
Autonomous retrieval generation systems namely Auto RAG represent the next iteration of Retrieval-Augmented Generation (RAG) systems that improve real-time context-based response generation. The retrieval mechanism in Auto RAG differs from static RAG models because this system dynamically optimizes its retrieval process through automated feedback loops as well as self-supervised learning and context-aware adaptation. The innovative design of Auto RAG delivers coherent responses with complete factual accuracy while lowering the occurrence of hallucinations throughout healthcare and legal research and finance applications and customer service operations. The article conducts a complete examination of Auto RAG that investigates its technical framework alongside its operational processes and practical applications and advantages and obstacles and demonstrates its functioning through Python programming. The article explains Auto RAG’s system for improving retrieved data while reducing mistakes and accommodating evolving user inquiries during real-time operations.
If you’re interested in exploring more RAG techniques, here are some valuable resources that provide deeper insights into different approaches:
Replug RAG: The Ultimate Guide to Retrieval-Augmented Generation
The Ultimate Guide to Memo RAG: Everything You Need to Know
A Comprehensive Guide on Attention-Based RAG
1. How Does Auto RAG Work?
Traditional RAG models undergo refinement thanks to three important elements in Auto RAG.
a. Autonomous Retrieval Optimization
The document selection and ranking system of standard retrieval methods receives enhancements from Auto RAG through its dynamic process control. The system utilizes reinforcement learning techniques together with self-supervised feedback protocols to improve the document-query alignment in retrieved results.
Key Innovations:
- The selection process of documents undergoes adaptive refinement through user interactions during retrieval operations.
- Through the application of reinforcement learning systems can dynamically improve the documentation ranking at the moment of user interaction.
b. Memory-Augmented Response Generation
The Auto RAG system connects response generation to an adaptive memory which collects user interactions and stored documents and previously generated answers. Through its memory system the system preserves long-term context information making it suited for maintaining multi-turn dialogues.
Key Innovations:
- The system uses cross-attention mechanisms to combine retrieved documents perfectly into response content.
- The system uses improved memory functions during response generation to maintain consistent context.
- The system contains control systems which stop the inclusion of false information during retrieval.
c. Self-Supervised Feedback Loop
Auto RAG uses automatic feedback processing to improve its retrieval system based on how well the produced responses meet the quality standards. The system uses past retrieval performance to make dynamic changes in search queries and document re-ranking and embedding updates.
Key Innovations:
- Continuous learning refines retrieval efficiency.
- User-input triggers an automatic system to change how retrieved content ranks.
- The process of self-supervised feedback enables automated accuracy enhancement as it requires no human involvement.
2. Why and When to Use Auto RAG?
The system Auto RAG stands out for handling applications needing exact fact verification with contextual learning abilities and automatic learning from data. Multiple practical applications demonstrate how important Auto RAG becomes.
Legal & Compliance Research
- Professional legal operators need precise references of court cases which maintain proper context. The Auto RAG system improves legal AI assistants by improving retrieval algorithms through continuous learning and redesign while learning from modifications to case law fundamental interpretations and new case law admission.
Healthcare Decision Support
- Auto RAG maintains the freshness of AI-powered diagnostic systems and clinical decision-support tools by ensuring they receive latest medical research. The combination of past and present patient records retrieval with synthesis having positive effects on diagnostic precision and treatment planning.
Customer Support Automation
- Customer service platforms powered by AI draw benefits from Auto RAG which enables them to obtain and customize responses based on previous customer exchanges. The system enhances customer satisfaction through appropriate solutions drawn from previous client interactions.
Financial Risk Assessment & Fraud Detection
- Auto RAG enables financial institutions to perform risk assessment by collecting fraud patterns together with market trends and regulatory changes from previous records. Auto RAG maintains an updated knowledge base for real-time fraud detection and compliance monitoring purposes.
Academic Research & Knowledge Synthesis
- Students and researchers benefit from Auto RAG by utilizing the system to analyze numerous research publications effectively. The platform merges information from various sources to support research literature evaluations along with assisting researchers in forming hypotheses.
3. Advantages of Auto RAG
- Adaptive Learning: Auto RAG refines its retrieval system continuously through feedback loops, dynamically adjusting its document selection and ranking processes based on real-time interactions.
- Reduced Hallucination: Unlike traditional models that may generate misleading information, Auto RAG leverages reinforcement learning to filter out inaccurate data and ensure factually consistent responses.
- Enhanced Context Awareness: The system retains memory of prior interactions and retrieved documents, allowing it to provide more coherent responses in multi-turn conversations and long-form discussions.
