CORAG represents the latest advancement in AI systems devoted to knowledge retrieval and response generation which employs Context-Optimized Retrieval-Augmented Generation approaches. The refined RAG models of CORAG improve performance by using optimized retrieval systems and lightweight transformer models and automatic feedback analysis.

The following piece explores how CORAG works alongside explanations about its applications alongside its advantages and disadvantages as well as a practical implementation using the python programming language.
1. How Does CORAG Work?
Traditional RAG models receive new and improved capabilities from CORAG through its fundamental structure that includes three core elements.
a. Context-Optimized Retrieval Mechanism
The retrieval system uses hierarchical structures for processing data which leads to quick access of related information.
Key Innovations:
- The system performs query-aware filtering because it modifies retrieval parameters to match different query difficulty levels.
- The system employs adaptive indexing as a method to speed up data retrieval operations and improve organization capabilities.
- The system decreases operational energy usage by implementing precise retrieval protocol algorithms.
b. Context-Aware Response Generation
Key Innovations:
- The system maintains essential context pieces in a data storage system that delivers better performance during successive query requests.
- The response generator receives compressed summary content that results from compression-based summarization.
- The system maintains small memory usage levels and delivers precise contextual information.
c. Self-Optimizing Feedback Loop
Through automated learning CORAG improves its processes of retrieval and generation mechanisms on a continuous basis.
Key Innovations:
- The system employs reinforcement learning for ranking adjustment which improves document selection quality.
- Error detection models enable the system to find and address hallucinations that occur in generated responses.
- Automatic accuracy improvements happen without the necessity of human manual work.
2. Why and When to Use CORAG?
Apps that need accurate retrieval performance together with minimal costs and adaptive systems would benefit best from using CORAG. It is particularly useful in:
Legal & Compliance Research
- Facilitates quick retrieval of legal case precedents with minimal energy consumption.
- The application provides simplified means for legal professionals to conduct efficient analysis of case history documentation and statutes and legal documents.
- Automated text summaries enable personnel to cut down their workload for processing extensive legal materials as well as court decisions.
Healthcare Decision Support
- AI diagnostics receives support through the combination of patient records with large medical literature databases through this system.
- Medical practitioners and healthcare staff use analysis of both patient historical records and current scientific studies to base their clinical choices.
- It improves clinical choices through the detection of treatment patterns in patient records combined with recommendations from evidence-based medicine.
- The system operates with decreased computational needs but achieves accurate analysis in artificial intelligence healthcare operations.
Financial Market Analysis
- The detection of financial fraud becomes more efficient because this system enables fast analysis of needed records in optimal timelines.
- The system performs better investment selection through its ability to collect real-time financial information from multiple data sources.
- Financial trends become more detectable through the help of this artificial intelligence system thus enabling better risk assessments and portfolio management operations.
- The system reduces the amount of needed processing power to maintain exact examination of stock market dynamics alongside economic indicators.
Academic Research & Knowledge Synthesis
- The system enables researchers together with students to quickly access academic papers and studies because of its functional capabilities.
- The tool completes literature reviews automatically by analyzing important results extracted from extensive academic databases.
- The system allows educational institutions along with libraries to operate digital repositories more effectively.
- The system helps discover new knowledge because it retrieves information precisely while honoring its contextual meaning.
3. Pros and Cons of CORAG
Pros:
- Through improved retrieval and response processes the overall computational expenses decrease while data efficiency and redundant processing expenses decrease.
- CORAG’s energy-efficient design reduces power usage that enables managers to use it as a sustainable AI system for data retrieval operations.
- The dynamic retrieval method used for factual accuracy puts real-time priority on high-relevance documents.
- The environmental impact reduces due to lightweight models and energy-efficient computations that constitute green computing features.
- The system demonstrates wide reach across various domains from law to medicine and finance and academia thus enabling numerous industries to use its implementation.
- Advanced procedures monitor misinformation spread and block its transmission through comparison of content against official sources.
- Enhanced computational performance helps businesses reduce their computing needs so they invest less in hardware for both commercial and research purposes.
- Industrial operations leverage automated document processing to make beneficial decisions through efficient information retrieval methods thus enhancing productivity throughout industries.
Cons:
- The deployment of the system requires experts who possess specific knowledge in machine learning along with domain expertise which leads to challenging initial implementation.
- The performance of CORAG depends heavily on data quality because inaccurate or substandard training data sets lead to accuracy diminishment.
- Real-time responses from the system may face delays because the optimization systems and learning processes are active.
- The ability of CORAG to generalize a new domain remains restricted unless it receives extensive retraining at the present time.
- Any enterprise-level implementation of CORAG demands major investments for hardware infrastructure and model optimization to achieve large-scale deployment.
- Organizations handling healthcare and finance data must follow exact ethical guidelines for AI technologies which adds extra challenges to regulatory requirements.
- The slow adoption occurs because CORAG stands as a new technology that requires enterprises to raise awareness and construct trust relationships across industries.
- Operations must continuously check systems and maintain them to keep efficiency together with accuracy and adaptability operational throughout their lifespan.
