Building an AI agent is only half the challenge. The real challenge is proving that it actually works. Many developers spend weeks building sophisticated AI agents with LangChain, LangGraph, CrewAI, AutoGen, or OpenAI Agents, only to realize they have no reliable way to measure performance.
Based on evaluating multiple RAG systems, AI agents, and memory-enabled assistants, one of the biggest mistakes teams make is relying on subjective testing. Asking a few questions and deciding the agent “looks good” is not evaluation. In production environments, AI systems need measurable, repeatable, and objective evaluation.
This is where AI agent evaluation becomes critical.
In this article, you will learn:
- What AI agent evaluation actually means
- Why traditional testing methods fail
- The most important AI agent metrics
- The best evaluation frameworks
- How to evaluate RAG agents
- How to evaluate memory-enabled agents
- Practical Python examples
- A complete evaluation workflow used in real-world systems
By the end, you’ll have a framework for evaluating AI agents systematically instead of relying on guesswork.
Why is AI agent evaluation important?
The direct answer is simple: an AI agent cannot be improved if it cannot be measured.
Unlike traditional software, AI agents are probabilistic systems. Two identical queries may produce different responses. The same agent may perform well on one task and fail completely on another.
For example, imagine a customer-support agent that answers 90% of questions correctly but occasionally hallucinates refund policies. Even though the agent appears useful overall, that single failure mode could create significant business risk.
Evaluation helps answer questions such as:
- Is the agent accurate?
- Does it retrieve the correct information?
- Does it use tools correctly?
- Does memory improve performance?
- Is the response grounded in facts?
- Is the system improving over time?
Without evaluation, there is no objective way to answer these questions.
What should you actually measure in an AI agent?
Many developers focus only on response quality. While important, response quality is only one component of agent performance.
Modern AI agents typically consist of multiple subsystems:
- reasoning
- planning
- retrieval
- memory
- tool usage
- response generation
Each component should be evaluated independently.
Think of an AI agent like a Formula 1 car. Measuring only the final lap time doesn’t tell you whether the engine, tires, or aerodynamics are causing problems.
Similarly, evaluating only the final answer doesn’t reveal where an AI agent is failing.
Which Metrics Should You Use to Evaluate an AI Agent?
Many developers make the mistake of measuring only response quality. While a good response is important, it is only the final output of a much larger system. Modern AI agents consist of multiple layers including retrieval systems, memory systems, planning modules, tool integrations, and language models. A failure in any one of these layers can cause the final answer to be incorrect.
A robust evaluation strategy measures the entire agent pipeline rather than just the final response.
Accuracy: Is the Agent Producing Correct Answers?
Accuracy is the most fundamental evaluation metric. It measures whether the agent’s final answer matches the expected answer.
For example, if the user asks:
What is the capital of France?
and the agent responds: Paris
the answer is correct.
While this sounds straightforward, measuring accuracy becomes significantly harder in real-world applications. Unlike traditional machine learning tasks, AI agents often produce free-form text. Two responses may convey the same meaning while using completely different wording.
For example:
Ground Truth: Paris
Agent Response:
The capital city of France is Paris.
Both answers are correct despite being textually different.
This is why modern evaluation systems increasingly use LLM-as-a-Judge approaches, where another language model evaluates semantic similarity rather than exact string matches.
Accuracy is particularly important for:
- Question-answering agents
- Customer support agents
- Educational tutors
- Knowledge assistants
However, accuracy alone is never enough.
Context Precision: Did the Agent Retrieve Relevant Information?
For RAG-based agents, retrieval quality often matters more than the language model itself.
Context Precision measures:
How much of the retrieved context was actually useful for answering the question?
Imagine a user asks:
How does Retrieval-Augmented Generation work?
The retriever returns:
- RAG documentation
- Neural network history
- Kubernetes deployment guide
- Python installation tutorial
Only one of those documents is relevant.
Low context precision means the retriever is fetching too much irrelevant information.
This causes:
- Higher token costs
- Lower answer quality
- More hallucinations
- Slower responses
Improving retrieval precision often leads to larger gains than upgrading the language model.
Context Recall: Did the Agent Retrieve Everything It Needed?
While precision focuses on relevance, recall focuses on completeness.
Context Recall measures:
Did the retrieval system fetch all the information necessary to answer the question?
Consider a technical troubleshooting agent.
The answer may require information from three separate documents. If only one document is retrieved, the response may be partially correct but incomplete.
Low recall often results in:
- Missing details
- Partial answers
- Incorrect conclusions
High-performing RAG systems aim to balance both precision and recall.
Faithfulness: Is the Response Grounded in Retrieved Evidence?
Faithfulness has become one of the most important evaluation metrics for modern RAG systems.
This metric measures whether the generated answer can be directly supported by the retrieved documents.
For example:
Retrieved Context
LangChain is an open-source framework for building LLM applications.
Agent Response
LangChain is an open-source framework for building LLM applications.
This response is faithful.
However:
Agent Response
LangChain was created by Google in 2020.
This information does not appear in the context and therefore lacks faithfulness.
Faithfulness is often considered more important than accuracy in enterprise environments because it measures trustworthiness.
Tool Usage Accuracy: Did the Agent Use the Correct Tool?
Modern AI agents rarely rely solely on language models.
They frequently interact with:
- Search engines
- Databases
- APIs
- Calculators
- Code execution environments
Tool Usage Accuracy measures whether:
- The correct tool was selected
- The tool received correct inputs
- The output was interpreted correctly
For example:
A user asks:
What is 357 × 892?
A strong agent should use a calculator rather than rely on language model reasoning.
Incorrect tool selection often causes avoidable failures.
Task Completion Rate: Did the Agent Successfully Complete the Goal?
Users care less about intermediate steps and more about outcomes.
Task Completion Rate measures whether the agent successfully completed the requested task.
For example:
User Request
Find the latest NVIDIA stock price and summarize today’s movement.
Successful completion requires:
- Retrieving stock information
- Interpreting the data
- Generating a meaningful summary
Even if the individual components work correctly, the overall task may still fail.
Task completion is one of the strongest indicators of real-world usefulness.
Latency: How Fast Is the Agent?
A highly accurate agent that takes thirty seconds to respond is often less useful than a slightly less accurate agent that responds instantly.
Latency should be measured at multiple levels:
- Retrieval latency
- Tool execution latency
- Model inference latency
- Total response latency
Production systems typically track all of these independently.
Which AI Evaluation Frameworks Actually Work?
The AI evaluation ecosystem has matured significantly over the past two years. Several frameworks have emerged as industry standards for evaluating LLMs, RAG pipelines, and autonomous agents.
LangSmith: The Industry Standard for Agent Observability
LangSmith is often described as the Datadog or New Relic of LLM applications.
Rather than simply measuring final outputs, LangSmith provides visibility into the entire execution chain.
It allows developers to inspect:
- Agent decisions
- Prompt execution
- Tool calls
- Retrieval results
- Latency
- Failures
For example, if an agent gives an incorrect answer, LangSmith can show:
User Query –> Retriever –> Retrieved Documents –> Prompt –> LLM Response
This makes debugging significantly easier.
When to Use LangSmith
LangSmith is ideal for:
- LangChain applications
- LangGraph workflows
- Multi-agent systems
- Production monitoring
If you’re building agents with LangChain, LangSmith should be one of the first tools you integrate.
Ragas: The Gold Standard for RAG Evaluation
Ragas was built specifically for Retrieval-Augmented Generation systems.
Unlike general-purpose evaluation tools, Ragas focuses on the unique challenges of RAG architectures.
It automatically calculates metrics such as:
- Faithfulness
- Context Precision
- Context Recall
- Answer Relevance
This makes it extremely useful when optimizing retrieval pipelines.
For example, if your RAG system is generating poor responses, Ragas can help determine whether the issue originates from:
- Retrieval
- Chunking strategy
- Embeddings
- Prompting
- Generation
Instead of guessing, you get measurable evidence.
DeepEval: Unit Testing for AI Applications
DeepEval brings software engineering principles into AI development.
Think of it as pytest for LLM applications.
With DeepEval, you can create automated tests such as:
assert answer_is_factual
assert no_hallucination
assert response_relevance > threshold
This enables continuous integration for AI systems.
Whenever prompts or models change, tests automatically verify that performance has not regressed.
This is particularly valuable in enterprise environments where stability is critical.
OpenAI Evals: Benchmarking Models at Scale
OpenAI Evals is designed for large-scale benchmarking.
It allows developers to compare:
- Multiple models
- Multiple prompts
- Multiple agent architectures
against a common evaluation dataset.
For example, you might compare:
GPT-4 vs Claude vs Llama vs Gemma
using the same evaluation suite.
This makes it easier to make evidence-based model selection decisions.
Phoenix by Arize AI
Phoenix has become increasingly popular for AI observability.
It provides:
- Prompt monitoring
- Retrieval tracing
- Hallucination detection
- Embedding analysis
Many organizations use Phoenix alongside LangSmith to gain deeper visibility into production AI systems.
Its visualization capabilities are particularly useful when debugging RAG pipelines.
Which Evaluation Framework Should You Choose?
The answer depends on your use case.
| Use Case | Recommended Tool |
| LangChain Agents | LangSmith |
| RAG Systems | Ragas |
| Automated Testing | DeepEval |
| Model Benchmarking | OpenAI Evals |
| Production Monitoring | Phoenix |
| Enterprise AI Systems | Combination of all above |
The most mature teams rarely rely on a single framework. Instead, they combine multiple evaluation tools to build a comprehensive evaluation pipeline.
Comparing Popular AI Agent Evaluation Frameworks
| Framework | Primary Focus | Best For | Key Metrics | Production Ready |
| LangSmith | Observability & Tracing | LangChain / LangGraph applications | Latency, traces, tool calls, workflows | Yes |
| Ragas | RAG Evaluation | Retrieval-Augmented Generation systems | Faithfulness, Context Precision, Context Recall | Yes |
| DeepEval | Automated Testing | LLM and agent testing pipelines | Hallucination, Answer Correctness, Bias | Yes |
| Phoenix | Monitoring & Observability | Production AI systems | Retrieval quality, hallucinations, tracing | Yes |
| OpenAI Evals | Benchmarking | Model comparison and benchmarking | Accuracy, pass/fail evaluation | Yes |
| AgentBench | Agent Benchmarking | Autonomous agent evaluation | Planning, reasoning, task completion | Research-focused |
| GAIA | General AI Assistant Evaluation | Advanced agent systems | Real-world task performance | Research-focused |
How do you evaluate a RAG system?
RAG evaluation requires testing two components separately:
- Retrieval
- Generation
Many developers incorrectly evaluate only the generated answer.
A better approach is:
Question –> Retrieved Documents –> Evaluate Retrieval –> Generated Answer –> Evaluate Response
This helps identify whether failures originate from retrieval or generation.
Real-World Case Studies: Why AI Agent Evaluation Matters
Case Study 1: Customer Support AI Assistant
Imagine a customer support agent deployed by an e-commerce company. During testing, the team observed an answer accuracy of nearly 90%, which initially seemed impressive. However, after deploying the system, customers began receiving incorrect refund and return policy information.
The root cause was not the language model itself. The retrieval system was fetching outdated policy documents from the knowledge base.
After introducing RAG-specific evaluation metrics such as Context Precision and Faithfulness, the team discovered that nearly 30% of retrieved documents were irrelevant. By improving retrieval quality, customer satisfaction increased significantly without changing the underlying LLM.