- Improved Retrieval Accuracy: By continuously optimizing its ranking algorithms, Auto RAG ensures that the most relevant and contextually appropriate documents are retrieved for response generation.
- Scalability: Designed for enterprise applications, Auto RAG efficiently handles large-scale knowledge bases and adapts to real-time updates, making it suitable for dynamic and evolving domains.
4. Challenges of Auto RAG
- Computational Intensity: The iterative retrieval and memory-enhancement mechanisms require significant processing power, making deployment costly and demanding in high-load environments.
- Data Quality Dependence: The system’s accuracy is highly dependent on the quality, relevance, and bias-free nature of its training and retrieval data, requiring continuous dataset curation.
- Latency Issues: The continuous optimization of retrieval and ranking may introduce delays, particularly in real-time applications where low-latency response generation is critical.
- Implementation Complexity: Deploying an effective Auto RAG system demands domain-specific expertise in machine learning, natural language processing, and reinforcement learning, along with ongoing maintenance and performance tuning.
5. Python Implementation of Auto RAG
The following section provides a step-by-step guide to develop Auto RAG with transformer models together with FAISS for retrieval operations.
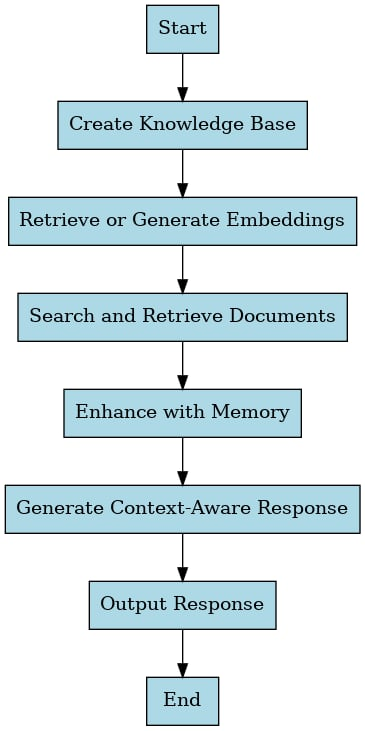
Step 1. The establishment of a knowledge base
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
import faiss
import numpy as np
# Sample documents
documents = [
"Quantum computing enhances cryptographic security.",
"Artificial intelligence transforms healthcare analytics.",
Renewable energy systems decrease environmental carbon footprints through their operation.
Through its algorithms machine learning identifies financial crimes running within banking organizations.
]
# Function to generate embeddings
def create_embeddings(docs):
embeddings = np.random.rand(len(docs), 128) # Simulated embeddings
return embeddings
embeddings = create_embeddings(documents)
# Initialize FAISS Index
index = faiss.IndexFlatL2(128)
index.add(embeddings)
Step 2: Implementing Autonomous Retrieval
cache = {}
def retrieve(query, k=3):
The query_embedding variable contains a 1 x 128 placeholder random value.
distances, indices = index.search(query_embedding, k)
return [documents[i] for i in indices[0]]
def retrieve_with_memory(query):
if query in cache:
return cache[query]
retrieved_docs = retrieve(query)
cache[query] = retrieved_docs # Store in memory
return retrieved_docs
Step 3: Generating Context-Aware Responses
# Load tokenizer and model
tokenizer = AutoTokenizer.from_pretrained("facebook/bart-large-cnn")
generator = AutoModelForSeq2SeqLM.from_pretrained("facebook/bart-large-cnn")
def generate_response(query, context):
input_text = query + "\n" + "\n".join(context)
inputs = tokenizer.encode(input_text, return_tensors="pt", max_length=512, truncation=True)
outputs = generator.generate(inputs, max_length=50, num_beams=5, early_stopping=True)
return tokenizer.decode(outputs[0], skip_special_tokens=True)
# Example Query
query = "What are the effects of artificial intelligence on healthcare facilities?"
retrieved_docs = retrieve_with_memory(query)
response = generate_response(query, retrieved_docs)
print("Retrieved Documents:", retrieved_docs)
print("Generated Response:", response)
Conclusion
The Auto RAG framework builds upon traditional RAG through its implementation of autonomous retrieval functions and memory-augmented response generation and self-supervised feedback looping mechanism. The improvements bring about more precise recall and less hallucinations combined with better contextual comprehension. Auto RAG exists as an important transformative solution that helps knowledge-intensive domains maintain continuous learning while adapting to new scenarios despite facing computational complexities.
Future Exploration
- Auto RAG functions specifically within healthcare and finance sectors as well as legal frameworks.
- The system implements optimized feedback mechanisms which help decrease computational expenses.
