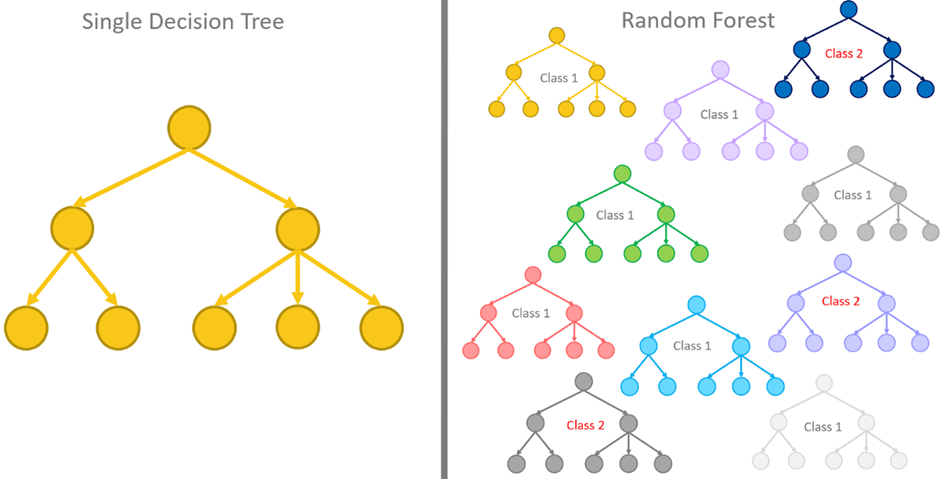
When it comes to the domain of machine learning algorithms, two prevalent models are the decision trees and the random forests. While both are employed for classification and regression, they diverge in their data analysis and model building methodologies.
Decision Trees
A decision tree is a model that segments the presented data into minor subsets that hold data points with analogous properties. The decision tree algorithm then recursively breaks down these subsets until it reaches a leaf node that comprises all the data points classified as either positive or negative. Although the decision tree can be structured in multiple ways, it generally features a root node, decision nodes, and leaf nodes.
The probabilities for each level are processed to establish if the classification is either “positive” or “negative.” Decision trees have the propensity to overfit, indicating they might get too intricate and perfectly fit the training data, resulting in poor performance when presented with new data.
Random Forests
Random Forest is an ensemble machine learning algorithm that assimilates many decision trees into a solitary model. Random forest models generally have higher accuracy rates than single-tree models since they’re less prone to overfitting and are more robust against new data categories. The algorithm assembles multiple decision trees, each with a unique split point and weighting. The model is then trained to make predictions depending on the selected feature values in one tree.
Random Forest models can be employed for classification or regression issues. They enable predictions by merging decision trees, implying that numerous possible hypotheses could be picked. When recognizing patterns or correlations between variables, random forest models are a fitting preference to ensure that the model isn’t overfitting.
Why You Might Use This
Both decision trees and random forests are powerful machine learning models, and selecting the model that’s ideal for the situation at hand depends on the problem’s complexity. Decision trees are less complicated and more explainable, rendering them a suitable preference for smaller datasets with fewer variables. However, random forests offer superior accuracy rates and are more appropriate for larger datasets with intricate relationships between variables.
Conclusion
decision trees and random forests are two commonly used machine learning algorithms that can solve classification and regression problems. Familiarizing oneself with the divergences between the two models is essential for selecting the most appropriate model for your data and the problem you’re seeking to resolve.