This example demonstrates why evaluating only the final answer is insufficient. The entire AI pipeline must be measured.
Case Study 2: Financial Research Agent
A financial services company developed an AI research assistant capable of analyzing quarterly reports and generating summaries for analysts.
Initial testing focused primarily on response quality. The generated reports appeared accurate and professionally written.
However, a deeper evaluation revealed that the agent occasionally invented financial metrics that were not present in the source documents. While the hallucination rate was relatively low, even a small percentage of fabricated financial information posed significant risk.
By implementing Faithfulness and Hallucination Rate monitoring, the company reduced unsupported claims and improved trust in the system.
The lesson is simple:
A highly fluent answer is not necessarily a trustworthy answer.
Case Study 3: Multi-Agent Research System
A research organization built a multi-agent workflow consisting of:
- A retrieval agent
- A planning agent
- A summarization agent
- A verification agent
Initially, the team evaluated only the final report.
The problem was that failures became difficult to diagnose. Was the retriever failing? Was the planner making poor decisions? Was the summarizer losing important information?
By introducing agent-level evaluation metrics and LangSmith tracing, they could inspect each stage individually.
This reduced debugging time dramatically and improved overall system reliability.
LLM-as-a-Judge
One of the biggest challenges in AI evaluation is that many responses cannot be evaluated using simple exact-match comparisons. Traditional software testing works well when outputs are deterministic, but AI systems often generate multiple valid answers to the same question.
For example, consider the following responses:
Expected: Paris
Response A: Paris
Response B: The capital city of France is Paris.
Response C: France’s capital is Paris.
All three responses are correct, yet traditional string comparison would treat them differently.
This challenge led to the development of LLM-as-a-Judge, where a powerful language model is used to evaluate another model’s outputs.
Instead of checking exact text matches, the evaluator assesses qualities such as:
- Correctness
- Relevance
- Completeness
- Faithfulness
- Helpfulness
- Safety
The evaluation model receives the user query, the expected answer, and the generated answer. It then assigns a score and provides reasoning for its decision.
The workflow typically looks like this:
Question –> Agent Response –> Judge LLM –> Score + Explanation
This approach is increasingly used by companies because it scales much better than human evaluation while capturing semantic meaning more effectively than traditional metrics.
However, LLM-as-a-Judge is not perfect. It introduces several challenges:
- Evaluator bias
- Model preference bias
- Cost of running additional LLM calls
- Inconsistent scoring across models
To improve reliability, organizations often use multiple judge models and aggregate their scores.
Today, LLM-as-a-Judge is widely used in frameworks such as DeepEval, LangSmith, and OpenAI Evals.
AgentBench
Most traditional AI benchmarks focus on question-answering tasks. While useful, these benchmarks do not accurately represent how modern AI agents operate.
AgentBench was created to address this limitation.
Instead of asking isolated questions, AgentBench evaluates an agent’s ability to interact with environments, use tools, plan actions, and complete multi-step objectives.
The benchmark includes tasks such as:
- Database querying
- API interaction
- Knowledge retrieval
- Software development
- Web navigation
- Decision making
For example, rather than asking:
What is the capital of France?
AgentBench might ask the agent to:
Find the population of the largest city in France,
compare it with Berlin,
and summarize the results.
Successfully solving this task requires:
- Information retrieval
- Multi-step reasoning
- Tool selection
- Result synthesis
This makes AgentBench significantly more representative of real-world AI agent behavior.
One of the most valuable aspects of AgentBench is that it measures failures at multiple stages of the reasoning process. An agent may retrieve the correct information but fail during planning. Another agent may plan correctly but misuse tools.
By breaking performance into components, AgentBench helps developers identify where improvements are needed.
For developers building autonomous AI systems, AgentBench is one of the most realistic evaluation frameworks currently available.
GAIA Benchmark
As AI systems become more capable, researchers have started questioning whether traditional benchmarks accurately reflect real-world intelligence.
This led to the creation of GAIA (General AI Assistant Benchmark).
Unlike many benchmarks that focus on narrow tasks, GAIA evaluates whether AI agents can solve realistic problems that humans encounter in everyday work.
A typical GAIA task may require:
- Searching the web
- Reading multiple sources
- Extracting information
- Performing calculations
- Combining evidence
- Producing a final answer
For example, a GAIA challenge might look like:
Find the release date of a product,
calculate how many years it has been available,
compare it with a competitor,
and summarize the differences.
This task requires multiple reasoning steps and cannot be solved through simple memorization.
GAIA categorizes problems into different difficulty levels:
| Level | Description |
| Level 1 | Simple reasoning tasks |
| Level 2 | Multi-step information retrieval |
| Level 3 | Complex real-world problem solving |
Because GAIA evaluates practical intelligence rather than benchmark memorization, it has become one of the most respected agent evaluation frameworks in the AI community.
Many modern agent systems that perform well on standard benchmarks still struggle on GAIA because real-world tasks require planning, adaptability, and tool use.
Memory Evaluation
Memory is rapidly becoming one of the most important components of modern AI agents.
Traditional chatbots are stateless. They respond based only on the current conversation context. Memory-enabled agents, however, can store and retrieve information across interactions.
This introduces entirely new evaluation challenges.
The key question is no longer:
Did the agent answer correctly?
Instead, we ask:
Did the agent remember the right information at the right time?
Consider this example.
Stored Memory
User is researching Quantum Machine Learning.
User Query
What research topic am I currently working on?
Expected Response
You are researching Quantum Machine Learning.
A memory-enabled agent must:
- Retrieve the correct memory
- Ignore irrelevant memories
- Incorporate the memory into the response
- Maintain consistency over time
To evaluate memory systems, researchers typically measure four dimensions.
Memory Recall
Memory Recall measures whether the correct memory was retrieved when needed.
Low recall means the information exists in storage but was never surfaced to the model.
Memory Precision
Memory Precision measures how many retrieved memories are actually relevant.
If the system retrieves ten memories but only one is useful, precision is low.
Poor precision often leads to:
- Prompt bloat
- Higher costs
- Context pollution
- Reduced response quality
Memory Utilization
Retrieving a memory is not enough.
The model must actually use that memory in its response.
Many systems retrieve relevant memories correctly but fail to incorporate them into the final answer.
Memory Utilization measures whether retrieved memories influence model behavior.
Memory Consistency
As conversations grow, memory systems may accumulate conflicting information.
For example:
Memory 1:
User’s favourite language is Python.
Memory 2:
User’s favourite language is Rust.
A robust memory system should identify conflicts and maintain consistency over time.
Memory consistency evaluation helps measure the long-term reliability of memory-enabled agents.
Multi-Agent Evaluation
Evaluating a single AI agent is already challenging. Evaluating a multi-agent system introduces an entirely new level of complexity.
In a multi-agent architecture, different agents often perform specialized roles:
Retriever Agent –> Planner Agent –> Research Agent –> Writer Agent
The final output depends on every agent performing its role correctly.
A failure can occur at multiple points:
- Incorrect retrieval
- Poor planning
- Faulty reasoning
- Hallucinated synthesis
This means developers must evaluate:
Individual Agent Performance
How well each agent performs its assigned task.
Collaboration Quality
How effectively agents exchange information.
Communication Efficiency
Whether important information is lost during handoffs.
End-to-End Task Success
Whether the complete workflow achieves the desired objective.
As multi-agent systems become more common, evaluating collaboration and coordination will become just as important as evaluating reasoning ability.
