
Machine learning models are becoming more advanced and complex and in order to understand a machine learning model’s behaviour and improve its performance, it is important to be able to interpret its predictions. In this article we are going to talk about 5 tricks which will help us in interpretability in machine learning.
1 – Feature Importance
Feature importance is one of the ways which determine that which feature in our data input contribute most of the model’s output. this technique can help us to identify the most important features, which can help to optimize the model’s performance. There are multiple ways to calculate feature importance, some of them are: permutation importance, SHAP values, and LIME.
Let’s look at the example of how to calculate feature importance using permutation importance:

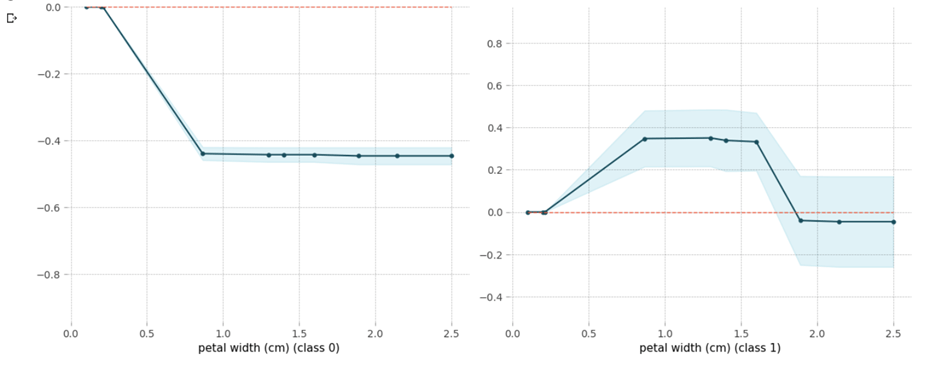
2 – Partial Dependence Plot
Partial dependence plots show the relationship between a model’s predicted outcome and the particular feature, if all other features are held constant. it helps us in identifying relationship between the input features and the model’s output that are not linear.
Let’s look at the example of how to create a partial dependence plot using the PDPbox library:


