One of the most common problems in RNNs is called gradient vanishing. LSTM architectures help you with this. A very common type of RNN is LSTM. This type of network is much better at capturing long-term dependencies than simple RNNs. The only unusual thing about LSTMs is the way that they compute the hidden state. Essentially, an LSTM is composed of a cell, an Input Gate, an Output Gate, and a Forget Gate, which is the unusual thing about it, as shown in the following diagram:
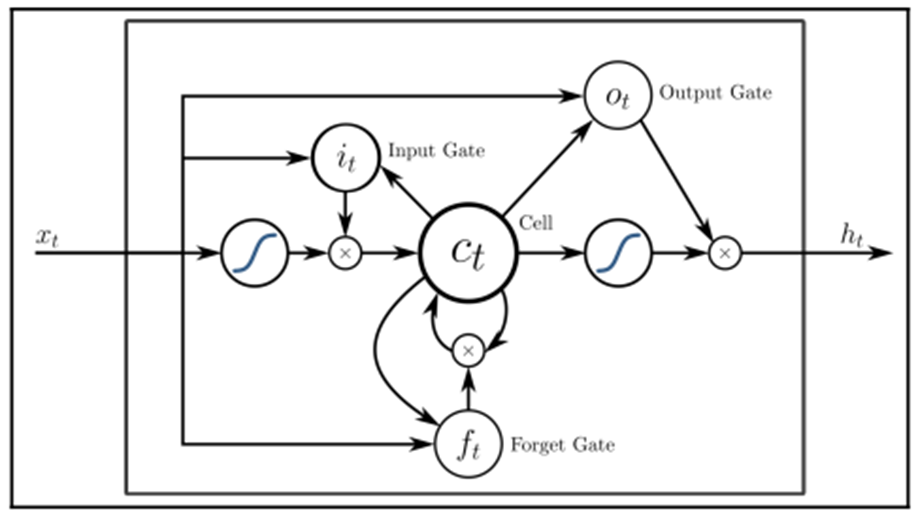
LSTM Architecture
This type of network is used to classify and make predictions from time series data. For example, some LSTM applications include handwriting recognition or speech recognition. One of the properties of LSTM architecture is the ability to deal with lags of different durations (which it does better than RNNs) The equation of an LSTM with a forget gate is given as follows:
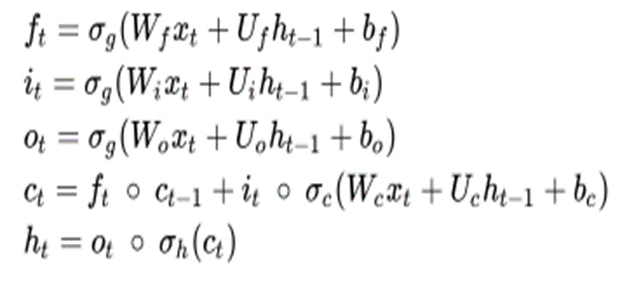
Now take a look at the following notation:

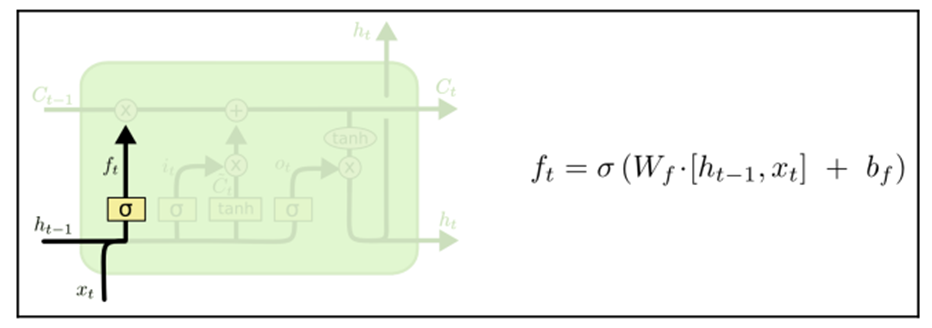
Here, the LSTM needs to decide what information we’re going to throw away from the cell. This is done by a type of gate called the forget layer. It’s implemented using a sigmoid function that evaluates the hidden state and the current input in order to decide whether we keep the information or get rid of it. If we want to predict the next word based on the previous one, the information of the cell might store is the gender of the noun, to predict the next world correctly. If we change the subject, we want to forget the previous gender information, and that what this gate is used to: If we want to predict the next word based on the previous one, the information of the cell might store is the gender of the noun, to predict the next world correctly. If we change the subject we want to forget the previous gender information, and that what this gate is used to:
The second step would be to decide what information the cell should store. In our example, it would be to determine the gender we should store once we forget the previous one. This is done in two parts; the first part is composed of a sigmoid that decides which value we should update. Then, another layer, which uses tanh, is used to create a vector of candidates.
