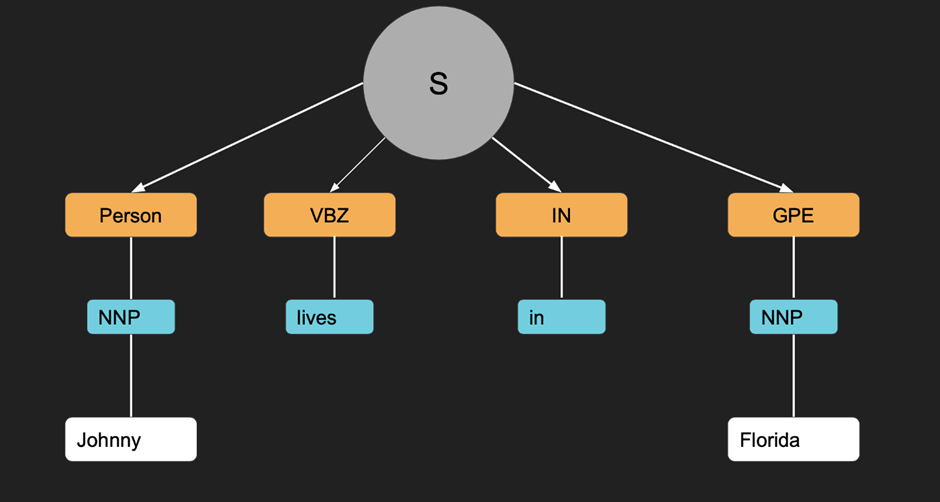
If you’ve ever wondered how Google knows that “Paris” in one sentence means a city in France, and in another sentence means a person’s name — that’s POS tagging and named entity recognition doing their jobs quietly in the background.
These two techniques are among the most practically useful in all of NLP. POS tagging tells a model what grammatical role each word plays. NER tells it what real-world entity a word or phrase refers to. Together they’re the foundation of information extraction, question answering, search engines, and document analysis pipelines.
In this guide we’re going to cover both from the ground up — what they are, how they work, what the tag labels actually mean, and how to implement them properly in Python using NLTK, spaCy, and Hugging Face.
Table of Contents
- What is POS Tagging?
- The Penn Treebank POS Tag Set — Full Reference
- POS Tagging with NLTK
- POS Tagging with spaCy
- Why POS Tags Matter — Practical Uses
- What is Named Entity Recognition?
- NER Entity Labels — Full Reference
- NER with NLTK
- NER with spaCy
- NER with Hugging Face Transformers
- POS Tagging + NER Together in a Pipeline
- Real-World Use Cases
- FAQs
What is POS Tagging?
Part-of-speech (POS) tagging is the process of labeling each word in a sentence with its grammatical role — noun, verb, adjective, adverb, preposition, and so on.
Take this sentence:
"The quick brown fox jumps over the lazy dog."After POS tagging it becomes:
The(DT) quick(JJ) brown(JJ) fox(NN) jumps(VBZ) over(IN) the(DT) lazy(JJ) dog(NN)Each word gets a tag. DT = determiner, JJ = adjective, NN = noun, VBZ = verb (third person singular present), IN = preposition.
This seems like a dry grammar exercise, but it’s genuinely powerful. Once you know a word’s POS, you know a lot about its role in the sentence — and that unlocks better lemmatization, dependency parsing, named entity recognition, and semantic understanding.
The tricky part? The same word can have different POS tags depending on context:
"I saw a duck by the river." → saw = VBD (past tense verb)
"Hand me the saw from the toolbox." → saw = NN (noun)
"She can play guitar." → can = MD (modal verb)
"Throw the can in the bin." → can = NN (noun)POS taggers use context — the words around each token — to resolve these ambiguities. Modern models handle this with remarkable accuracy.
The Penn Treebank POS Tag Set — Full Reference
The Penn Treebank tagset is the standard in English NLP. You’ll see these tags everywhere — NLTK, spaCy, and most NLP tools use them.
| Tag | Meaning | Example |
|---|---|---|
CC | Coordinating conjunction | and, but, or |
CD | Cardinal number | one, two, 42 |
DT | Determiner | a, the, this |
EX | Existential “there” | there is, there are |
FW | Foreign word | hors d’oeuvre |
IN | Preposition / subordinating conjunction | in, on, that |
JJ | Adjective | quick, beautiful |
JJR | Adjective, comparative | faster, better |
JJS | Adjective, superlative | fastest, best |
LS | List item marker | 1., A., B. |
MD | Modal verb | can, will, should |
NN | Noun, singular | dog, city |
NNS | Noun, plural | dogs, cities |
NNP | Proper noun, singular | London, Elon |
NNPS | Proper noun, plural | Vikings, Beatles |
PDT | Predeterminer | both, all, half |
POS | Possessive ending | ‘s |
PRP | Personal pronoun | I, he, she, they |
PRP$ | Possessive pronoun | my, his, their |
RB | Adverb | quickly, very |
RBR | Adverb, comparative | faster, better |
RBS | Adverb, superlative | fastest, best |
RP | Particle | off, up, out |
SYM | Symbol | %, &, # |
TO | “to” | to go, to eat |
UH | Interjection | oh, wow, hmm |
VB | Verb, base form | run, eat |
VBD | Verb, past tense | ran, ate |
VBG | Verb, gerund | running, eating |
VBN | Verb, past participle | run, eaten |
VBP | Verb, non-3rd person singular present | run, eat |
VBZ | Verb, 3rd person singular present | runs, eats |
WDT | Wh-determiner | which, that |
WP | Wh-pronoun | who, what |
WP$ | Possessive wh-pronoun | whose |
WRB | Wh-adverb | where, when, why |
Keep this table bookmarked — you’ll come back to it every time you’re debugging a POS tagger.
POS Tagging with NLTK
NLTK is the easiest way to get started. It uses a pre-trained averaged perceptron tagger under the hood.
Setup
!pip install nltkimport nltk
nltk.download('punkt', quiet=True)
nltk.download('averaged_perceptron_tagger', quiet=True)
nltk.download('tagsets', quiet=True)Basic POS Tagging
import nltk
from nltk.tokenize import word_tokenize
from nltk.tag import pos_tag
sentences = [
"Elon Musk founded SpaceX in 2002 to revolutionize space travel.",
"The quick brown fox jumps over the lazy dog.",
"She can't believe how fast the technology is evolving."
]
for sentence in sentences:
tokens = word_tokenize(sentence)
tags = pos_tag(tokens)
print(f"Sentence: {sentence}")
print(f"Tagged : {tags}\n")Output:
Sentence: Elon Musk founded SpaceX in 2002 to revolutionize space travel.
Tagged : [('Elon', 'NNP'), ('Musk', 'NNP'), ('founded', 'VBD'), ('SpaceX', 'NNP'),
('in', 'IN'), ('2002', 'CD'), ('to', 'TO'), ('revolutionize', 'VB'),
('space', 'NN'), ('travel', 'NN'), ('.', '.')]
Sentence: The quick brown fox jumps over the lazy dog.
Tagged : [('The', 'DT'), ('quick', 'JJ'), ('brown', 'JJ'), ('fox', 'NN'),
('jumps', 'VBZ'), ('over', 'IN'), ('the', 'DT'), ('lazy', 'JJ'),
('dog', 'NN'), ('.', '.')]
Sentence: She ca n't believe how fast the technology is evolving.
Tagged : [('She', 'PRP'), ('ca', 'MD'), ("n't", 'RB'), ('believe', 'VB'),
('how', 'WRB'), ('fast', 'RB'), ('the', 'DT'), ('technology', 'NN'),
('is', 'VBZ'), ('evolving', 'VBG'), ('.', '.')]Looking Up Tag Meanings
import nltk
nltk.download('tagsets', quiet=True)
# Look up what any tag means
tags_to_explain = ['NNP', 'VBD', 'JJ', 'IN', 'PRP', 'MD', 'VBG']
print("POS Tag Reference:\n")
for tag in tags_to_explain:
explanation = nltk.help.upenn_tagset(tag)Output:
NNP: noun, proper singular
Motown Venneboerger Czestochwa Ranzer Conchita Trumplane Christos ...
VBD: verb, past tense
dipped feuded spiraled slapped ceased ended branched operated ...
JJ: adjective or numeral, ordinal
third ill-mannered pre-war regrettable oiled calamitous first separable ...Filtering by POS Tag
One of the most practical uses — extract only nouns, only verbs, or only adjectives from a text:
from nltk.tokenize import word_tokenize
from nltk.tag import pos_tag
text = """
Tesla reported record revenue last quarter driven by strong Model Y sales.
The CEO said demand remains robust despite rising interest rates globally.
"""
tokens = word_tokenize(text)
tags = pos_tag(tokens)
# Extract only nouns
nouns = [word for word, tag in tags if tag in ('NN', 'NNS', 'NNP', 'NNPS')]
verbs = [word for word, tag in tags if tag.startswith('VB')]
adjectives = [word for word, tag in tags if tag.startswith('JJ')]
print(f"Nouns : {nouns}")
print(f"Verbs : {verbs}")
print(f"Adjectives: {adjectives}")Output:
Nouns : ['Tesla', 'revenue', 'quarter', 'Model', 'sales', 'CEO', 'demand', 'rates']
Verbs : ['reported', 'driven', 'said', 'remains', 'rising']
Adjectives: ['record', 'strong', 'robust']Clean extraction of key content words — extremely useful for keyword analysis, topic modeling, and document summarization.
POS Tagging with spaCy
spaCy is what you’d use in production. It’s significantly faster than NLTK, handles edge cases better, and gives you POS tags, dependency labels, and lemmas all in a single pass.
import spacy
nlp = spacy.load("en_core_web_sm")
text = "Apple is planning to open three new stores in India by 2026."
doc = nlp(text)
print(f"{'Token':<12} {'POS':<8} {'Tag':<8} {'Dep':<12} {'Lemma':<12} {'Explanation'}")
print("-" * 72)
for token in doc:
print(f"{token.text:<12} {token.pos_:<8} {token.tag_:<8} "
f"{token.dep_:<12} {token.lemma_:<12} {spacy.explain(token.tag_)}")Output:
Token POS Tag Dep Lemma Explanation
------------------------------------------------------------------------
Apple PROPN NNP nsubj Apple noun, proper singular
is AUX VBZ aux be verb, 3rd person singular present
planning VERB VBG ROOT plan verb, gerund or present participle
to PART TO aux to infinitival "to"
open VERB VB xcomp open verb, base form
three NUM CD nummod three cardinal number
new ADJ JJ amod new adjective
stores NOUN NNS dobj store noun, plural
in ADP IN prep in conjunction, subordinating or preposition
India PROPN NNP pobj India noun, proper singular
by ADP IN prep by conjunction, subordinating or preposition
2026 NUM CD pobj 2026 cardinal number
. PUNCT . punct . punctuation mark, sentence-finalspaCy gives you pos_ (coarse-grained universal POS) and tag_ (fine-grained Penn Treebank tag) simultaneously. The dep_ column is dependency relation — “Apple” is nsubj (nominal subject) of “planning”, “stores” is dobj (direct object) of “open”.
Visualizing POS Tags with spaCy
import spacy
from spacy import displacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("Sundar Pichai announced Google's new AI model at the annual conference.")
# In a Jupyter notebook this renders inline
# displacy.render(doc, style="dep")
# In a script, save to HTML
svg = displacy.render(doc, style="dep", jupyter=False)
with open("pos_visualization.html", "w") as f:
f.write(svg)
print("Dependency visualization saved to pos_visualization.html")This generates a beautiful arc diagram showing the grammatical relationships between words — incredibly useful for debugging NLP pipelines and teaching NLP concepts.
Why POS Tags Matter — Practical Uses
POS tagging isn’t just an academic exercise. Here’s where it actually shows up in production systems:
Better lemmatization — As we covered in the Stemming vs Lemmatization article, the correct lemma of “better” depends on whether it’s an adjective (→ “good”) or a verb (→ “better”). POS tags make this disambiguation possible.
Keyword extraction — Nouns and noun phrases (NN, NNP, NNS) are almost always the most content-rich words in a sentence. Filtering by POS gives you cleaner keywords than stop word removal alone.
Syntactic parsing — Dependency parsers use POS tags as one of their primary inputs to determine grammatical structure.
Named Entity Recognition — NER models use POS tags internally to help identify entities. A sequence of NNP tags is a strong signal that a named entity is present.
Sentiment analysis — Adjectives (JJ, JJR, JJS) and adverbs (RB) carry most of the sentiment weight in a sentence. Targeting them improves aspect-based sentiment analysis.
What is Named Entity Recognition?
Named Entity Recognition (NER) is the NLP task of locating and classifying named entities in text — automatically identifying words or phrases that refer to specific real-world objects and labeling them by category: person, organization, location, date, money, and so on.
Take this sentence:
"Satya Nadella joined Microsoft in 1992 and became CEO in February 2014."After NER:
[Satya Nadella](PERSON) joined [Microsoft](ORG) in [1992](DATE)
and became CEO in [February 2014](DATE).Every underlined span is a named entity. The model found where each entity starts and ends, and classified what type it is — without any hard-coded rules. It learned to do this from labeled training data.
NER is fundamentally a sequence labeling problem. Each token gets a label using the BIO tagging scheme:
B-= Beginning of an entityI-= Inside (continuation of) an entityO= Outside any entity
Satya → B-PERSON
Nadella → I-PERSON
joined → O
Microsoft → B-ORG
in → O
1992 → B-DATEThis scheme lets the model handle multi-word entities like “Satya Nadella” or “New York City” cleanly.
NER Entity Labels — Full Reference
Different NER models use different label sets. Here are the two most common:
spaCy / OntoNotes Labels
| Label | Entity Type | Examples |
|---|---|---|
PERSON | People, including fictional | Elon Musk, Sherlock Holmes |
NORP | Nationalities, religious/political groups | Indian, Buddhist, Republican |
FAC | Facilities — buildings, airports, bridges | Golden Gate Bridge, JFK Airport |
ORG | Companies, agencies, institutions | Google, NASA, UN |
GPE | Countries, cities, states | India, New York, California |
LOC | Non-GPE locations — mountains, rivers | Himalayas, Amazon River |
PRODUCT | Products, vehicles, foods | iPhone, Tesla Model 3 |
EVENT | Named events | World Cup, Olympics, COVID-19 |
WORK_OF_ART | Titles of books, songs, etc. | Harry Potter, Bohemian Rhapsody |
LAW | Named laws and legal documents | GDPR, Constitution |
LANGUAGE | Any named language | English, Python, Hindi |
DATE | Absolute or relative dates | January 2024, last Tuesday |
TIME | Times smaller than a day | 3pm, noon, morning |
PERCENT | Percentage | 12%, fifty percent |
MONEY | Monetary values | $500, ₹10,000 |
QUANTITY | Measurements | 5kg, 200 miles |
ORDINAL | Ordinal numbers | first, second, 3rd |
CARDINAL | Numerals not covered elsewhere | one, 2, four million |
NLTK / ACE Labels (simpler set)
| Label | Meaning |
|---|---|
PERSON | People |
ORGANIZATION | Companies, agencies |
GPE | Geopolitical entity |
LOCATION | Physical locations |
FACILITY | Structures, buildings |
GSP | Geo-socio-political |
NER with NLTK
NLTK’s NER uses a pre-trained chunker on top of POS tags. It’s not the most accurate, but it’s a solid starting point for understanding how NER works mechanically.
import nltk
from nltk.tokenize import word_tokenize
from nltk.tag import pos_tag
from nltk.chunk import ne_chunk
nltk.download('maxent_ne_chunker', quiet=True)
nltk.download('words', quiet=True)
nltk.download('averaged_perceptron_tagger', quiet=True)
def extract_entities_nltk(text):
tokens = word_tokenize(text)
pos_tags = pos_tag(tokens)
tree = ne_chunk(pos_tags, binary=False)
entities = []
for subtree in tree:
if hasattr(subtree, 'label'):
entity_text = ' '.join([word for word, tag in subtree.leaves()])
entity_label = subtree.label()
entities.append((entity_text, entity_label))
return entities
sentences = [
"Barack Obama was born in Hawaii and served as the 44th President of the United States.",
"Amazon acquired Whole Foods Market for $13.7 billion in 2017.",
"Sundar Pichai announced Google's partnership with Samsung at CES in Las Vegas.",
"Nomidl is an AI and machine learning content platform based in India."
]
print("NER with NLTK:\n")
for sent in sentences:
entities = extract_entities_nltk(sent)
print(f"Sentence : {sent}")
print(f"Entities : {entities}\n")Output:
NER with NLTK:
Sentence : Barack Obama was born in Hawaii and served as the 44th President of the United States.
