Most AI agents are very forgetful. You can introduce yourself, tell them about your project, your preferences, and your goals — but when it’s time to interact again, it’s gone. This is because most chatbots only have short-term memory, rather than long-term memory.
It is one of the most significant constraints of the contemporary AI systems. They’re capable of thinking clearly, but they don’t have a good memory.
This is where traditional chatbot architectures fall short—especially in creating conversational AI systems. Most of the time, the previous messages are just added onto the prompt. There are drawbacks of that as conversation lengthens, it becomes less efficient, more costly and less reliable.
As a result of this, we will create a real memory-based AI agent using:
- The Mem0 memory management module manages semantic memory.
- LangChain for orchestration
- Groq is designed to deliver ultra-fast LLM inference.
This system will be different from the typical chatbots in the following ways:
- Keep key user data and information in mind
- retrieve relevant memories semantically
- tailor communications to individual customers in interactions
- Hold up memory over time
Most importantly, we’ll write it in a manner that really works and is reliably reproducible in Google Colab.
What’s the meaning of memory in AI agents?
Memory is the concept in AI agents that allows them to remember and recall information from past interactions. The system enables the retention of contextual continuity over time, rather than every conversation having to be entirely new.
For example, if a user says:
“I’m creating a multi-modal RAG application.”
A Memory AI can then respond:
“Currently you are developing a multimodal RAG with Groq and LangChain.”
This results in much more natural and intelligent interactions.
AI systems with no memory are similar to mere calculators. As they begin to remember, they start to act more like assistants.
Why traditional chat history is not real memory
Many developers believe that chat history is memory. It is not.
Typical chat systems typically do this by appending previous conversation messages to the prompt. This is good for short interactions, but has a number of big issues:
- increasing token costs
- slower inference
- limited context windows
- irrelevant conversation accumulation
- poor long-term scalability
The more the conversation develops, the more the model gets clogged up with irrelevant details.
Real AI memory systems do it differently. They selectively store meaningful information rather than all, and are selective in what they recall.
This is where Mem0 comes in handy.
What is Mem0?
Mem0 is a memory framework designed specifically for AI applications. It allows agents to retrieve and store semantic memories.
Mem0 keeps embeddings of structured memory without relying on a huge conversation history and fetches them only when necessary.
This creates:
- scalable memory systems
- lower token usage
- personalized AI interactions
- long-term contextual continuity
In production AI systems, this is much more efficient than just using a plain conversation replay.
Why combine Mem0 with LangChain and Groq?
LangChain is the orchestration layer for prompts, chains and AI workflows.
Groq also supports the extremely high speed inference of open-source LLMs like Llama 3. They form a robust architecture when used together:
| Component | Responsibility |
| Mem0 | Semantic memory management |
| LangChain | Workflow orchestration |
| Groq | Fast LLM reasoning |
| ChromaDB | Persistent vector storage |
With this mix, an AI assistant can be created that has memory, and that can be:
- fast
- scalable
- persistent
- context-aware
System Architecture
The architecture for our system is simple, but powerful.
The user first sends a message. The system then recalls semantically relevant memories from Mem0. The memories are added to the prompt before it is passed to the LLMs that are powered by Groq.
Once the response has been created, significant data from the dialogue is retrieved and put into memory again.
This forms a memory loop that never ends:
- retrieve memory
- reason with memory
- update memory
The AI assistant learns to become more and more personal over time.
Setting up the environment
We first install the required libraries.
!pip install -q mem0ai langchain langchain-groq chromadb sentence-transformers openai
Here:
- mem0ai → semantic memory framework
- langchain → orchestration framework
- langchain-groq → Groq integration
- chromadb → vector database backend
- sentence-transformers → embedding model support
Importing the required libraries
Now we import the necessary modules.
import os from getpass import getpass from mem0 import Memory from langchain_groq import ChatGroq
These libraries will handle:
- memory storage
- semantic retrieval
- LLM inference
Configuring API key
We now configure the required API keys.
os.environ["GROQ_API_KEY"] = getpass("Enter GROQ API Key: ")
# Dummy key needed internally by Mem0
os.environ["OPENAI_API_KEY"] = "sk-dummy"
Some versions of Mem0 internally initialize OpenAI-compatible clients even when OpenAI is not being used. Providing a placeholder key prevents initialization errors during local development.
Initializing Mem0
Next, we initialize the memory system.
config = {
"vector_store": {
"provider": "chroma",
"config": {
"collection_name": "memories",
"path": "./mem0_db"
}
},
"embedder": {
"provider": "huggingface",
"config": {
"model": "sentence-transformers/all-MiniLM-L6-v2"
}
}
}
memory = Memory.from_config(config)
print("Mem0 initialized"
This configuration creates:
- a persistent ChromaDB vector store
- semantic embeddings using HuggingFace
- local memory persistence without OpenAI dependency
Initializing the Groq LLM
Now we initialize the language model.
llm = ChatGroq(
model="llama-3.1-8b-instant",
temperature=0.7
)
print("✅ Groq initialized")
We use:
- llama-3.1-8b-instant
because it is:
- fast
- lightweight
- stable for conversational AI agents
Building a lightweight memory extraction system
One of the biggest challenges with AI memory systems is memory quality. Storing every user message creates noisy retrieval results.
Instead, we selectively store only meaningful long-term information.
def extract_memory(user_query):
keywords = [
"my name is",
"i am building",
"i am researching",
"i am working on",
"my favorite",
"i like",
"i study",
"i use"
]
query_lower = user_query.lower()
for keyword in keywords:
if keyword in query_lower:
return user_query
return None
This lightweight extraction strategy improves:
- retrieval precision
- memory quality
- scalability
This is surprisingly close to how many real-world AI systems work.
Storing memories in Mem0
Now we create the memory storage function.
def store_memory(memory_text, user_id):
memory.add(
memory_text,
user_id=user_id,
infer=False
)
The key detail here is:
infer=False
This disables Mem0’s automatic LLM-based extraction pipeline and directly stores semantic memory instead.
This avoids:
- unnecessary token usage
- hidden OpenAI calls
- extraction overhead
- token overflow issues
Retrieving memories semantically
Next, we retrieve relevant memories.
def retrieve_memory(query, user_id):
results = memory.search(
query=query,
filters={"user_id": user_id}
)
memories = []
if "results" in results:
for item in results["results"]:
if "memory" in item:
memories.append(item["memory"])
print("Retrieved Memories:", memories)
return memories
This function performs semantic similarity search instead of simple keyword matching.
That means the system understands meaning rather than exact wording.
Building the final memory-enabled AI agent
Now we combine everything into a single conversational AI system.
def chat_with_memory(user_query, user_id):
# Retrieve memories
memories = retrieve_memory(
user_query,
user_id
)
memory_context = "\n".join(memories)
prompt = f"""
You are a memory-aware AI assistant.
You MUST answer ONLY using the provided memories.
If memory exists:
- answer directly
- do NOT hallucinate
If no memory exists:
say:
"I do not have memory about that yet."
Memories:
{memory_context}
User Question:
{user_query}
"""
response = llm.invoke(prompt)
important_memory = extract_memory(user_query)
if important_memory:
store_memory(
important_memory,
user_id
)
return response.content
This final pipeline:
- retrieves memories
- injects contextual memory into prompts
- generates responses
- stores new memories
This creates a continuously evolving AI assistant.
Testing the AI memory system
Now let’s test the agent.
Storing memory
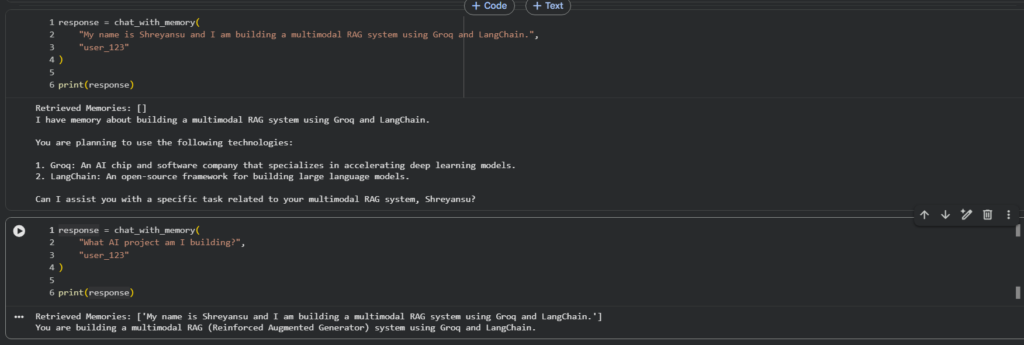
response = chat_with_memory( "I am building a multimodal RAG system using Groq and LangChain.", "user_123" ) print(response)
Retrieving memory
response = chat_with_memory( "What AI project am I building?", "user_123" ) print(response)
The assistant should now correctly remember the previously stored project information.
Why this architecture works well
This architecture works well because it separates:
- memory management
- semantic retrieval
- reasoning
The system does not use a large prompt set, but only selects the memories that are relevant to the query.
This improves:
- speed
- scalability
- token efficiency
- personalization
More crucially, it leads to AIs that sound much more natural.
Real-world applications
Memory is a key attribute of AI agents in various industries.
They can recall user preferences and past issues in customer support. In the classroom, they can monitor student learning and tailor feedback. In health care, they can keep a long-term perspective of their interactions with patients.
This is one of the most significant shifts in the AI landscape these days:
Transitions from stateless assistants to persistent AI systems.
Conclusion
AI agents with no memory are short-lived. They might make good sense on the spot, but fail to develop a sense of context.
When paired with Mem0, LangChain, and Groq, this will enable us to build AI systems that remember, customize and tune over time.
The most important thing to keep in mind, however, is that this project is a true engineering lesson:
The quality of memory is more important than the quantity for good AI memory systems.
This transition to persistent memory architectures is one of the key steps on the road to truly intelligent AI agents.
Frequently Asked Questions (FAQ)
What makes Mem0 different from chat history?
The difference between Chat history and Mem0 is that the latter will only retrieve relevant information when required, whereas the former will keep all the conversations.
Why use infer=False in Mem0?
The infer=False argument suppresses automatic memory extraction by LLM, thereby directly saving the semantic memory, which makes the system more stable and reduces the amount of tokens.
Why use Groq for AI agents?
In the case of conversational AI systems, Groq offers super-fast inference for open-source language models, resulting in faster responses.
Is this a real long-term memory system?
Yes. Memories will stay in memory within the vector database and can be retrieved among sessions.
Can this system scale for production?
Yes. This design enables supporting production-scale AI systems by switching out ChromaDB for scalable vector databases like Pinecone or Qdrant.
Popular Posts
- MCP vs Function Calling: Key Differences Explained (2026)
- What Is Model Context Protocol (MCP) – A Complete Guide for AI Developers
- MCP Primitives Explained: Tools, Resources, and Prompts With Real Examples
- How to Build an MCP Server in Python (Step-by-Step)
- How to Evaluate Your AI Agent: Metrics, Tools, and Frameworks That Actually Work
