Retro RAG represents a sophisticated version of standard RAG models by incorporating retroactive memory to enhance retrieval quality and improve context coherence in generated answers. Unlike traditional retrieval-augmented generation models, Retro RAG operates through a dynamic learning cycle that ensures retrieved information remains accurate and context-aware, drawing from trusted sources.

One of the key strengths of Retro RAG is its repetitive feedback mechanism, which refines document retrieval over time. This makes it an optimal solution for applications requiring deep comprehension and extended information storage. Fields such as legal research, healthcare institutions, customer support centers, and academic organizations benefit significantly from Retro RAG, as they require responses that are both reliable and contextually appropriate.
This paper explores Retro RAG in depth, covering its historical background, novel architecture, and practical applications. Additionally, it provides concrete examples and discusses its Python-based development framework. Readers will gain insights into how Retro RAG enhances retrieval accuracy, reduces hallucinations, and enables independent system learning while also understanding its implementation challenges and computational requirements.
1. How Does Retro RAG Work?
The adaptive memory component of Retro RAG enhances standard RAG systems by improving both retrieval operations and text generation methods. The main operational workflow of Retro RAG has three essential stages.
a. Retrieval Stage: The document retrieval process improves through Retro RAG since it updates retrieved content automatically as users modify their search criteria. The model uses self-attention mechanisms inside its retriever component to identify important documents. Key Innovations: The system performs memory updates that modify weights through past client interactions. The retriever model gains document ranking capabilities from implementing self-attention layers. The system allows users to improve retrieved content availability by implementing automatic document ranking systems.
b. Memory-Augmented Response Generation: The synthesis process gets an enhancement from Retro RAG through its ability to link the response generation with memory augmentation. The system maintains a strong connection between responses and both past dialogue actions and retrieved information. Key Innovations: The implementation of cross-attention-based knowledge fusion enables an automatic method to merge retrieved documents into the response generation process. Memory alignment techniques modify generation outputs through analysis of past dialogues and past interactions. The hallucination reduction strategies maintain responses within the boundaries of previously acquired facts.
c. Retroactive Feedback Loop: Retro RAG maintains an innovative feedback process which tailors retrieval methods through past response quality results. The mechanism optimizes retrieval queries automatically to enhance future document selection which aligns better with the current query context.
Key Innovations
- The system receives ongoing updates for its retrieval methods through user engagement in adaptive learning.
- Contextual memory embeddings refine document relevance over time. Self-supervised feedback systems optimize the accuracy level for future retrieval operations.
2. Why and When to Use Retro RAG?
Retro RAG (Retrieve and Generate) provides excellent results when applied to situations needing both high-context dependency and iterative learning functions alongside factual accuracy requirements. Wooden AI systems equipped with Retro RAG have the ability to enhance their response refinement through past interactions or information which suits complex evolving tasks that require contextual understanding and continuous insight integration.
The following applications match perfectly with the Retro RAG system design:
Use Cases
• Legal & Compliance Research
- Retro RAG proves advantageous in legal research that depends on accurate and consistent retrieval of entire past court decisions. Through this method the AI system generates legal documents which use the appropriate relevant case precedents to maintain uniformity throughout different rulings and interpretations.
- Retro RAG enables AI-powered legal assistants to enhance their responses through retrieval of applicable case law citations while adapting interpretations according to past legal judgments. Such systems undergo development throughout time by incorporating fresh case law while delivering increasing accurate data points that focus on current legal study requirements and specific compliance requirements.
• Healthcare Decision Support
- Healthcare practitioners rely on contemporary medical documents and procedural guidelines for decision-making, as these resources undergo continuous updates.
- Retro RAG enables systems to extract knowledge from past decisions and medical cases, ensuring precise recommendations aligned with the latest evidence.
- This methodology keeps clinical diagnostic tools and decision support systems both research-current and informed by historical patient data.
- Diagnostic systems leveraging AI in fields like radiology or oncology enhance their treatment suggestions by integrating both current medical research and past patient health outcomes.
- AI-driven systems analyze past patient histories alongside emerging research findings to refine and improve cancer treatment protocols.
• Customer Support Automation
- Quality customer support relies on continuous and accurate responses to prevent customer frustration and the spread of incorrect information.
- Retro RAG enables AI systems in customer service to learn from past client interactions, allowing them to generate responses that address current demands and emerging questions.
- The AI’s continual learning process helps it provide personalized and accurate support by absorbing knowledge from every user interaction.
- AI chatbots improve their responses over time by analyzing previous support ticket records and refining their answers accordingly.
- When a customer has previously received support for an issue, the system adjusts future interactions, tailoring responses for faster and more precise solutions.
• Research & Academia
- Research and academic work require the integration of multiple data sources to maintain data consistency and ensure factual accuracy in research outcomes.
- Retro RAG enables AI tools to process vast amounts of research material by connecting to past educational papers, books, and professional journals, leading to comprehensive analyses and novel insights.
- AI tools help researchers manage large datasets and document collections, especially when establishing logical relationships between different information sources.
- The process of compiling academic literature for synthesis becomes more efficient, as AI tools generate coherent and consistent merges of various academic articles.
- Academic researchers benefit from greater accuracy and efficiency in handling complex research questions, with AI-driven summary adjustments based on both current publications and existing research.
Advantages of Retro RAG
- Retrieval accuracy improves through continuous retrospective system updates, ensuring precise document selection for queries.
- This results in superior responsiveness, directly linked to the high relevance of retrieved information.
- Memory augmentation allows the model to store historical interactions, enabling responses that align with previously processed data.
- Multi-turn conversation applications benefit significantly from this approach, as the model retains context over extended dialogues.
- Retro RAG restricts response generation to retrieved knowledge, minimizing factual inaccuracies and preventing misleading content.
- An iterative feedback system enables Retro RAG to continuously refine its retrieval processes, achieving higher accuracy levels over time.
Challenges of Retro RAG
- The iterative retrieval, memory enhancement, and feedback process of Retro RAG requires significant computing resources to function efficiently.
- Deployment becomes challenging in resource-constrained environments due to Retro RAG’s high computational demands.
- Implementing Retro RAG models requires extensive domain-specific datasets and ongoing maintenance to sustain operational performance.
- Specialized expertise and cost-intensive resources are essential for successfully deploying Retro RAG systems.
- Real-time applications may face performance issues, as the feedback-based process introduces delays in retrieval and response generation.
- Due to these delays, Retro RAG is not ideal for time-sensitive tasks requiring instant decision-making.
3. Python Implementation of Retro RAG
The third section shows how to develop Retro RAG in Python through the combination of transformer models with FAISS retrieval.
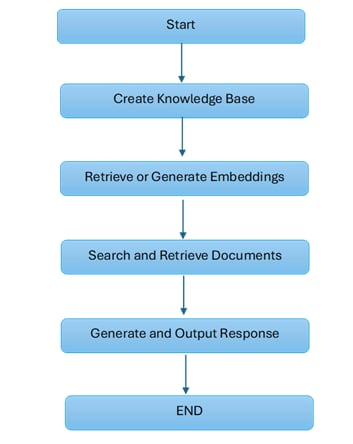
Step 1 Requires the creation of a Knowledge Base that uses Embeddings technology.
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
import faiss
import numpy as np
# Knowledge base with sample documents
documents = [
"Quantum computing enhances cryptographic security.",
"Artificial intelligence transforms healthcare analytics.",
"Renewable energy systems operate to decrease carbon footprints in the environment.",
"Machine learning systems achieve superior performance in detecting financial fraud in banking institutions."
]
# Function to generate embeddings
def create_embeddings(docs):
embeddings = np.random.rand(len(docs), 128) # Simulated embeddings
return embeddings
# Generate embeddings
embeddings = create_embeddings(documents)
# Initialize FAISS Index
index = faiss.IndexFlatL2(128)
index.add(embeddings)
Step 2 Retroactive Retrieval Mechanism.
# Retrieval with feedback loop
cache = {}
def retrieve(query, k=3):
query_embedding = np.random.rand(1, 128) # Placeholder for query embedding data
distances, indices = index.search(query_embedding, k)
return [documents[i] for i in indices[0]]
def retrieve_with_memory(query):
if query in cache:
return cache[query]
retrieved_docs = retrieve(query)
cache[query] = retrieved_docs # Store in memory
return retrieved_docs
Step3: Retroactive memory functions to generate responses
# Load tokenizer and model
tokenizer = AutoTokenizer.from_pretrained("facebook/bart-large-cnn")
generator = AutoModelForSeq2SeqLM.from_pretrained("facebook/bart-large-cnn")
def generate_response(query, context):
input_text = query + "\n" + "\n".join(context)
inputs = tokenizer.encode(input_text, return_tensors="pt", max_length=512, truncation=True)
outputs = generator.generate(inputs, max_length=50, num_beams=5, early_stopping=True)
return tokenizer.decode(outputs[0], skip_special_tokens=True)
# Example Query
query = "How AI's effects on healthcare practices?"
retrieved_docs = retrieve_with_memory(query)
response = generate_response(query, retrieved_docs)
print("Retrieved Documents:", retrieved_docs)
print("Generated Response:", response)
Conclusion
The traditional retrieval-augmented generation system improves through Retro RAG by adding an adaptive memory component that optimizes retrieval precision as well as it strengthens response organization and keeps generated information factually correct. High processing requirements aside Retro RAG provides critical capabilities that enable self-learning and automatic retrieval which make it indispensable for systems that need context-aware AI outputs.