Creating the Evaluation Dataset
Before evaluating an AI agent, we first need a benchmark dataset. This dataset acts as our ground truth and contains the expected answers, agent responses, selected tools, and response latency. In production environments, evaluation datasets are often created from user interactions, test suites, or manually curated benchmark questions. For this tutorial, we will create a small sample dataset that allows us to demonstrate the evaluation process.
import pandas as pd
evaluation_data = [
{
"question": "What is the capital of France?",
"expected_answer": "Paris",
"agent_answer": "Paris",
"expected_tool": "none",
"used_tool": "none",
"latency": 1.2
},
{
"question": "What is 25 * 17?",
"expected_answer": "425",
"agent_answer": "425",
"expected_tool": "calculator",
"used_tool": "calculator",
"latency": 0.8
}
]
df = pd.DataFrame(evaluation_data)
df.head()Calculating Agent Accuracy
Accuracy is the most common evaluation metric and measures how often the AI agent produces the correct answer. Although accuracy alone cannot fully capture agent performance, it serves as a useful starting point for understanding overall system quality.
def calculate_accuracy(df):
correct = 0
for _, row in df.iterrows():
if row["expected_answer"].lower() == row["agent_answer"].lower():
correct += 1
return correct / len(df)
Measuring Tool Usage Accuracy
Many modern AI agents rely on external tools such as APIs, search engines, databases, and calculators. This metric evaluates whether the agent selected the correct tool for the task. A strong agent should not only provide correct answers but also use the appropriate tools when necessary.
def calculate_tool_accuracy(df):
correct_tools = 0
for _, row in df.iterrows():
if row["expected_tool"] == row["used_tool"]:
correct_tools += 1
return correct_tools / len(df)
Detecting Hallucinations
Hallucinations occur when an AI system generates information that is unsupported or incorrect. Monitoring hallucination rate is critical because it directly impacts trust and reliability. This simple implementation compares the generated answer with the expected answer to estimate hallucination frequency.
def hallucination_rate(df):
hallucinations = 0
for _, row in df.iterrows():
if row["expected_answer"].lower() != row["agent_answer"].lower():
hallucinations += 1
return hallucinations / len(df)
Calculating Task Completion Rate
Users ultimately care about whether the agent successfully completes the requested task. This metric combines answer correctness and tool selection to determine whether the overall objective was achieved. Task completion rate is often one of the most important KPIs in production AI systems.
def task_completion_rate(df):
completed = 0
for _, row in df.iterrows():
if row["expected_answer"].lower() == row["agent_answer"].lower():
if row["expected_tool"] == row["used_tool"]:
completed += 1
return completed / len(df)
Measuring Response Latency
Fast responses are just as important as accurate responses. Latency helps us understand how long the system takes to process user requests. In enterprise systems, latency is often broken down into retrieval time, tool execution time, and model inference time.
def average_latency(df):
return df["latency"].mean()
Generating a Complete Evaluation Report
Once all metrics have been calculated, we can generate a consolidated report. This provides a quick overview of the agent’s performance and helps identify areas that require improvement.
accuracy = calculate_accuracy(df)
tool_accuracy = calculate_tool_accuracy(df)
hallucination = hallucination_rate(df)
task_completion = task_completion_rate(df)
latency = average_latency(df)
print("===== AI Agent Evaluation Report =====")
print(f"Accuracy: {accuracy:.2%}")
print(f"Tool Accuracy: {tool_accuracy:.2%}")
print(f"Hallucination Rate: {hallucination:.2%}")
print(f"Task Completion Rate: {task_completion:.2%}")
print(f"Average Latency: {latency:.2f} sec")
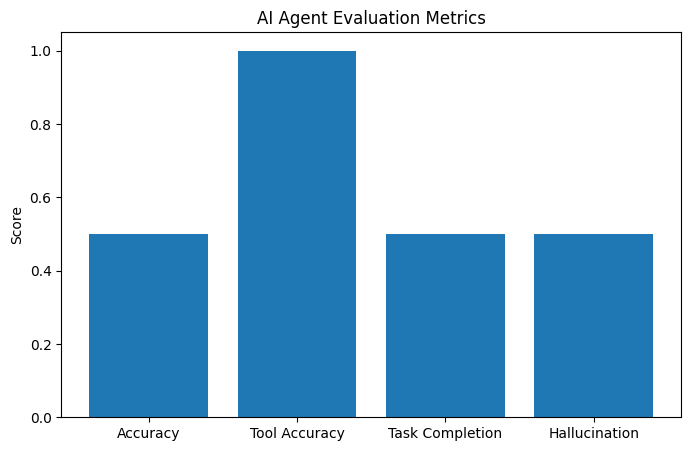
Visualizing Agent Performance
Evaluation metrics become much easier to understand when visualized. A simple bar chart allows us to compare performance across multiple dimensions and quickly identify strengths and weaknesses in the system.
import matplotlib.pyplot as plt
metrics = {
"Accuracy": accuracy,
"Tool Accuracy": tool_accuracy,
"Task Completion": task_completion,
"Hallucination": 1 - hallucination
}
plt.figure(figsize=(8,5))
plt.bar(
metrics.keys(),
metrics.values()
)
plt.title("AI Agent Evaluation Metrics")
plt.ylabel("Score")
plt.show()
Evaluating a Real LangChain Agent
So far, we have worked with sample responses. In practice, evaluation is usually performed directly on a running AI agent. The following example shows how benchmark questions can be automatically sent to a LangChain agent, allowing developers to collect responses and calculate metrics at scale.
questions = [
"What is the capital of France?",
"What is 25 * 17?",
"Who founded Microsoft?"
]
for question in questions:
response = agent.invoke(question)
print("="*50)
print("Question:", question)
print("Answer:", response)
Calculating an Overall Agent Score
Individual metrics provide detailed insights, but teams often need a single KPI for comparing different versions of an agent. This weighted score combines multiple evaluation metrics into a single performance indicator that can be tracked over time.
final_score = (
accuracy * 0.4 +
tool_accuracy * 0.2 +
task_completion * 0.3 +
(1 - hallucination) * 0.1
)
print(f"Overall Agent Score: {final_score:.2%}")
Conclusion
The best AI agents are not necessarily the ones with the largest models. They are the ones that can be measured, monitored, and improved continuously.
Evaluation transforms AI development from experimentation into engineering.
By tracking metrics such as accuracy, hallucination rate, retrieval quality, task completion, and latency, developers gain a clear understanding of where their systems succeed and where they fail.
As AI agents become increasingly autonomous, evaluation will become one of the most important skills in AI engineering.
The future belongs not only to those who can build AI agents, but to those who can reliably measure them.
Frequently Asked Questions
Q1. What is the most important metric for AI agents?
Accuracy is important, but relying on a single metric is risky. Most production systems track accuracy, hallucination rate, retrieval quality, latency, and task completion together.
Q2. Which framework is best for evaluating RAG systems?
Ragas is currently one of the most popular frameworks because it provides retrieval-specific metrics such as faithfulness, context precision, and context recall.
Q3. Can AI agent evaluation be automated?
Yes. Frameworks like LangSmith, DeepEval, and Ragas allow automated testing and benchmarking across large datasets.
Q4. How often should AI agents be evaluated?
Production AI systems should be evaluated continuously whenever prompts, models, tools, retrieval pipelines, or memory systems are updated.
Q5. Why do AI agents fail despite having strong models?
Failures often occur in retrieval, memory, tool selection, or prompt design rather than in the language model itself.
Q6. Is human evaluation still necessary?
Yes. Automated metrics are valuable, but human evaluation remains important for measuring usefulness, clarity, and overall user experience.
Popular Posts
- Loop Engineering Explained: From Prompt Engineering to Self-Prompting AI Agents
- Build Your First MCP Server with FastMCP: A Complete Python Tutorial
- MCP vs Function Calling: Key Differences Explained (2026)
- What Is Model Context Protocol (MCP) – A Complete Guide for AI Developers
- MCP Primitives Explained: Tools, Resources, and Prompts With Real Examples
