When it comes to evaluating the performance of our machine learning models, two main metrics are considered: precision and recall. These metrics are the basis for evaluating the effectiveness and reliability of the model’s prediction. In this article, we will discuss the complexities of precision and recall, their significance, and how they are used in model evaluation.

What is Precision?
Precision, in the context of evaluation, measures the accuracy of positive predictions made by a model. It answers the question, “Out of all the positive predictions, how many are actually true?” In simpler terms, precision reflects the model’s ability to avoid false positives. A high precision score indicates that the model has a low tendency to misclassify negative instances as positive.
We can use the following formula to calculate Precision:

What is Recall?
Recall, on the other hand, assesses the model’s ability to identify all relevant instances within a dataset. It provides an answer to the question, “Out of all the true positive instances, how many did the model correctly identify?” The recall is also known as sensitivity or the true positive rate.
We use the following formula To calculate recall:

What Is the Relationship Between Precision and Recall?
Precision and recall are related metrics, and finding the right balance between the two is required. Improving one metric often comes at the expense of another. A high accuracy score means the model is careful in predicting positives, which leads to a higher number of instances being missed (false negatives). On the other hand, a high recall score indicates that the model captures more instances, but it may also lead to an increase in false positives. Finding the right balance between precision and recall depends on what the task requires. In some situations, like medical diagnosis, it’s crucial to prioritize recall to catch all positive cases. However, in other cases like spam classification, accuracy becomes more important as false positives can have serious consequences.
The F1 Score: Balancing Precision and Recall
To address the trade-off between precision and recall, the F1 score offers a single metric that combines both measures into one comprehensive evaluation. The F1 score is calculated using the harmonic mean of precision and recall, providing a balanced perspective on a model’s performance.
The formula for calculating the F1 score is as follows:
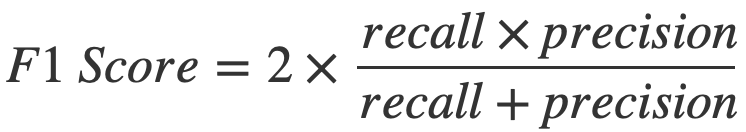
By using the F1 score, we can evaluate a model’s overall effectiveness by taking into account both precision and recall at the same time.
Tips for Optimizing Precision and Recall
To enhance precision and recall in your machine learning models, here are some practical tips to keep in mind:
- Data Quality and Balance: Ensure that your training dataset is of high quality and accurately represents the real-world scenarios you want the model to perform well in. Additionally, strive for a balanced dataset with an appropriate distribution of positive and negative instances.
- Feature Engineering: Select relevant features that contribute to accurate predictions. Engage domain experts to identify meaningful features and eliminate any noise or redundant information that could hinder performance.
- Threshold Adjustment: Fine-tune the classification threshold based on your specific requirements. Increasing the threshold can improve precision but may reduce recall, while decreasing the threshold can have the opposite effect.
- Model Selection and Tuning: Experiment with different models and algorithms to find the best fit for your task. Consider ensemble methods and hyperparameter tuning techniques to optimize performance.
- Cross-Validation: Employ cross-validation techniques to evaluate your model’s performance on different subsets of the data. This helps ensure that the model generalizes well and is not overfitting to the training set.
- Error Analysis: Perform a thorough analysis of model errors to identify patterns and areas of improvement. Understand the types of misclassifications occurring and take corrective measures accordingly.
- Incremental Learning: Continuously update and refine your model as new data becomes available. Implement strategies such as online learning or active learning to adapt to changing conditions and improve performance over time.
By implementing these strategies in your model development process, you can enhance precision and recall, resulting in improved accuracy and dependable predictions.
Conclusion
Precision and recall are fundamental metrics in evaluating the performance of machine learning models. While precision focuses on the accuracy of positive predictions, recall measures the model’s ability to capture all relevant instances. Balancing these metrics is important, and the F1 score provides a unified measure to assess a model’s overall effectiveness.
If you found this article helpful and insightful, I would greatly appreciate your support. You can show your appreciation by clicking on the button below. Thank you for taking the time to read this article.
Popular Posts
- From Zero to Hero: The Ultimate PyTorch Tutorial for Machine Learning Enthusiasts
- Day 3: Deep Learning vs. Machine Learning: Key Differences Explained
- Retrieving Dictionary Keys and Values in Python
- Day 2: 14 Types of Neural Networks and their Applications