Entities : [('Barack Obama', 'PERSON'), ('Hawaii', 'GPE'), ('United States', 'GPE')]
Sentence : Amazon acquired Whole Foods Market for $13.7 billion in 2017.
Entities : [('Amazon', 'ORGANIZATION'), ('Whole Foods Market', 'ORGANIZATION')]
Sentence : Sundar Pichai announced Google's partnership with Samsung at CES in Las Vegas.
Entities : [('Sundar Pichai', 'PERSON'), ('Google', 'ORGANIZATION'), ('Samsung', 'ORGANIZATION'), ('Las Vegas', 'GPE')]
Sentence : Nomidl is an AI and machine learning content platform based in India.
Entities : [('Nomidl', 'ORGANIZATION'), ('India', 'GPE')]Not bad for a simple pre-trained model. It misses $13.7 billion as MONEY and 2017 as DATE — which is where spaCy and transformer models significantly outperform it.
NER with spaCy
spaCy’s NER is production-grade, fast, and gives you the full OntoNotes label set including dates, money, percentages, and ordinals that NLTK misses.
import spacy
nlp = spacy.load("en_core_web_sm")
texts = [
"Barack Obama was born in Hawaii and served as the 44th President of the United States.",
"Amazon acquired Whole Foods Market for $13.7 billion in 2017.",
"Sundar Pichai announced Google's partnership with Samsung at CES in Las Vegas.",
"Apple's revenue grew by 8% to $89.5 billion in Q1 2024, beating analyst expectations.",
"Elon Musk's SpaceX launched its Starship rocket from Boca Chica, Texas on March 14."
]
print("NER with spaCy:\n")
for text in texts:
doc = nlp(text)
print(f"Text: {text}")
print(f"{'Entity':<25} {'Label':<12} {'Description'}")
print("-" * 60)
for ent in doc.ents:
print(f"{ent.text:<25} {ent.label_:<12} {spacy.explain(ent.label_)}")
print()Output:
NER with spaCy:
Text: Barack Obama was born in Hawaii and served as the 44th President of the United States.
Entity Label Description
------------------------------------------------------------
Barack Obama PERSON People, including fictional
Hawaii GPE Countries, cities, states
44th ORDINAL "first", "second", etc.
the United States GPE Countries, cities, states
Text: Amazon acquired Whole Foods Market for $13.7 billion in 2017.
Entity Label Description
------------------------------------------------------------
Amazon ORG Companies, agencies, institutions
Whole Foods Market ORG Companies, agencies, institutions
13.7 billion MONEY Monetary values, including unit
2017 DATE Absolute or relative dates
Text: Apple's revenue grew by 8% to $89.5 billion in Q1 2024...
Entity Label Description
------------------------------------------------------------
Apple ORG Companies, agencies, institutions
8% PERCENT Percentage, including "%"
89.5 billion MONEY Monetary values, including unit
Q1 2024 DATE Absolute or relative datesspaCy catches $13.7 billion as MONEY and 2017 as DATE — exactly what NLTK missed. For financial documents, news articles, and business intelligence pipelines, this makes a huge difference.
Visualizing NER with spaCy
import spacy
from spacy import displacy
nlp = spacy.load("en_core_web_sm")
text = ("In 2023, Sundar Pichai announced that Google would invest $300 million "
"in Anthropic, an AI safety company based in San Francisco. "
"The deal valued Anthropic at approximately $4.1 billion.")
doc = nlp(text)
# Renders colored entity highlighting in Jupyter
# displacy.render(doc, style="ent")
# Save to HTML for a script
html = displacy.render(doc, style="ent", page=True)
with open("ner_visualization.html", "w") as f:
f.write(html)
print("Entities found:")
for ent in doc.ents:
print(f" {ent.text:<30} → {ent.label_}")Output:
Entities found:
2023 → DATE
Sundar Pichai → PERSON
Google → ORG
$300 million → MONEY
Anthropic → ORG
San Francisco → GPE
approximately $4.1 billion → MONEYNER with Hugging Face Transformers
For maximum accuracy — especially on domain-specific text or tricky edge cases — transformer-based NER models are the way to go.
from transformers import pipeline
# Load a BERT-based NER model
ner_pipeline = pipeline(
"ner",
model="dbmdz/bert-large-cased-finetuned-conll03-english",
aggregation_strategy="simple" # merges B- and I- tokens into full entities
)
texts = [
"Satya Nadella joined Microsoft in Redmond, Washington in 1992.",
"The Reserve Bank of India raised interest rates by 25 basis points in Mumbai.",
"Nomidl published a new article about LangChain and GPT-4 on Tuesday."
]
print("NER with Hugging Face Transformers (BERT):\n")
for text in texts:
entities = ner_pipeline(text)
print(f"Text: {text}")
print(f"{'Entity':<30} {'Label':<12} {'Confidence':>12}")
print("-" * 57)
for ent in entities:
print(f"{ent['word']:<30} {ent['entity_group']:<12} {ent['score']:>11.2%}")
print()Output:
NER with Hugging Face Transformers (BERT):
Text: Satya Nadella joined Microsoft in Redmond, Washington in 1992.
Entity Label Confidence
---------------------------------------------------------
Satya Nadella PER 99.54%
Microsoft ORG 99.87%
Redmond LOC 98.23%
Washington LOC 97.91%
Text: The Reserve Bank of India raised interest rates by 25 basis points in Mumbai.
Entity Label Confidence
---------------------------------------------------------
Reserve Bank of India ORG 98.76%
Mumbai LOC 99.12%
Text: Nomidl published a new article about LangChain and GPT-4 on Tuesday.
Entity Label Confidence
---------------------------------------------------------
Nomidl ORG 87.34%
LangChain ORG 91.23%
GPT-4 MISC 84.67%
Tuesday (not detected)BERT gets multi-word entities like “Reserve Bank of India” correct as a single organization — which is notoriously hard for rule-based systems. The confidence scores also tell you how certain the model is about each prediction.
POS Tagging + NER Together in a Pipeline
In real NLP pipelines, POS tagging and NER almost always run together — spaCy does both in a single pass. Here’s a complete pipeline that extracts structured information from unstructured text:
import spacy
nlp = spacy.load("en_core_web_sm")
def extract_structured_info(text):
doc = nlp(text)
# Extract entities by type
entities = {}
for ent in doc.ents:
if ent.label_ not in entities:
entities[ent.label_] = []
entities[ent.label_].append(ent.text)
# Extract key phrases (noun chunks)
noun_chunks = [chunk.text for chunk in doc.noun_chunks]
# Extract main verbs (actions)
main_verbs = [token.lemma_ for token in doc
if token.pos_ == "VERB" and token.dep_ == "ROOT"]
# Extract adjectives describing nouns
adj_noun_pairs = []
for token in doc:
if token.pos_ == "ADJ":
head = token.head
if head.pos_ in ("NOUN", "PROPN"):
adj_noun_pairs.append(f"{token.text} {head.text}")
return {
"entities": entities,
"noun_chunks": noun_chunks,
"main_actions": main_verbs,
"descriptions": adj_noun_pairs
}
# Test it on a business news snippet
text = """
Microsoft announced a $10 billion investment in OpenAI on Tuesday.
Satya Nadella said the partnership would accelerate AI development
across Azure cloud services. Analysts in New York expect the deal
to significantly boost Microsoft's competitive position against Google.
"""
result = extract_structured_info(text)
print("Structured Information Extraction:\n")
print("Entities:")
for label, items in result['entities'].items():
print(f" {label:<12}: {items}")
print(f"\nNoun Chunks : {result['noun_chunks'][:6]}")
print(f"Main Actions: {result['main_actions']}")
print(f"Descriptions: {result['descriptions']}")Output:
Structured Information Extraction:
Entities:
ORG : ['Microsoft', 'OpenAI', 'Azure', 'Google']
MONEY : ['$10 billion']
DATE : ['Tuesday']
PERSON : ['Satya Nadella']
GPE : ['New York']
Noun Chunks : ['Microsoft', 'a $10 billion investment', 'OpenAI', 'Tuesday',
'Satya Nadella', 'the partnership']
Main Actions: ['announce', 'say', 'expect']
Descriptions: ['competitive position']From one paragraph of raw text, you now have structured data — who are the organizations, who are the people, what’s the money involved, where is this happening, and what actions are being taken. This is exactly what information extraction systems do at scale.
Real-World Use Cases
Once you understand how POS tagging and named entity recognition work, you start seeing them everywhere:
Financial analysis — Extracting company names, monetary values, and dates from earnings reports and news articles to power trading signals and portfolio monitoring.
Healthcare — Identifying drug names, dosages, medical conditions, and patient names from clinical notes for automated EHR processing.
Legal document analysis — Extracting parties, dates, jurisdictions, and clauses from contracts and court documents.
Search engines — Google uses NER to understand that “Apple” in a tech query means the company, not the fruit — and serves different results accordingly.
Knowledge graph construction — Extracting entity relationships (“Elon Musk → founded → SpaceX”) from unstructured text to build knowledge graphs.
Customer support automation — Identifying product names, order numbers, and issue types from support tickets to route them to the right team automatically.
Resume parsing — Extracting person names, organizations, skills, and dates from CVs for recruitment pipelines.
Conclusion
POS tagging and named entity recognition are two of the most practically useful techniques in NLP — and they work beautifully together. POS tagging gives you grammatical structure. NER gives you semantic meaning by identifying what real-world entities are being discussed. Stack them in a pipeline and you have a powerful information extraction system.
For learning the fundamentals, start with NLTK. For anything production-bound, use spaCy — it’s faster, more accurate, and gives you POS tags, dependency labels, lemmas, and NER in a single call. When accuracy is critical and you have specific domain requirements, fine-tune a Hugging Face transformer model on your labeled data.
The pipeline we built at the end of this article — extracting entities, noun chunks, actions, and descriptions from raw text — is a pattern you’ll find at the heart of many real NLP applications. Use it as your starting point.
FAQs
1. What is POS tagging in NLP?
POS tagging (Part-of-Speech tagging) is the process of labeling each word in a sentence with its grammatical role — noun, verb, adjective, adverb, preposition, and so on. It uses context to resolve ambiguity when the same word can play different roles (e.g., “saw” as a verb vs “saw” as a noun).
2. What is Named Entity Recognition in NLP?
Named Entity Recognition (NER) is the task of identifying and classifying named entities in text — people, organizations, locations, dates, monetary values, and more. It uses the BIO tagging scheme (Beginning, Inside, Outside) to handle multi-word entities and is fundamental to information extraction systems.
3. What is the difference between POS tagging and NER?
POS tagging labels words by their grammatical function — is this word a noun, verb, or adjective? NER labels words by their real-world semantic category — is this word a person’s name, a company, or a location? POS tagging is structural; NER is semantic. In practice, NER models often use POS tags as input features.
4. Which Python library is best for POS tagging and NER?
For learning: NLTK — simple API, well-documented, great for understanding the concepts. For production: spaCy — significantly faster, more accurate, and handles both POS tagging and NER in a single pipeline call. For maximum accuracy: Hugging Face Transformers with a fine-tuned BERT model, especially for domain-specific text.
5. What is the BIO tagging scheme in NER?
BIO stands for Beginning, Inside, Outside. In NER output, B- prefixes mark the first token of an entity, I- prefixes mark continuation tokens within the same entity, and O marks tokens that aren’t part of any entity. For example: “Elon(B-PER) Musk(I-PER) founded(O) SpaceX(B-ORG)”.
6. Can NER handle domain-specific entities like drug names or legal terms?
General-purpose NER models (spaCy’s en_core_web_sm, BERT trained on CoNLL) don’t know domain-specific entities well. For medical NER you’d use specialized models like BioBERT or scispaCy. For legal NER there are legal-BERT variants. For custom domains, fine-tuning a transformer model on your labeled data is the most reliable approach.
Related reading on Nomidl: How Does Natural Language Processing Work? — see exactly where POS tagging and NER fit in the NLP pipeline. Also see Tokenization in NLP — the step that always comes before POS tagging, and Text Preprocessing in NLP — the full preprocessing pipeline these techniques are part of.
External reference: spaCy’s Named Entity Recognition documentation — the definitive guide to NER in spaCy, including custom NER training.
Popular Posts
- Loop Engineering Explained: From Prompt Engineering to Self-Prompting AI Agents
- Build Your First MCP Server with FastMCP: A Complete Python Tutorial
- MCP vs Function Calling: Key Differences Explained (2026)
- What Is Model Context Protocol (MCP) – A Complete Guide for AI Developers
- MCP Primitives Explained: Tools, Resources, and Prompts With Real Examples