- Any security vulnerabilities can emerge because retrieval mechanisms need appropriate authorization protection along with data breach and adversarial attack defences.
- Implementing CORAG technology involves substantial work to integrate it with existing IT systems because extensive customization and system compatibility development is needed for full adoption.
4. Python Implementation of CORAG
Below is a Python-based implementation of CORAG for retrieving and summarizing information from PDF documents.
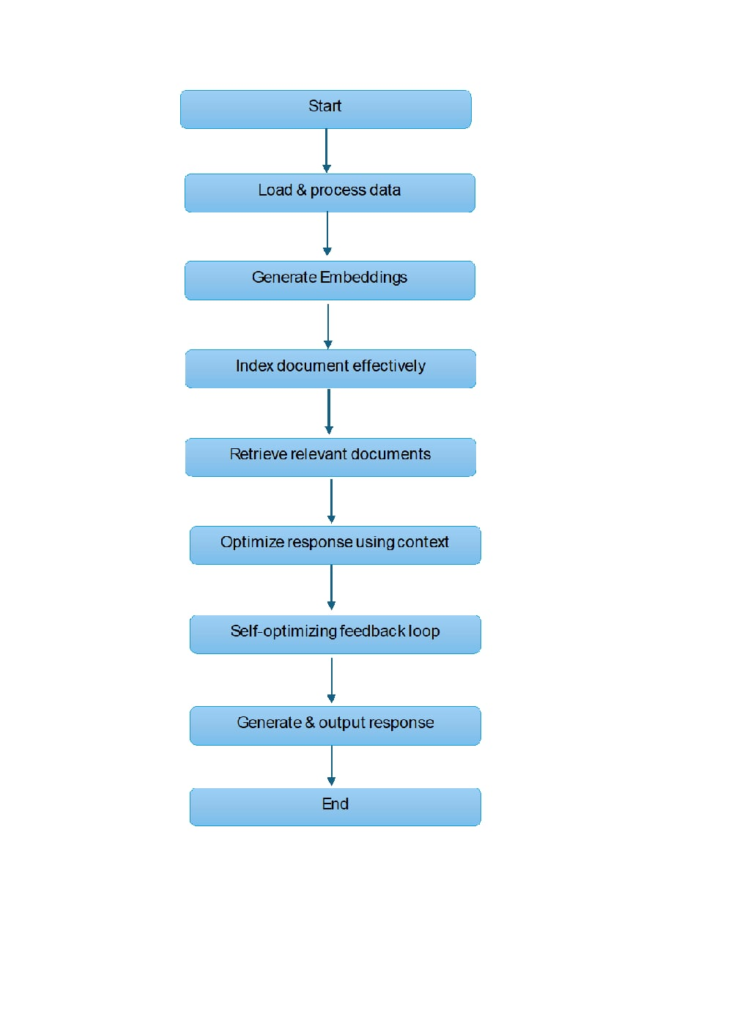
Step 1: Installing Dependencies
!pip install langchain faiss-cpu transformers pypdf
Step 2: Loading PDF Documents
from langchain.document_loaders import PyPDFLoader from langchain.vectorstores import FAISS from langchain.embeddings import HuggingFaceEmbeddings from transformers import AutoTokenizer, AutoModelForSeq2SeqLM # Load PDF documents pdf_path = "sample.pdf" # Replace with your file loader = PyPDFLoader(pdf_path) documents = loader.load()
Step 3: Creating Embeddings and Storing in FAISS
# Generate embeddings embedding_model = HuggingFaceEmbeddings() vector_store = FAISS.from_documents(documents, embedding_model)
Step 4: Implementing Retrieval Function
def retrieve_documents(query, k=3):
results = vector_store.similarity_search(query, k=k)
return [doc.page_content for doc in results]
Step 5: Generating Context-Aware Responses
# Load a transformer model for response generation
tokenizer = AutoTokenizer.from_pretrained("facebook/bart-large-cnn")
model = AutoModelForSeq2SeqLM.from_pretrained("facebook/bart-large-cnn")
def generate_response(query):
context = retrieve_documents(query)
input_text = query + "\n" + "\n".join(context)
inputs = tokenizer.encode(input_text, return_tensors="pt", max_length=512, truncation=True)
outputs = model.generate(inputs, max_length=50, num_beams=5, early_stopping=True)
return tokenizer.decode(outputs[0], skip_special_tokens=True)
# Example usage
query = "How does AI impact healthcare?"
response = generate_response(query)
print("Generated Response:", response)
Conclusion
CORAG introduces a paradigm shift in AI-driven knowledge retrieval by combining context-optimized retrieval, energy-efficient transformers, and self-improving feedback loops. It enables organizations to enhance accuracy, minimize costs, and ensure sustainable AI adoption.
Future Exploration
- Edge AI Integration: Deploying CORAG on low-power edge devices.
- Federated Learning: Enhancing privacy and efficiency through decentralized learning models.
- Cross-Domain Adaptation: Expanding CORAG into education, logistics, and smart city applications.
CORAG is set to transform information retrieval and response generation, offering a sustainable and efficient AI-driven knowledge ecosystem.
