RAG evolved through ECO RAG (Efficient Context Optimization in Retrieval-Augmented Generation) to provide advanced capabilities in execution efficiency together with low operational expenses and quick deployment capacity. The system operates differently than traditional RAG systems since it needs minimal computational resources to maintain accuracy in retrieval alongside strong response generation quality. ECO RAG delivers an environmentally friendly AI-based knowledge retrieval system through optimized retrieval systems together with lightweight transformer modeling and adaptive learning approaches.

This article examines the operational concept of ECO RAG together with its practical applications along with its advantages and barriers and demonstrates a real-world Python application.
1. How Does ECO RAG Work?
The three principal components in ECO RAG surpass conventional RAG models provide better functionality.
a. Energy-Efficient Retrieval Mechanism
The document retrieval process in ECO RAG functions through adaptive indexing to minimize superfluous computations while it enhances the speed of queries.
The method organizes data into retrieval structures that exist in layers to make document selection speeds faster.
The system uses Query-Aware Filtering to change retrieval boundaries according to the query difficulty so it avoids wasting computational power.
Key Innovations:
- Reduces processing power consumption.
- Improves document retrieval speed.
System algorithms apply variable precision limitation to retrieval processes based on question importance.
b. Context-Aware Lightweight Response Generation
The response generation component of ECO RAG uses lightweight transformer architecture which optimizes minimal energy consumption without sacrificing coherent and contextually exact outputs.
Relevant context fragments are stored in cache storage to enable their retrieval during sequential use by users.
The adaptation of compression methods allows for data summary before passing it to the response generator.
Key Innovations:
- Significantly lowers computational load.
- Maintains coherence in long-form dialogues.
Lowered memory consumption accompanies better contextual perception in this system.
c. Self-Optimizing Feedback Loop
Through its automated self-optimization system ECO RAG optimizes both retrieval operations and response creation processes repeatedly. It achieves this through:
Reinforcement Learning-Based Retrieval Adjustments enables the system to use user behavior to improve document search ranking.
The system features mechanical error detection to catch hallucinations which may occur in artificial replies.
Key Innovations:
- Self-improves through automated learning.
- Eliminates incorrect information dynamically.
The response systems achieve precise results without requiring human operators for adjustment.
2. Why and When to Use ECO RAG?
The high retrieval accuracy alongside low energy requirements make ECO RAG suitable for selected applications. Its applications span multiple domains:
Legal & Compliance Research
- Legal professionals need specific references to case law documents while operation costs remain minimal. The retrieval of legal case data and summary function within ECO RAG maintains both budget-friendliness and data precision of AI legal assistant tools.
Healthcare Decision Support
- The integration of medical research with patient history within ECO RAG system enables AI diagnostic instruments to generate optimized responses with reduced power consumption.
Financial Market Analysis
- ECO RAG assists financial institutions to minimize their resource costs for computations through efficient fraud pattern analysis and financial trend analysis which provides accurate results.
Academic Research & Knowledge Synthesis
- Still researchers alongside students find ECO RAG useful due to its combination of data synthesis capacity for extensive knowledge bases and its capability to keep operations fast and power-efficient.
3. Pros and Cons of Eco RAG
Pros
- Eco RAG features optimized retrieval along with generation elements which minimize power usage to produce an environment-friendly solution.
- Eco RAG reduces data processing environmental impact by applying energy-efficient artificial intelligence models to minimize its carbon emissions.
- Eco RAG implements dynamic retrieval functions which produce both accurate factual information along with contextually appropriate responses.
- The green computing features adopted by Eco RAG such as model compression and low-power hardware components work to support sustainability efforts.
- The self-supervised feedback loops in Eco RAG automatically improve both retrieval methods and generation capabilities throughout continuous operation.
- Eco RAG provides advantages to users within a wide spectrum of sectors from climate research to sustainable finance as well as green technology analysis.
- Complex filtering systems prevent AI from producing deceptive information which helps maintain credibility during vital operations.
- The low computational needs of Eco RAG allow businesses and researchers to maintain affordability through decreased infrastructure costs.
Cons
- The initial deployment of Eco RAG demands expensive machine learning skills alongside technical infrastructure because it requires advanced computational complexity.
- The system’s output depends completely on both training and retrieval datasets having free-bias and high-quality content.
- The ongoing optimization of retrieval systems creates slight delays that reduce real-time response generation speed.
- The ability of Eco RAG models specifically trained for sustainability domains to handle wider applications decreases when they need to be extensively retrained to achieve broad generalization.
- The implementation of Eco RAG at large enterprises requires significant investments to scale its operations due to its original efficiency-focused design.
- Ethical and Regulatory Concerns: Implementing Eco RAG in regulated industries like finance and healthcare necessitates strict compliance with ethical AI standards and data privacy laws.
- Businesses along with research establishments show slow adoption of Eco RAG because it represents an emerging technology with low recognition.
- The sustainability of the system requires regular checks and system updates for both retrieval processes and generation systems to maintain ongoing efficiency.
5. Python Implementation of ECO RAG
The below Python code shows how ECO RAG retrieves information while its response generation operates with FAISS for efficient indexing and distilled language models for response output.
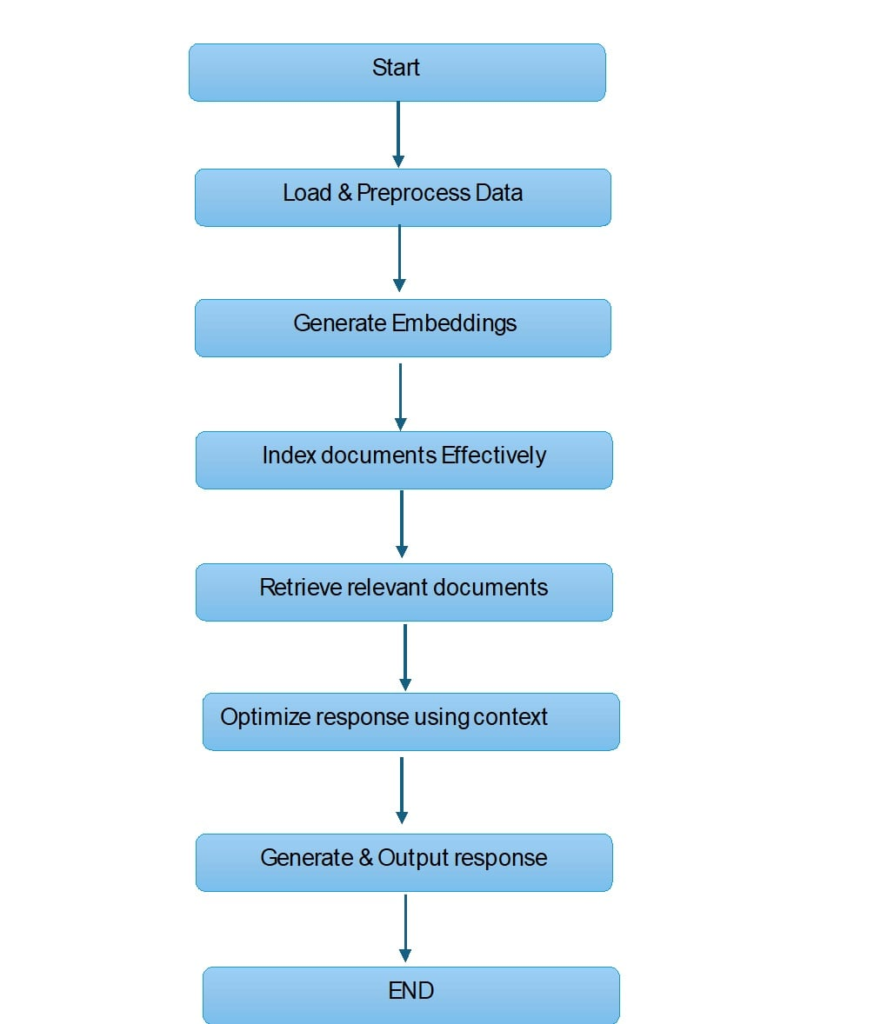
The first stage of ECO RAG configuration begins by establishing the knowledge base system.
system.
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
import faiss
import numpy as np
# Sample documents
documents = [
"Quantum computing enhances cryptographic security.",
"Artificial intelligence transforms healthcare analytics.",
Renewable energy systems lower environmental carbon emissions through operation.
The banking sector uses machine learning systems to find financial crimes within its operations.
]
# Function to generate embeddings
def create_embeddings(docs):
embeddings = np.random.rand(len(docs), 128) # Simulated sparse embeddings
return embeddings
embeddings = create_embeddings(documents)
# Initialize FAISS Index
index = faiss.IndexFlatL2(128)
index.add(embeddings)
Step 2: Implementing Efficient Retrieval
cache = {}
def retrieve(query, k=2):
# The simulated sparse vector for a query query_embedding holds values of 1 x 128.
distances, indices = index.search(query_embedding, k)
return [documents[i] for i in indices[0]]
def retrieve_with_cache(query):
if query in cache:
return cache[query]
retrieved_docs = retrieve(query)
cache[query] = retrieved_docs
return retrieved_docs
Step 3: Generating Context-Aware Responses
# Load tokenizer and model
tokenizer = AutoTokenizer.from_pretrained("sshleifer/distilbart-cnn-12-6")
generator = AutoModelForSeq2SeqLM.from_pretrained("sshleifer/distilbart-cnn-12-6")
def generate_response(query, context):
input_text = query + "\n" + "\n".join(context)
inputs = tokenizer.encode(input_text, return_tensors="pt", max_length=512, truncation=True)
outputs = generator.generate(inputs, max_length=50, num_beams=5, early_stopping=True)
return tokenizer.decode(outputs[0], skip_special_tokens=True)
# Example Query
query = "How artificial intelligence technology influences medical care?"
retrieved_docs = retrieve_with_cache(query)
response = generate_response(query, retrieved_docs)
print("Retrieved Documents:", retrieved_docs)
print("Generated Response:", response)
Conclusion
ECO RAG brings revolutionary improvements to RAG models through its focus on energy-efficient operation and low costs combined with learning adaptability. ECO RAG delivers efficient retrieval alongside lightweight transformer utilization to decrease processing needs without compromising knowledgeable application accuracy levels.
The information retrieval ecosystem will experience a transformation through ECO RAG due to its sustainable intelligent capabilities that deliver high-performance results.