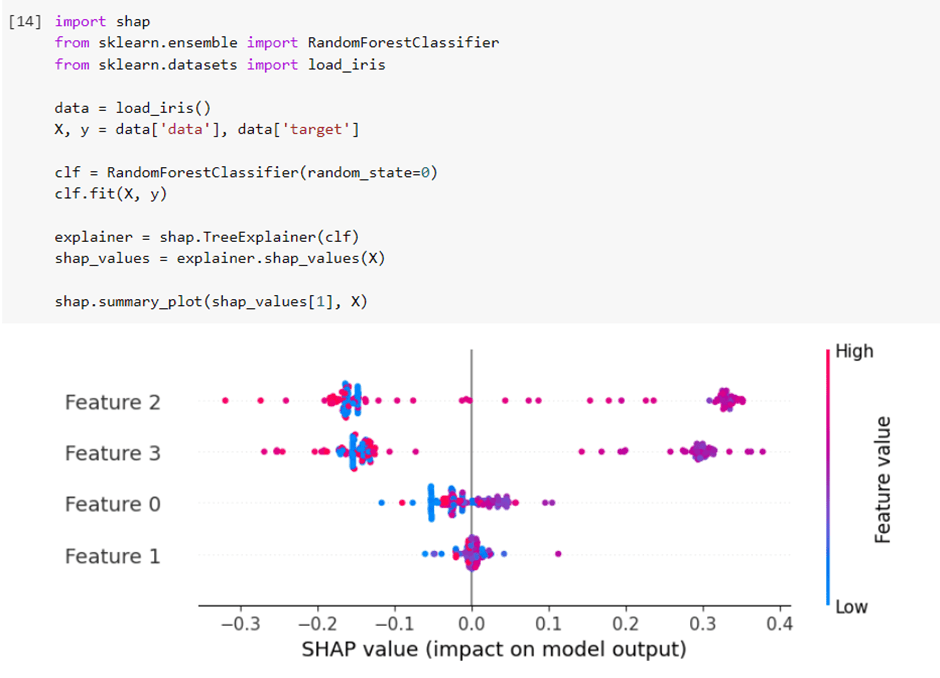
3 – SHAP Values
SHAP values help explain the model output by giving each input function a value that indicates its contribution to the model output. SHAP values are based on game theory and provide a unified framework for attributional importance, partial dependence, and interaction effects.
Let’s look at the example of how to calculate SHAP values using the shap library:
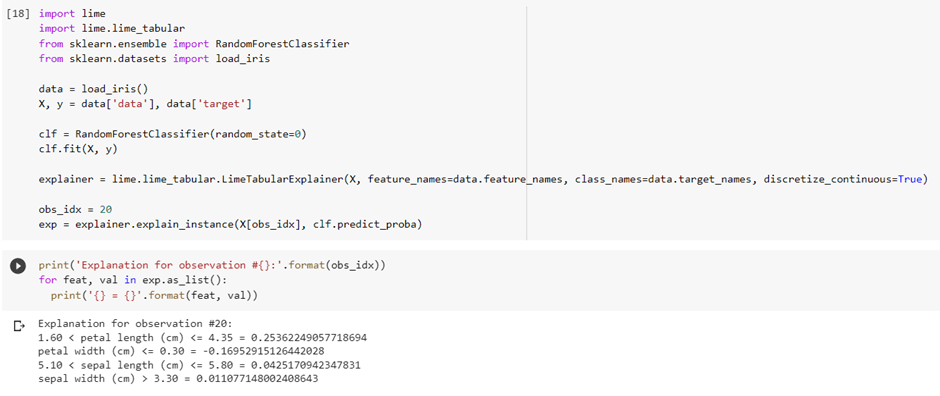
4 – Local Interpretable Model-agnostic Explanations (LIME)
LIME is a model-agnostic method for explaining individual predictions by approximating the model locally. LIME provides a way to identify which input features the model is using to make a specific prediction.
Let’s look at the example of how to use LIME using the lime library:
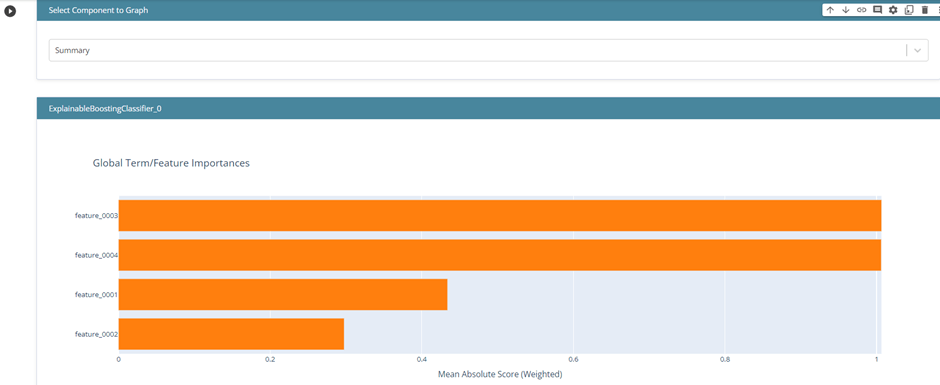
5 – Surrogate Models
Surrogate models can be used to approximate a black box model in a simpler and more interpretable way.
This can be achieved by training the replacement model on the input-output pairs of the original model.
Once the surrogate model is trained, it can be used to predict new input data and provide explanations for the predictions.
Let’s look at the example of how to use Surrogate models using the interpret library:

Conclusion:
In this article we have discussed about 5 Tricks for Model Interpretability in Machine Learning and also, we have seen the examples of that by implemented each of them in Python Programming language. I hope you liked this article, if you have any question then let me know.