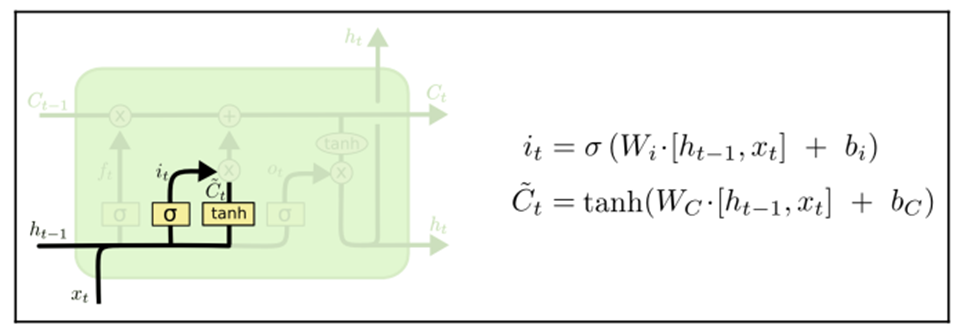
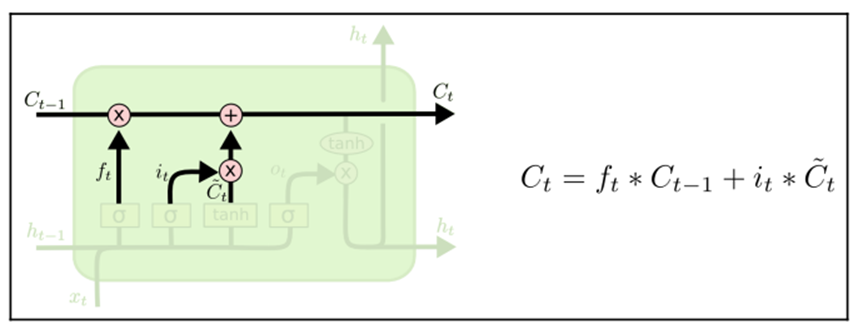
Now we have the decision as to whether we should drop the information and the new potential value:
At the end of the notation, the cell decides what to output. The first part is to decide what part of the cell we are going to output. This is determined by a sigmoid. The second part is to squash the values between -1 and 1, and then multiply it by the sigmoid gate:
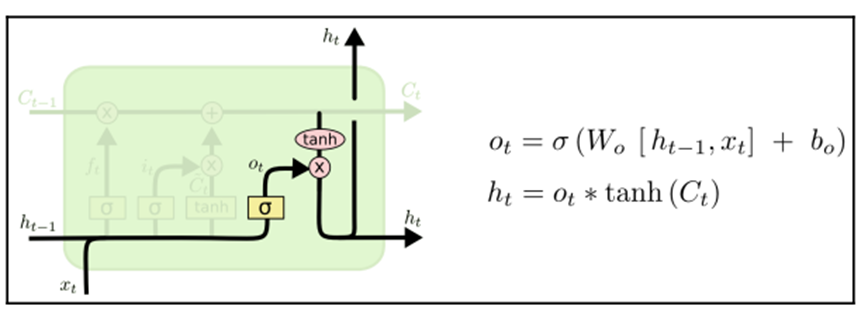
In our language model task, we can decide to output information about whether the subject is plural or singular, to inform, for example, the next verb conjugation.
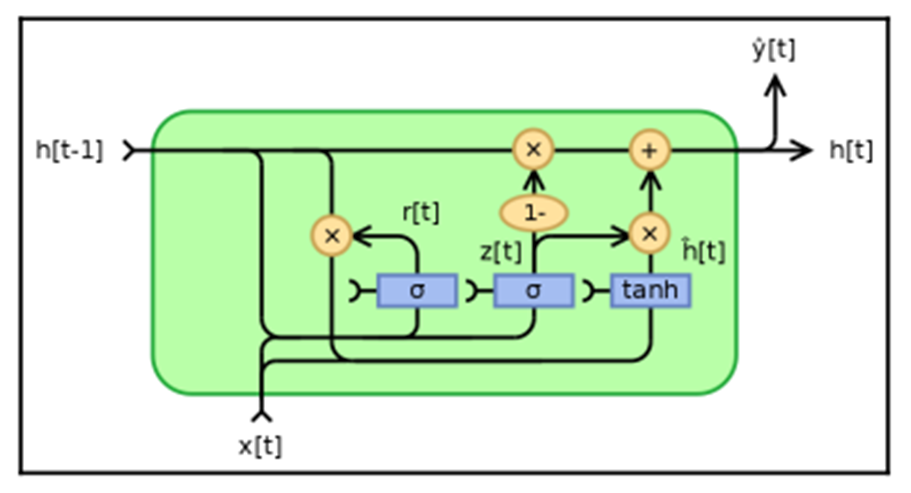
Gated Recurrent Units (GRUs) operate in a similar way to LSTMs but with fewer parameters, as they do not have an output gate. It has a similar performance in some tasks, but in general, LSTM architecture provides better performance: